Go Along, Get Along
This is a somewhat complicated topic. There’s not a great TL;DR here, but I don’t want anyone to walk away from this post thinking that parallelism or indexes are “bad”.
What I do want to show is how uneven parallelism can exacerbate existing plan quality issues, and how some indexing can be unhelpful.
Query The First
This is the query we’ll be working with.
SELECT u.Id, u.DisplayName, u.Reputation, ca.*
FROM dbo.Users AS u WITH
CROSS APPLY ( SELECT c.*,
ROW_NUMBER()
OVER ( PARTITION BY c.PostId
ORDER BY c.Score DESC ) AS PostScoreRank
FROM dbo.Comments AS c
WHERE u.Id = c.UserId
AND c.Score > 0 ) AS ca
WHERE u.Reputation >= 100000
AND ca.PostScoreRank < 1
ORDER BY u.Reputation DESC
OPTION(RECOMPILE);
I’m using cross apply because the optimizer is likely to pick a Nested Loops join plan. These plans are unlikely to see a Redistribute Streams on the inner side of the join.
Within the apply, I’m making SQL Server do a more significant amount of work than outside of it. This will make more sense later on.
Outside of the apply, I’m doing a little bit of work against a few columns in the Users table, columns that would probably make good candidates for indexing.
The index that I currently have on the Comments table looks like this:
CREATE INDEX kerplop
ON dbo.Comments(UserId, PostId, Score DESC)
WHERE Score > 0
Anyway, the query plan for this run looks like this:
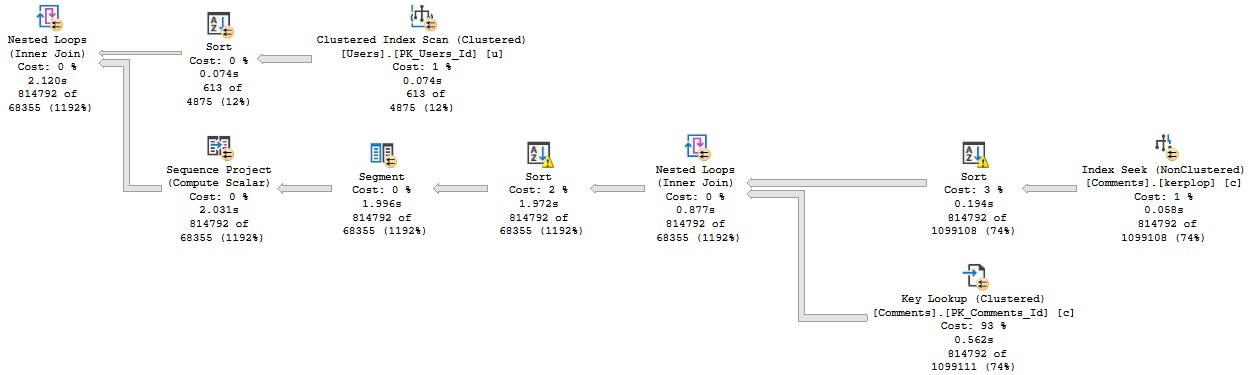
The part I want to focus on are the spills.
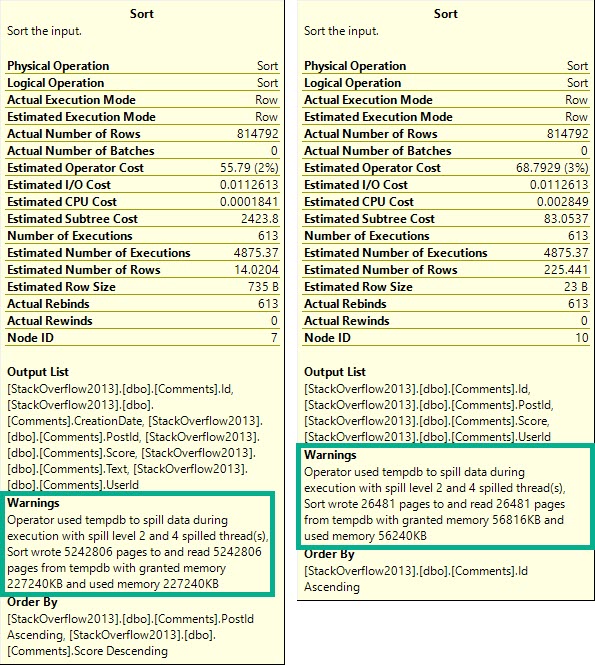
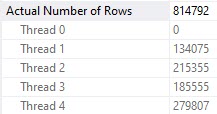
What you should keep in mind is that while all 4 threads spill, they all spill pretty evenly.
Thread distribution is pretty good across parallel workers. Not perfect, but hey.
If you want perfect, go be disappointed in what you get for $47k per .75 cores of Oracle Enterprise Edition.
Query The Second
Knowing what we know about stuff, we may wanna add this index:
CREATE UNIQUE INDEX hey_scully
ON dbo.Users (Id, Reputation DESC)
INCLUDE(DisplayName);
But when we do, performance gets much worse.
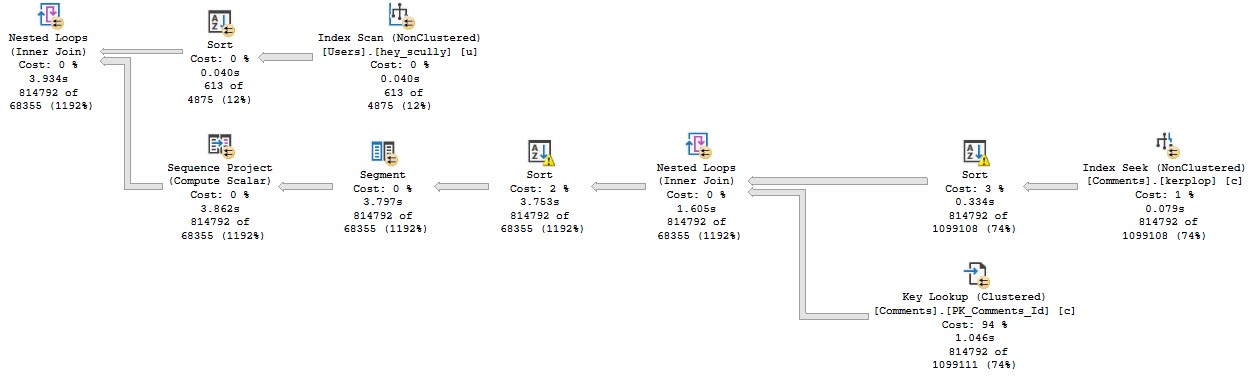
Zooming back in on the Sorts…
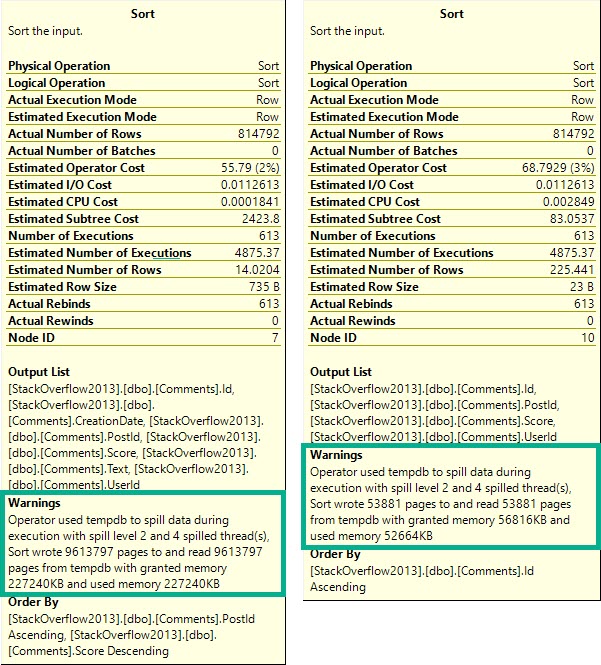
Each spill was about ~2x as bad, because thread distribution got much worse.
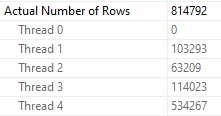
Poor thread 4 got stuck with ~534k rows. The problem here is that each thread in a parallel plan gets an even cut of the memory grant. That doesn’t rebalance if parallelism is skewed. Threads may rebalance if a Redistribute Streams operator appears, but we don’t have one of those here. We will sometimes get one on the outer side of nested loops joins, if the optimizer decides it’s needed.
But since we don’t, things get all screwy.
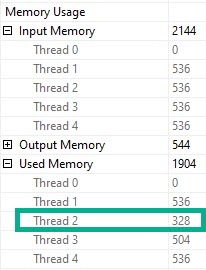
Thread 2, which had only 63k rows assigned to it didn’t use the full amount of memory it got, though it still apparently spilled. Same with thread 3, but to a lesser extent (get it?).
But why did this happen when we added an index?
Paper Boy
Reading the plan from right to left, top to bottom, we start with a scan of the Users table. This is when something called the parallel page supplier kicks in and starts handing out rows as threads ask for them. Its job is to make sure that parallel workers get rows when they ask for them, and that different threads don’t get the same rows. To do that, it uses key ranges from the statistics histogram.
It makes for a rather dull screenshot, but both histograms are identical for the clustered and nonclustered indexes in this demo. It’s not a statistical issue.
Nor are indexes fragmented, so, like, don’t get me started.
According to my Dear Friend, the parallel page supplier aims for 64k chunks. The smaller index just happens to end up with a more unfortunate key range distribution across its fewer pages.

What About A Different Index?
Let’s switch our indexes up and add this one:
CREATE UNIQUE INDEX spooky_mulder
ON dbo.Users (Reputation DESC, Id)
INCLUDE(DisplayName);
The plan no longer goes parallel, and it runs for about 4 seconds.
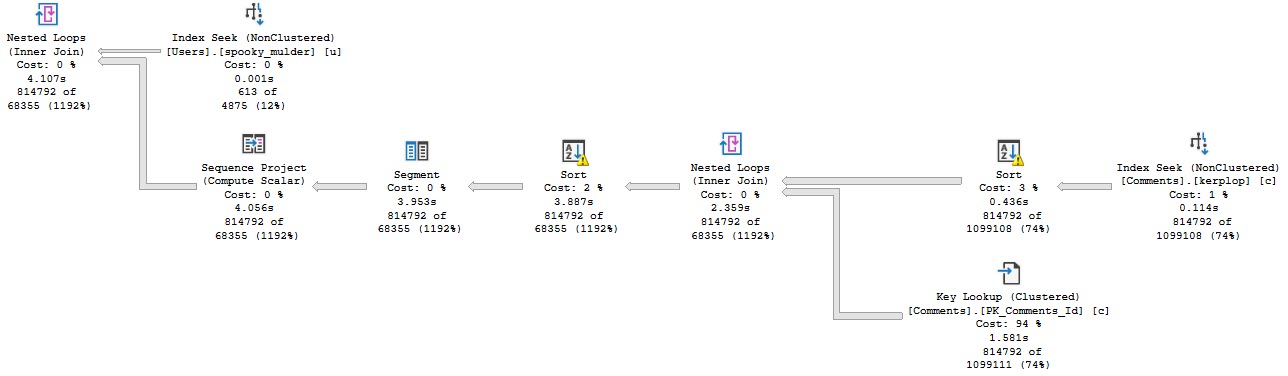
We’re doing the same amount of work on the inner side of the nested loops join. The only part of the plan that changed is on the outer side.
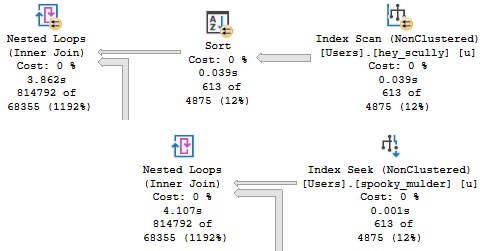
This is more of an aside than anything, but in parallel nested loops plans, the optimizer only considers if parallelism will reduce the cost of the outer side of the join.
The plan changing to use a cheaper seek with no need to sort data means the outer side is rather cheap to execute, but the inner side is just as expensive.
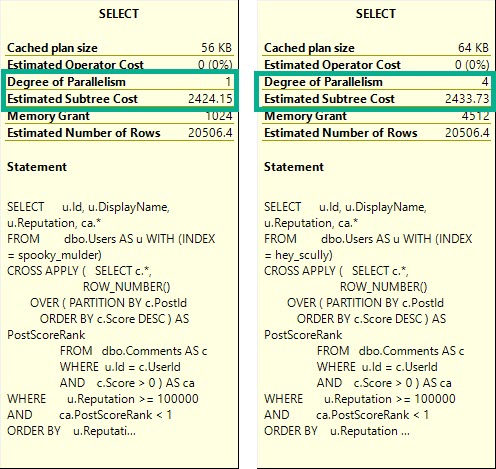
The DOP 1 plan is only slightly cheaper, here. You may expect a plan that “costs” this much to go parallel, but alas, it was not meant to be.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Why the ca.PostScoreRank < 1 in the WHERE clause? Won't this always return false?
Yeah, the point is to not return a bunch of rows and wait around for that, but still do all the work needed to generate the row numbers.