If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
I have never once seen anyone use these. The most glaring issue with them is that unlike a lot of other directives in SQL, these ones just don’t do a good job of telling you what they do, and their behavior is sort of weird.
Unlike EXISTS and NOT EXISTS, which state their case very plainly, as do UNION and UNION ALL, figuring these out is not the most straightforward thing. Especially since INTERSECT has operator precedence rules that many other directives do not.
INTERSECT gives you a set of unique rows from both queries
EXCEPT gives you a set of unique rows from the “first” query
So, cool, if you know you want a unique set of rows from somewhere, these are good places to start.
What’s better, is that they handle NULL values without a lot of overly-protective syntax with ISNULL, COALESCE, or expansive and confusing OR logic.
The tricky part is spotting when you should use these things, and how to write a query that makes the most of them.
And in what order.
Easy Examples
Often the best way to get a feel for how things work is to run simple queries and test the results vs. your expectations, whatever they may be.
I like these queries, because the UserId column in the Comments table is not only NULLable, but contains actual NULLs. Wild, right?
SELECT
c.*
FROM dbo.Comments AS c
WHERE c.UserId IS NULL
AND c.Score > 2
INTERSECT
SELECT
c.*
FROM dbo.Comments AS c
WHERE c.UserId IS NULL
AND c.Score > 3
ORDER BY
c.Score;
Running this will return results where a Comment’s Score is greater than 3 only, because that’s the starting point for where both query results begin to match results across all the columns.
Note that the UserId column being NULL doesn’t pose any problems here, and doesn’t require any special handling. Like I said. And will keep saying. Please remember what I say, I beg of you.
Moving on to EXCEPT:
SELECT
c.*
FROM dbo.Comments AS c
WHERE c.UserId IS NULL
AND c.Score > 2
EXCEPT
SELECT
c.*
FROM dbo.Comments AS c
WHERE c.UserId IS NULL
AND c.Score > 3
ORDER BY
c.Score;
This will only return results from the “first” query (often referred to as the left, or outer query) with a Score of 3, because that’s the only data that exists in it that isn’t also in the “second” (or right, or inner) query.
Both queries will find many of the same rows after Score hits 2 or 3, but those get filtered out to show only the difference(s) between the two.
In case it wasn’t obvious, it’s a bit like using NOT EXISTS, in that rows are only checked, and not projected from the second/right/inner query, looking for Scores greater than 3.
Again, NULLs in the UserId column are handled just fine. No ISNULL/COALESCE/OR gymnastics required.
While no database platform adheres strictly or urgently to ANSI standards, waiting 20 years for an implementation in SQL Server is kind of really-extra-super-duper son-of-a-gun boy-howdy dag-nabbit-buster alright-bucko hold-your-horses listen-here-pal levels of irritating.
Think of all the useless, deprecated, and retired things we’ve gotten in the past 20 years instead of basic functionality. It’s infinitely miffing.
Anyway, I like these additions quite a lot. In many ways, these are extensions of INTERSECT and EXCEPT, because the workarounds involved for them involved those very directives. Sort of like Microsoft finally adding GREATEST and LEAST, after decades of developers wondering just what the hell to do instead, I hope they didn’t show up too late to keep SQL Server from being bullied by developers who are used to other platforms.
We can finally start to replace mutton-headed, ill-performing syntax like this:
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON u.Id = p.LastEditorUserId
OR (p.LastEditorUserId IS NULL);
With stuff that doesn’t suck, like this:
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON u.Id IS NOT DISTINCT FROM p.LastEditorUserId;
The query plan timings tell enough of a story here:
i’ve been waiting for so long
But not everyone is able to use the latest and greatest (or least and greatest, ha ha ha) syntax. And the newest syntax isn’t always better for performance, without additional tweaks.
And that’s okay with me. I do performance tuning for a living, and my job is to know all the available options and test them.
Like here. Like now.
The Only One I Know
Let’s compare these two queries. It’ll be fun, and if you don’t think it’s fun, that’s why you’ll pay me. Hopefully.
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON u.Id IS NOT DISTINCT FROM p.LastEditorUserId;
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON u.Id = p.LastEditorUserId
WHERE EXISTS
(
SELECT p.LastEditorUserId FROM dbo.Posts AS p
INTERSECT
SELECT u.Id FROM dbo.Users AS u
);
Here’s the supporting index that I have for these queries:
CREATE INDEX
LastEditorUserId
ON dbo.Posts
(LastEditorUserId)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
It’s good enough. That’s what counts, I guess. Showing up.
20th Century Boy
At first glance, many queries may appear to be quite astoundingly better. SQL Server has many tricks up its sleeves in newer versions, assuming that you’re ready to embrace higher compatibility levels, and pay through the nose for Enterprise Edition.
This is a great example. Looking at the final query timing, you might think that the new IS [NOT] DISTINCT FROM syntax is a real dumb dumb head.
gimme a second
But unless you’re invested in examining these types of things, you’ll miss subtle query plan difference, which is why you’ll pay me, hopefully,
The second query receives the blessing of Batch Mode On Row Store, while the first does not. If we use the a helper object to get them both functioning on even terms, performance is quite close:
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON u.Id IS NOT DISTINCT FROM p.LastEditorUserId
LEFT JOIN dbo.columnstore_helper AS ch
ON 1 = 0;
i guess that’s okay
In this case, the slightly tweaked query just slightly edges out the older version of writing the query.
I Can’t Imagine The World Without Me
There are many ways to write a query, and examine the performance characteristics. As SQL Server adds more options, syntax, capabilities, and considerations, testing and judging them all (especially with various indexing strategies) becomes quite an endeavor.
I don’t blame developers for being unaware or, or unable to test a variety of different rewrites and scenarios. The level of understanding that it takes to tune many queries extends quite beyond common knowledge or sense.
The aim of these posts is to give developers a wider array of techniques, and a better understanding of what works and why, while exposing them to newer options available as upgrade cycles march bravely into the future.
Keeping up with SQL Server isn’t exactly a full time job. Things are changed and added from release to release, which are years apart.
But quite often I find companies full of people struggling to understand basic concepts, troubleshooting, and remediations that are nearly as old as patches for Y2K bugs.
My rates are reasonable, etc.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
UNION and UNION ALL seem to get used with the same lack of discretion and testing as several other things in T-SQL: CTEs vs temp tables, temp tables vs. table variables, etc.
There are many times I’ve seen developers use UNION when result sets have no chance of being non-unique anyway, and many times I’ve seen them use UNION ALL when there would be a great benefit to discarding unnecessary duplicates.
Even worse is when the whole query is written incorrectly in the first place, and both DISTINCT and UNION are dumped all over queries to account for unwanted results across the board.
For example, someone may test a query in isolation, decide that DISTINCT needs to be applied to that result set, and then use UNION when appending another set of results to the final query. Throw in the typical slew of NOLOCK hints and one is left to wonder if anyone even understands what correct output might look like at all.
The answer to most questions about the correct way to write a query of course hinge on the quality of the underlying data, and any observed flaws reported by end users or QA testers.
This all becomes quite difficult to wade through, because developers may understand the correct logic, but not the correct way to implement it.
Just An Onion
To start, let’s flesh out what each operator means in the most basic way.
Using a nifty SQL Server 2022 function, and the power of batch separator loops, we’re going to load the numbers 1-2 into two tables, twice.
CREATE TABLE
#t1
(
i integer
);
INSERT
#t1 (i)
SELECT
gs.*
FROM GENERATE_SERIES(1, 5) AS gs;
GO 2
CREATE TABLE
#t2
(
i integer
);
INSERT
#t2 (i)
SELECT
gs.*
FROM GENERATE_SERIES(1, 6) AS gs;
GO 2
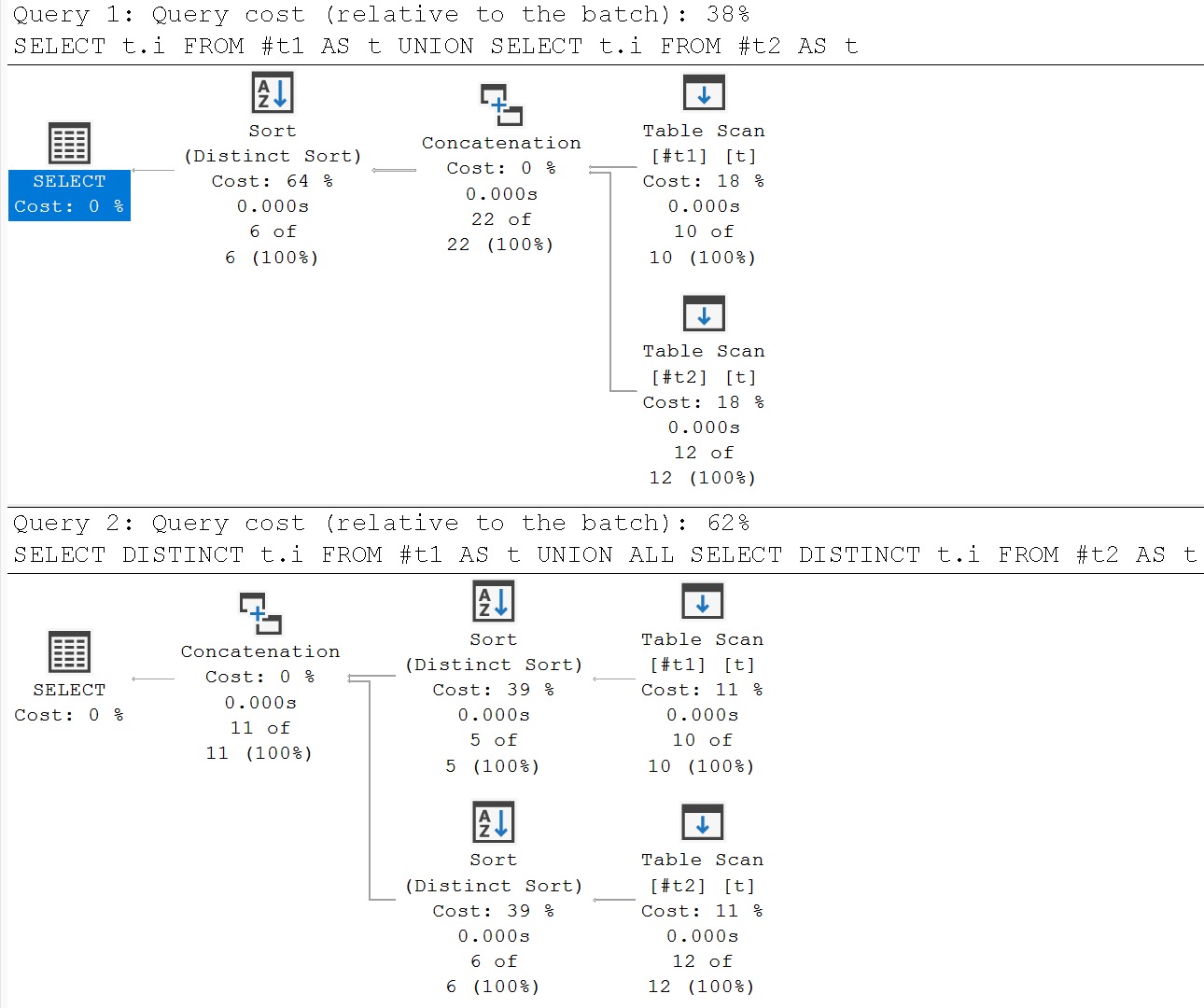
Doing this will provide a unique set of the numbers 1-6 from both temporary tables.
SELECT
t.i
FROM #t1 AS t
UNION
SELECT
t.i
FROM #t2 AS t;
Which is not logically equivalent to doing this:
SELECT DISTINCT
t.i
FROM #t1 AS t
UNION ALL
SELECT DISTINCT
t.i
FROM #t2 AS t;
The first query will not only deduplicate rows within each query, but also in the final result.
The second query will only deduplicate results from each query, but not from the final result.
To avoid playing word games with you, the first query will return the numbers 1-6 only once, and the second query will return 1-5 once, and 1-6 once.
Some additional sense can be made of the situation by looking at the query plans, and where the distinctness is applied.
soon
To put things plainly: if you’re already using UNION to bring to results together, there’s not a lot of sense in adding DISTINCT to each query.
Precedence, etc.
To better understand how UNION and UNION ALL are applied, I’d encourage you to use this simple example:
/*Changing these to UNION makes no difference*/
SELECT 1
UNION ALL
SELECT 2
UNION ALL
SELECT 3
/*Changing these to UNION makes a difference*/
UNION ALL
SELECT 1
UNION ALL
SELECT 2
UNION ALL
SELECT 3;
Specifically, look at the actual execution plans for these as you quote out ALL from the lines below the second comment.
You may even be surprised by what comes back when you get to the final UNION-ed select!
Orthodoxy
There has been quite a bit of performance debate about UNION and UNION ALL. Obviously, using UNION incurs some overhead to deduplicate results.
When you need it for result correctness, I’d encourage you to think about a few things:
The number of columns you’re selecting
The data types of the columns you’re selecting
What data actually identifies a unique row
I’ve come across many queries that were selecting quite a long list of columns, with lots of string data involved, that did a whole lot better using windowing functions over one, or a limited number of columns, with more manageable data types, to produce the desired results.
Here is a somewhat undramatic example:
DROP TABLE IF EXISTS
#u1;
SELECT
c.CreationDate,
c.PostId,
c.Score,
c.Text,
c.UserId
INTO #u1
FROM dbo.Comments AS c
WHERE c.Score IN (2, 9, 10)
AND c.UserId IS NOT NULL
UNION
SELECT
c.CreationDate,
c.PostId,
c.Score,
c.Text,
c.UserId
FROM dbo.Comments AS c
WHERE c.Score IN (3, 9, 10)
AND c.UserId IS NOT NULL;
DROP TABLE IF EXISTS
#u2;
SELECT
y.CreationDate,
y.PostId,
y.Score,
y.Text,
y.UserId
INTO #u2
FROM
(
SELECT
x.*,
n =
ROW_NUMBER() OVER
(
PARTITION BY
x.UserId,
x.Score,
x.CreationDate,
x.PostId
ORDER BY
x.UserId,
x.Score,
x.CreationDate,
x.PostId
)
FROM
(
SELECT
c.CreationDate,
c.PostId,
c.Score,
c.Text,
c.UserId
FROM dbo.Comments AS c
WHERE c.Score IN (2, 9, 10)
AND c.UserId IS NOT NULL
UNION ALL
SELECT
c.CreationDate,
c.PostId,
c.Score,
c.Text,
c.UserId
FROM dbo.Comments AS c
WHERE c.Score IN (3, 9, 10)
AND c.UserId IS NOT NULL
) AS x
) AS y
WHERE y.n = 1;
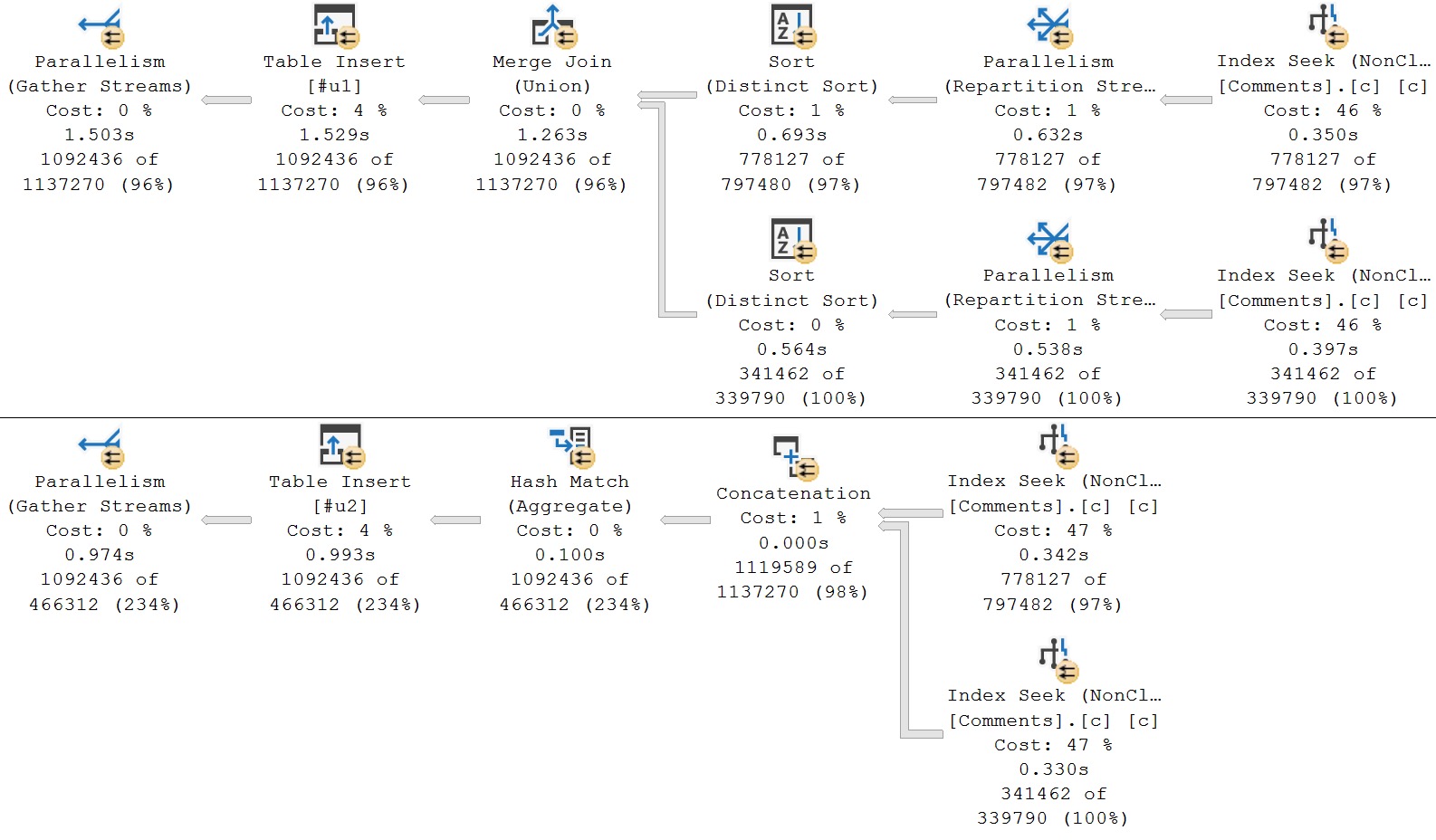
In the first query, we’re doing a straight union of all the columns in the Comments table, which includes the Text column (nvarchar 700).
In the second query, the UNION has been replaced by UNION ALL, and I’m using ROW_NUMBER on the non-text columns, and filtering to only the first result.
Here are the query plans:
wild times
If you’re looking at the second query plan and wondering why you’re not seeing the usual traces of windowing functions (window aggregates, or segment and sequence project, a filter operator to get n = 1), I’d highly suggest reading Undocumented Query Plans: The ANY Aggregate.
Like I said, this is a somewhat undramatic example. It only shaves about 500ms off the execution time, though that is technically about 30% faster in this scenario. It’s a good technique to keep in mind.
The index in place for these queries has this definition:
CREATE INDEX
c
ON dbo.Comments
(UserId, Score, CreationDate, PostId)
INCLUDE
(Text)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
Is UNION Ever Better Than UNION ALL?
There have been a number of times when producing distinct results has improved things rather dramatically, but there are a couple general characteristics they all shared:
Producing unique rows, either via UNION or DISTINCT is not prohibitively time consuming
The source being unique-ified feeds into an operation that is time consuming
Here’s an example:
CREATE INDEX
not_badges
ON dbo.Badges
(Name, UserId)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
CREATE INDEX
not_posts
ON dbo.Posts
(OwnerUserId)
INCLUDE
(Score, PostTypeId)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
GO
DROP TABLE IF EXISTS
#waypops;
CREATE TABLE
#waypops
(
UserId integer NOT NULL
);
INSERT
#waypops WITH(TABLOCKX)
(
UserId
)
SELECT
b.UserId
FROM dbo.Badges AS b
WHERE b.Name IN
(
N'Popular Question', N'Notable Question',
N'Nice Question', N'Good Question',
N'Famous Question', N'Favorite Question',
N'Great Question', N'Stellar Question',
N'Nice Answer', N'Good Answer', N'Great Answer'
);
SELECT
wp.UserId,
SummerHereSummerThere =
SUM(ca.Score)
FROM #waypops AS wp
CROSS APPLY
(
SELECT
u.Score,
ScoreOrder =
ROW_NUMBER() OVER
(
ORDER BY
u.Score DESC
)
FROM
(
SELECT
p.Score,
p.OwnerUserId
FROM dbo.Posts AS p
WHERE p.OwnerUserId = wp.UserId
AND p.PostTypeId = 1
UNION /*ALL*/
SELECT
p.Score,
p.OwnerUserId
FROM dbo.Posts AS p
WHERE p.OwnerUserId = wp.UserId
AND p.PostTypeId = 2
) AS u
) AS ca
WHERE ca.ScoreOrder = 0
GROUP BY
wp.UserId
ORDER BY
wp.UserId;
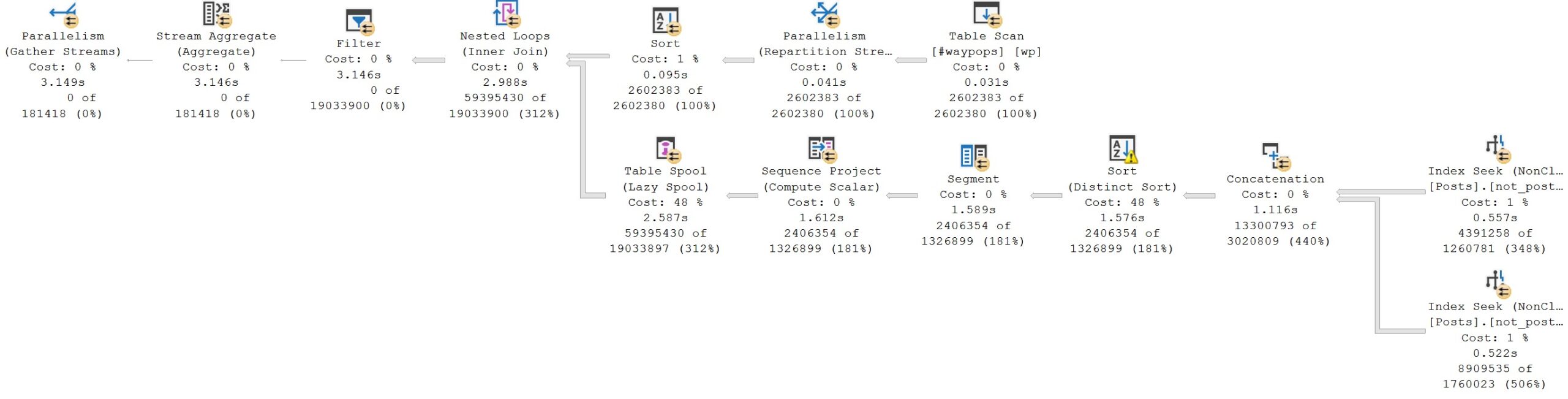
Executing this query as UNION-ed results gives us a query that finishes in about 3 seconds.
not bad!
Note that the Distinct Sort operator chosen to implement the desired results of the UNION reduces the rows from 13,300,793 to 2,406,354. This is especially important when Lazy Table Spools are involved.
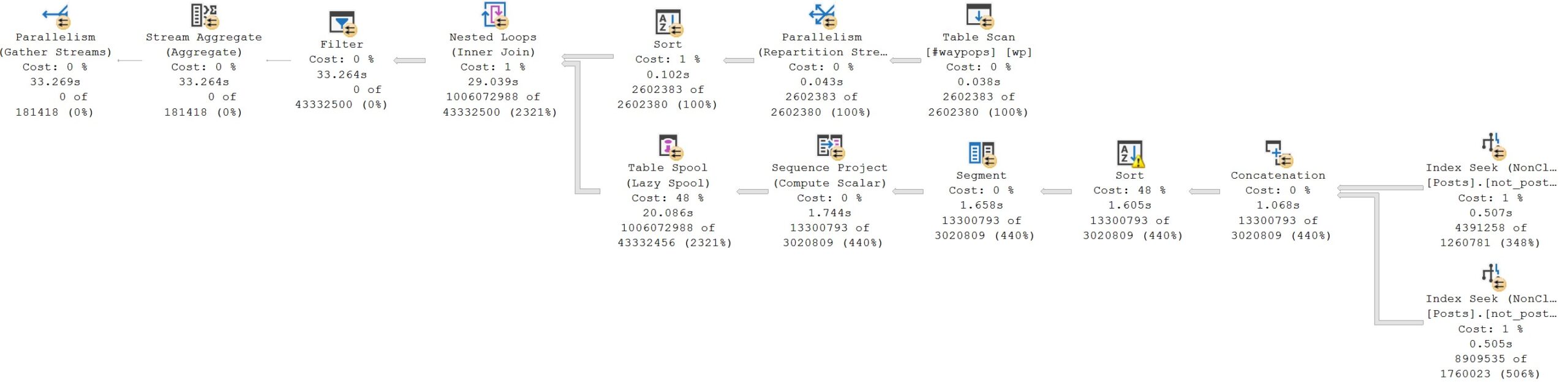
Here’s the query plan when it’s executed with UNION ALL:
bad!
Execution time goes from 3 seconds to 33 seconds. You may notice that the numbers on the inner side of the nested loops join are much larger across the plan, and that the Lazy Table Spool goes from about 900ms (2.587 seconds minus 1.612 seconds) to taking about 18 seconds (20 seconds minus 1.7 seconds). The Nested Loops Join also suffers rather dramatically, taking nearly 9 seconds, instead of the original 300ms, largely owing to the fact that it has to deal with 946,677,558 additional rows.
You’d suffer, too. Mightily.
Championship Belt
Choosing between UNION and UNION ALL is of course primarily driven by logical query correctness, but you should fully consider which columns actually identify a unique row for your query.
There are sometimes better ways of identifying uniqueness than comparing every single column being selected out in the final result set.
When you run into slow queries that are using UNION and UNION ALL, it’s usually worth investigating the overall usage, and if using one over the other gives you better performance along with correct results.
Where UNION can be particularly troublesome:
You’re selecting a lot of columns (especially strings)
You’re attempting to deduplicating many rows
You’re not working with a primary key
You’re not working with useful supporting indexes
Where UNION ALL can be particularly troublesome:
You’re selecting a lot of rows, and many duplicates exist in it
You’re sending those results into other operations, like joins (particularly nested loops)
You’re doing something computationally expensive on the results of the UNION ALL
Keep in mind that using UNION/UNION ALL is a generally better practice than writing some monolithic query with endless OR conditions in it.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Whether you want to be the next great query tuning wizard, or you just need to learn how to start solving tough business problems at work, you need a solid understanding of not only what makes things fast, but also what makes them slow.
I work with consulting clients worldwide fixing complex SQL Server performance problems. I want to teach you how to do the same thing using the same troubleshooting tools and techniques I do.
I’m going to crack open my bag of tricks and show you exactly how I find which queries to tune, indexes to add, and changes to make. In this day long session, you’re going to learn about hardware, query rewrites that work, effective index design patterns, and more.
Before you get to the cutting edge, you need to have a good foundation. I’m going to teach you how to find and fix performance problems with confidence.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Fixing Parallel Row Skew With TOP In SQL Server (With A Brief Re-Complaint About CXCONSUMER Waits)
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
A Little About SOS_SCHEDULER_YIELD Waits In SQL Server
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Views get a somewhat bad rap from performance tuners, but… It’s not because views are inherently bad. It’s just that we’ve seen things. Horrible things.
Attack ships on fire off the shoulder of Orion… I watched sea-beams glitter in the dark near the Tannhäuser Gate. All those moments will be lost in time, like tears in rain…
The problem is really the stuff that people stick into views. They’re sort of like a junk drawer for data. Someone builds a view that returns a correct set of results, which becomes a source of truth. Then someone else comes along and uses that view in another view, because they know it returns the correct results, and so on and so on. Worse, views tend to do a bunch of data massaging, left joining and coalescing and substringing and replacing and case expressioning and converting things to other things. The bottom line is that views are as bad as you make them.
The end result is a trash monster with a query plan that can only be viewed in full from deep space.
When critical processes start to rely on these views, things inevitably slow to a crawl.
I’ve said all that about views to say that the exact same problem can happen with inline table valued functions. I worked with a client last year who (smartly) started getting away from scalar and multi-statement functions, but the end results were many, many layers of nested inline functions.
Performance wasn’t great. It wasn’t worse, but it was nothing to gloat and beam over.
The Case For Views
Really, the main reason to use a view over an inline table valued function is the potential for turning it into an indexed view. If Microsoft would put an ounce of effort into making indexed views more useful and usable, it would loom a bit larger.
There are some niche reasons too, like some query generation applications use metadata discovery to build dynamic queries that can’t “see” into inline table valued functions the way they can with views, but I try not to get bogged down in tool-specific requirements like that without good reason.
Both views and inline table valued functions offer schemabinding as a creation option. This, among other incantations, are necessary if you’re going to follow the indexed view path.
But, here we find ourselves at the end of the case for views. Perhaps I’m not digging deep enough, but I can’t find much realistic upside.
While doing some research for this, I read through the CREATE VIEW documentation to see if I was missing anything. I was a bit surprised by this, but don’t see it as a great reason to use them:
CHECK OPTION
Forces all data modification statements executed against the view to follow the criteria set within select_statement. When a row is modified through a view, the WITH CHECK OPTION makes sure the data remains visible through the view after the modification is committed.
If you’re into that sort of thing, perhaps this will make views more appealing to you. I’m not sure I can think of why I’d want this to happen, but 🤷♂️
The Case For Inline Functions
Now that we’re squared away on views, and we’ve made sure we’re starting with the understanding that either of these module types can be lousy for performance if you put a lousy query in them, and fail to create useful indexes for those queries to access data efficiently.
What would sway my heart of stone towards the humble inline table valued function?
Parameters.
Views can’t be created in a way to pass parameter directly to them. This can be a huge performance win under the right conditions, especially because if you use cross or outer apply to integrate an inline table valued function into your query. You can pass table columns directly in to the function as parameter values. Inline table valued functions take the ick away.
You know how with stored procedures, if you want to use one to process multiple rows from a table, the most workable approach is to use a loop or cursor to assign row values to parameters, and then execute the procedure with them?
Just an example, if you had a stored procedure to take (to make it simple, full) backups, it would be handy to be able to do something like this:
EXEC dbo.TakeAFullBackup
@DatabaseName AS
SELECT
d.name
FROM sys.databases AS d
WHERE d.database_id > 4;
But no, we have to write procedural code to get a list of database names, loop through them, and execute the procedure for each one (or some other close-enough approximation).
Kinda lame, SQL Server. Kinda lame.
Rat Race
When I first came across this oddity, I probably thought (and wrote) things like: “though this is a rare occurrence in views…”
Time has tried that line of thinking and found it wanting. I’ve seen this happen many, many times over now. It’s funny, the more things you learn that can go wrong in a query plan, the more things you become quite paranoid about. The mental checklist is astounding.
Let’s start, as we often do, with an index:
CREATE INDEX
p
ON dbo.Posts
(OwnerUserId, Score DESC)
INCLUDE
(CreationDate, LastActivityDate)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
Now, before we move on, it’s worth noting that this issue is fixed under certain conditions:
I’m not sure which CU this fix was released for in SQL Server 2019, it’s not in any that I can find easily
You’re on SQL Server 2022 and using compatibility level 160
From my testing, it doesn’t matter which compatibility level you’re in on SQL Server 2017 or 2019, as long as optimizer hot fixes are enabled.
/*Using a database scoped configuration*/
ALTER DATABASE SCOPED CONFIGURATION
SET QUERY_OPTIMIZER_HOTFIXES = ON;
/*Using a trace flag instead*/
DBCC TRACEON(4199, -1);
/*SQL Server 2022+ only*/
ALTER DATABASE StackOverflow2013
SET COMPATIBILITY_LEVEL = 160;
For our purposes, we’ll be using SQL Server 2022 in compatibility level 150, with query optimizer hot fixes disabled.
No Problemo (Query)
Here’s a view and a query, where things work just fine:
CREATE OR ALTER VIEW
dbo.DasView
WITH SCHEMABINDING
AS
SELECT
p.Score,
p.OwnerUserId,
p.CreationDate,
p.LastActivityDate,
DENSE_RANK() OVER
(
PARTITION BY
p.OwnerUserId
ORDER BY
p.Score DESC
) AS PostRank
FROM dbo.Posts AS p;
GO
SELECT
p.*
FROM dbo.DasView AS p
WHERE p.OwnerUserId = 22656;
GO
The reason this works fine is because the where clause contains a literal value, and not a variable or parameter placeholder.
iron seek
Everything is how we would expect this query plan to look, given the indexes available.
Si Problemo (View)
Where things become wantonly unhinged is when we supply a placeholder for that literal value.
CREATE OR ALTER PROCEDURE
dbo.DasProcedure
(
@OwnerUserId integer
)
AS
SET NOCOUNT, XACT_ABORT ON;
BEGIN
SELECT
p.*
FROM dbo.DasView AS p
WHERE p.OwnerUserId = @OwnerUserId
/*OPTION(QUERYTRACEON 4199)*/
/*OPTION(USE HINT('QUERY_OPTIMIZER_COMPATIBILITY_LEVEL_160'))*/;
END;
GO
EXEC dbo.DasProcedure
@OwnerUserId = 22656;
GO
Note that I have a query trace on and use hint here, but quoted out. You could also use these to fix the issue for a single query, but my goal is to show you what happens when things aren’t fixed.
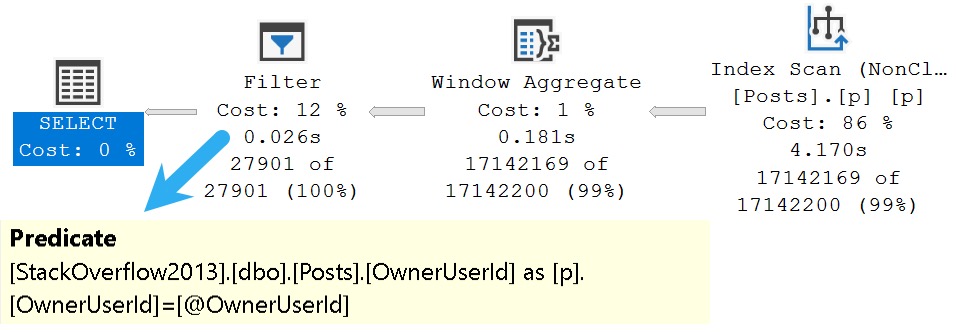
Here’s what that looks like:
asbestos
Rather than a seek into the index we created, the entire thing is scanned, and we have a filter that evaluates our placeholder from 17 million rows and whittles the results down to 27,901 rows.
No Problemo (Function)
Using an inline table valued function allows us to bypass the issue, without any hints or database settings changes.
CREATE OR ALTER FUNCTION
dbo.DasFunction
(
@OwnerUserId integer
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
SELECT
p.Score,
p.OwnerUserId,
p.CreationDate,
p.LastActivityDate,
DENSE_RANK() OVER
(
PARTITION BY
p.OwnerUserId
ORDER BY
p.Score DESC
) AS PostRank
FROM dbo.Posts AS p
WHERE p.OwnerUserId = @OwnerUserId;
GO
This changes our procedure as well:
CREATE OR ALTER PROCEDURE
dbo.DasProcedure
(
@OwnerUserId integer
)
AS
SET NOCOUNT, XACT_ABORT ON;
BEGIN
SELECT
p.*
FROM dbo.DasFunction(@OwnerUserId) AS p;
END;
GO
EXEC dbo.DasProcedure
@OwnerUserId = 22656;
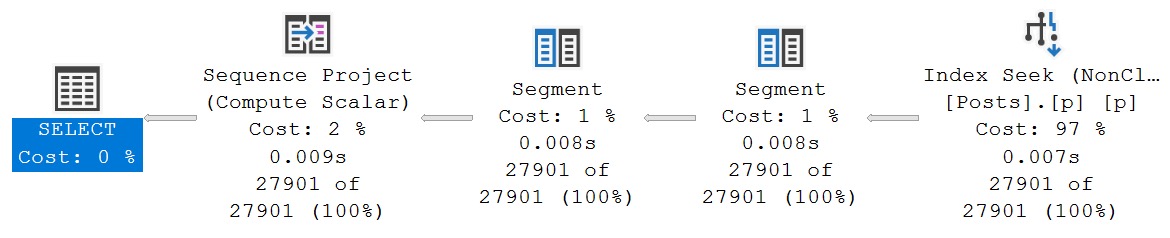
And our query plan goes back to normal.
fastigans
Even if you don’t have this specific problem, it’s often worth exploring converting views to inline table valued functions, because quite often there is a common filtering or joining criteria, and having parameters to express that is beneficial in a couple ways:
It better shows the intent of module and what it can be used for
It prevents developers from forgetting filtering criteria and exploding results
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Whether you want to be the next great query tuning wizard, or you just need to learn how to start solving tough business problems at work, you need a solid understanding of not only what makes things fast, but also what makes them slow.
I work with consulting clients worldwide fixing complex SQL Server performance problems. I want to teach you how to do the same thing using the same troubleshooting tools and techniques I do.
I’m going to crack open my bag of tricks and show you exactly how I find which queries to tune, indexes to add, and changes to make. In this day long session, you’re going to learn about hardware, query rewrites that work, effective index design patterns, and more.
Before you get to the cutting edge, you need to have a good foundation. I’m going to teach you how to find and fix performance problems with confidence.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Common table expressions remind me of clothes in the 70s. A bunch of people with no taste convinced a bunch of people with no clue that they should dress like them, and so we got… Well, at least we got the 80s afterwards.
The big draw with common table expressions is that they filled in some blanks that derived tables left unanswered.
The first problem with common table expressions is that most people use them like nose and ear hair trimmers: they just sort of stick them in and wave them around until they’re happy, with very little observable feedback as to what has been accomplished.
The second big problem with common table expressions is that the very blanks they were designed to fill in are also the very big drawbacks they cause, performance-wise. Sort of like a grand mal petard hoisting.
To bring things full circle, asking someone why they used a common table expression is a lot like asking someone why they wore crocheted bell bottoms with a velour neckerchief in the 70s. Someone said it was a good idea, and… Well, at least we got the 80s afterwards.
Much like joins and Venn diagrams, anyone who thinks they have some advanced hoodoo to teach you about common table expressions is a charlatan or a simpleton. They are one of the least advanced constructs in T-SQL, and are no better or worse than any other abstraction layer, with the minor exception that common table expressions can be used to build recursive queries.
Other platforms, enviably, have done a bit to protect developers from themselves, by offering ways to materialize common table expressions. Here’s how Postgres does it, which is pretty much the opposite of how SQL Server does it.
By default, and when considered safe, common table expressions are materialized to prevent re-execution of the query inside them.
You can force the issue by doing this (both examples are from the linked docs):
WITH w AS MATERIALIZED (
SELECT * FROM big_table
)
SELECT * FROM w AS w1 JOIN w AS w2 ON w1.key = w2.ref
WHERE w2.key = 123;
Or go your own way and choose to not materialize it:
WITH w AS NOT MATERIALIZED (
SELECT * FROM big_table
)
SELECT * FROM w AS w1 JOIN w AS w2 ON w1.key = w2.ref
WHERE w2.key = 123;
You don’t get those options in SQL Server as of this writing, which really sucks because developers using other platforms may have certain expectations that are, unfortunately, not met.
Likewise, other sane and rational platforms use MVCC (optimistic locking) by default, which SQL Server does not. Another expectation that will unfortunately not be met for cross-platform developers.
Common Table Cult
The amount of developer-defense that common table expressions get is on par with the amount of developer-defense that table variables get.
It’s quite astounding to witness. How these things became such sacred cows is beyond me.
First, there are times when using a common table expression has no impact on anything:
WITH
nocare AS
(
SELECT
u.*
FROM dbo.Users AS u
WHERE u.Reputation > 999999
)
SELECT
n.*
FROM nocare AS n;
WITH
nocare AS
(
SELECT
u.*
FROM dbo.Users AS u
)
SELECT
*
FROM nocare AS n
WHERE n.Reputation > 999999;
SQL Server is at least smart enough to be able to push most predicates used outside of common table expressions up into the common table expression.
One example of such a limitation is when you put a windowing function into a common table expression:
WITH
nocare AS
(
SELECT
v.*,
n =
ROW_NUMBER() OVER
(
PARTITION BY
v.UserId
ORDER BY
v.CreationDate
)
FROM dbo.Votes AS v
)
SELECT
n.*
FROM nocare AS n
WHERE n.VoteTypeId = 8
AND n.n = 0;
If VoteTypeId were in the PARTITION BY clause of the windowing function, it could be pushed into the common table expression portion of the query. Without it in there, it has to be filtered out later, when the where clause also looks for rows numbered as 0.
But this does bring us to a case where common table expressions are generally okay, but would perform equivalently with a derived table: when you need to stack some logic that can’t be performed in a single pass.
Using a common table expression to filter out the results of a windowing function just can’t be done without some inner/outer context. Since objects in the select list are closer than they appear, you can’t reference them in the where clause directly.
I’m fine with that, as shown in the example above.
Common Stacks
Stacked common table expressions are also “fine” up to a point, and with caveats.
DECLARE
@page_number int = 1,
@page_size int = 100;
WITH
f /*etch*/ AS
(
SELECT TOP (@page_number * @page_size)
p.Id,
n =
ROW_NUMBER() OVER
(
ORDER BY
p.Id
)
FROM dbo.Posts AS p
ORDER BY
p.Id
),
o /*ffset*/ AS
(
SELECT TOP (@page_size)
f.id
FROM f
WHERE f.n >= ((@page_number - 1) * @page_size)
ORDER BY
f.id
)
SELECT
p.*
FROM o
JOIN dbo.Posts AS p
ON o.id = p.Id
ORDER BY
p.Id;
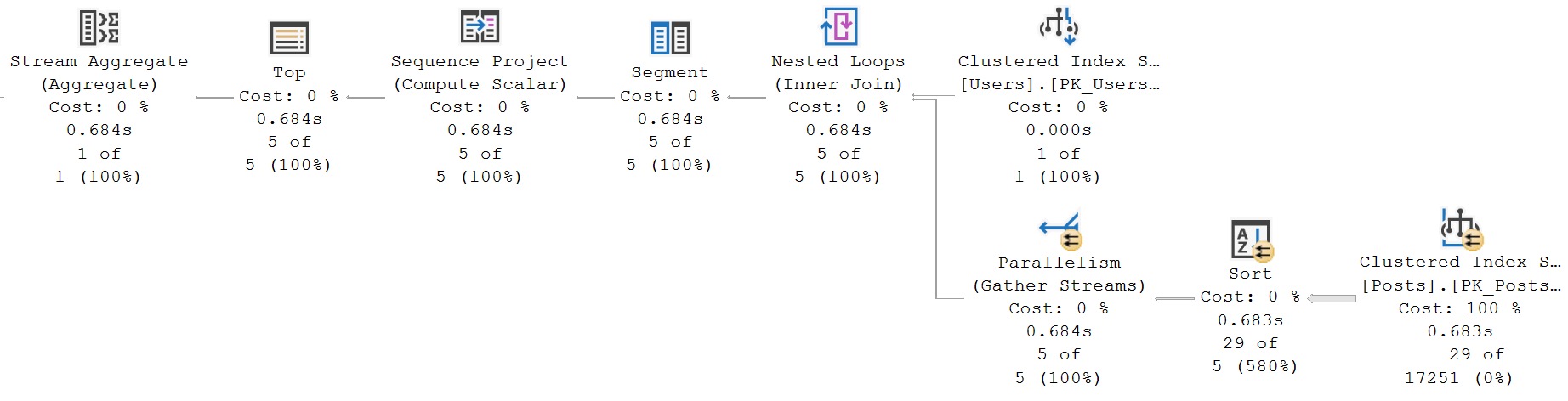
The reason why this is okay is because each common table expression has a single reference. There are two points in the query plan where data is acquired from the Posts table.
uno dos!
Where things get tricky is when you keep doing it over and over again.
Attack Stacks
Take a query like this, and imagine what the query plan will look like for a moment.
WITH
top5 AS
(
SELECT
p.*,
n =
ROW_NUMBER() OVER
(
PARTITION BY
p.OwnerUserId
ORDER BY
p.Score DESC
)
FROM dbo.Posts AS p
WHERE p.OwnerUserId = 22656
AND p.PostTypeId = 1
)
SELECT
u.DisplayName,
t1.Title,
t2.Title,
t3.Title,
t4.Title,
t5.Title
FROM dbo.Users AS u
LEFT JOIN top5 AS t1
ON t1.OwnerUserId = u.Id
AND t1.n = 1
LEFT JOIN top5 AS t2
ON t2.OwnerUserId = u.Id
AND t2.n = 2
LEFT JOIN top5 AS t3
ON t3.OwnerUserId = u.Id
AND t3.n = 3
LEFT JOIN top5 AS t4
ON t4.OwnerUserId = u.Id
AND t4.n = 4
LEFT JOIN top5 AS t5
ON t5.OwnerUserId = u.Id
AND t5.n = 5
WHERE t1.OwnerUserId IS NOT NULL;
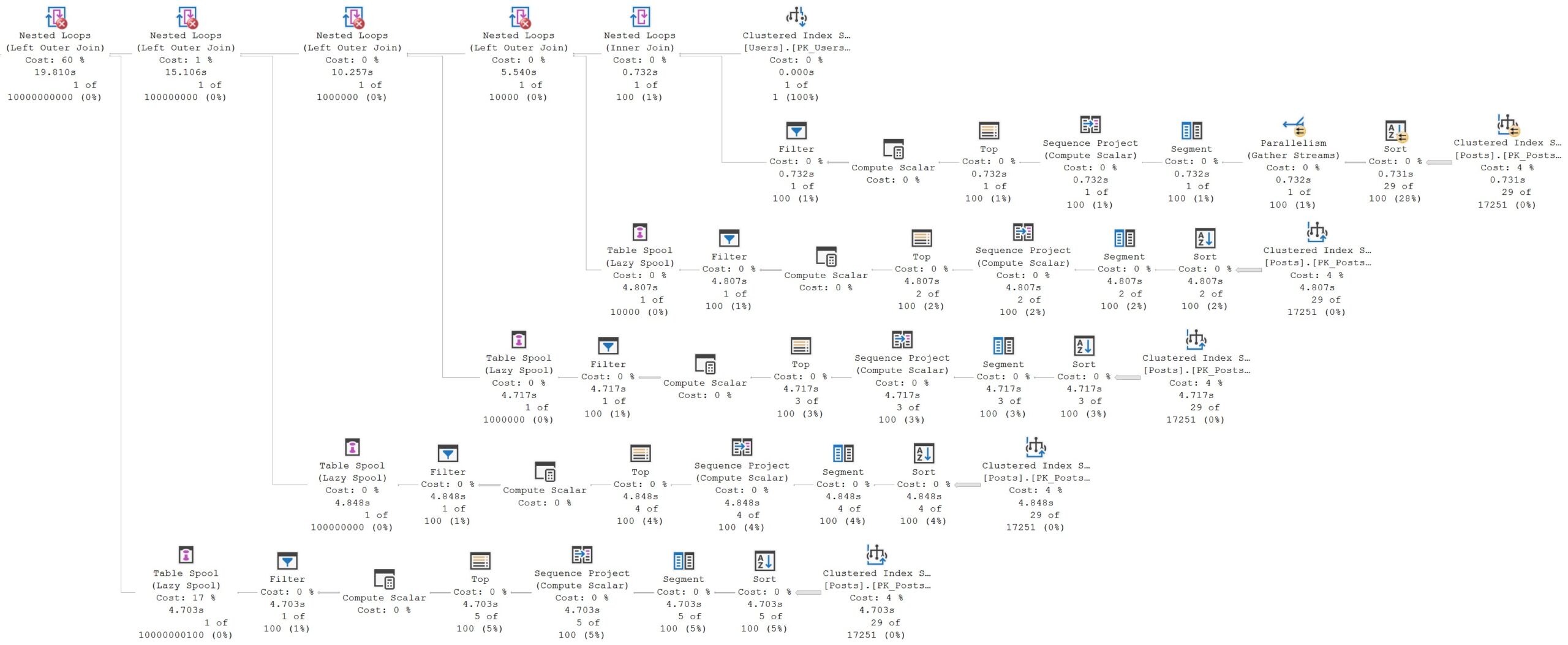
An utter disaster, predictably:
moo 🐮
We hit the Posts table a total of five times, or once for each reference back to the original common table expression.
This is not a good use of a common table expression, and is a pattern in general to avoid when using them.
Think of common table expressions sort of like ordering a Rum Martinez. You might be happy when the results eventually show up, but every time you say “Rum Martinez”, the bartender has to go through the whole process again.
There’s no magickal pitcher of Rum Martinez sitting around for your poor bartender to reuse.
That’s called a Shirley Temp Table.
Pivot Peeve
This particular query could use a temp table to materialize the five rows, and re-joining to that would be cheap and easy, even five times, since it’s only five rows going in.
WITH
top5 AS
(
SELECT
p.*,
n =
ROW_NUMBER() OVER
(
PARTITION BY
p.OwnerUserId
ORDER BY
p.Score DESC
)
FROM dbo.Posts AS p
WHERE p.OwnerUserId = 22656
AND p.PostTypeId = 1
)
SELECT
t.OwnerUserId,
t.Title,
n
INTO #top5
FROM top5 AS t
WHERE t.n <= 5;
You could also also just PIVOT this one, too:
WITH
u AS
(
SELECT TOP (5)
u.DisplayName,
p.Title,
n = ROW_NUMBER() OVER (ORDER BY p.Score DESC)
FROM dbo.Posts AS p
JOIN dbo.Users AS u
ON p.OwnerUserId = u.Id
WHERE p.OwnerUserId = 22656
AND p.PostTypeId = 1
ORDER BY
p.Score DESC
)
SELECT
p.*
FROM u AS u
PIVOT
(
MAX(Title)
FOR n IN ([1], [2], [3], [4], [5])
) AS p;
For all the problems PIVOT can cause when misused, this is a full 19 seconds faster than our most precious common table expression query.
With a half-decent index, it’d probably finish in just about no time.
PIVOT TIME!
I’d take this instead any day.
A Note On Recursion
There may be times when you need to build a recursive expression, but you only need the top N children, or you want to get rid of duplicates in child results.
Since you can’t use DISTINCT, TOP, or OFFSET/FETCH directly in a recursive common table expression, some nesting is required.
Of course, we can’t currently nest common table expressions, and to be clear, I think that idea is dumb and ugly.
If Microsoft gives us nested common table expressions before materialized common table expressions, I’ll never forgive them.
WITH
postparent AS
(
SELECT
p.Id,
p.ParentId,
p.OwnerUserId,
p.Score,
p.PostTypeId,
Depth = 0,
FullPath = CONVERT(varchar, p.Id)
FROM dbo.Posts AS p
WHERE p.CreationDate >= '20131229'
AND p.PostTypeId = 1
UNION ALL
SELECT
p2.Id,
p2.ParentId,
p2.OwnerUserId,
p2.Score,
p2.PostTypeId,
p2.Depth,
p2.FullPath
FROM
(
SELECT
p2.Id,
p2.ParentId,
p2.OwnerUserId,
p2.Score,
p2.PostTypeId,
Depth = pp.Depth + 1,
FullPath = CONVERT(VARCHAR, CONCAT(pp.FullPath, '/', p2.Id)),
n = ROW_NUMBER() OVER (ORDER BY p2.Score DESC)
FROM postparent pp
JOIN dbo.Posts AS p2
ON pp.Id = p2.ParentId
AND p2.PostTypeId = 2
) AS p2
WHERE p2.n = 1
)
SELECT
pp.Id,
pp.ParentId,
pp.OwnerUserId,
pp.Score,
pp.PostTypeId,
pp.Depth,
pp.FullPath
FROM postparent AS pp
ORDER BY
pp.Depth
OPTION(MAXRECURSION 0);
To accomplish this, you need to use a derived table, filtering the ROW_NUMBER function outside of it.
This is a more common need than most developers realize when working with recursive common table expressions, and can avoid many performance issues and max recursion errors.
It’s also a good way to show off to your friends at disco new wave parties.
Common Table Ending
Common table expressions can be handy to add some nesting to your query so you can reference generated expressions in the select list as filtering elements in the where clause.
They can even be good in other relatively simple cases, but remember: SQL Server does not materialize results, though it should give you the option to, and the optimizer should have some rules to do it automatically when a common table expression is summoned multiple times, and when it would be safe to do so. I frequently pull common table expression results into a temp table, both to avoid the problems with re-referencing them, and to separate out complexity. The lack of materialization can be hell on cardinality estimation.
In complicated queries, they can often do more harm than good. Excuses around “readability” can be safely discarded. What is “readable” to you, dear human, may not be terribly understandable to the optimizer. You’re not giving it any better information by using common table expressions, nor are you adding any sort of optimization fence to any queries in them without the use of TOP or OFFSET/FETCH. Row goals are a hell of a drug.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.