SURPRISE!
The important thing to understand about parallelism is it’s great when appropriate. Striking a balance between what should go parallel, the CPU usage it’s allowed, and what should stay serial can be tough.
It can be especially difficult when parameter sniffing comes into play. Here are a couple scenarios:
- For a small amount of data, a serial query plan runs quickly and uses relatively few resources
- For a large amount of data, a query re-uses the serial plan and runs for >20 seconds
- For a small amount of data, a re-used parallel plan overloads the server due to many concurrent sessions
- For a large amount of data, the re-used parallel plan finishes in 2-3 seconds
What do you do? Which plan do you favor? It’s an interesting scenario. Getting a single query to run faster by going parallel may seem ideal, but you need extra CPU, and potentially many more worker threads to accomplish that.
In isolation, you may think you’ve straightened things out, but under concurrency you run out of worker threads.
There are ways to address this sort of parameter sniffing, which we’ll get to at some point down the line.
Wrecking Crew
One way to artificially slow down a query is to use some construct that will inhibit parallelism when it would be appropriate.
There are some exotic reasons why a query might not go parallel, but quite commonly scalar valued functions and inserts to table variables are the root cause of otherwise parallel-friendly queries staying single-threaded and running for long times.
While yes, some scalar valued functions can be inlined in SQL Server 2019, not all can. The list of ineligible constructs has grown quite a bit, and will likely continue to. It’s a feature I love, but it’s not a feature that will fix everything.
Databases are hard.
XML Fetish
You don’t need to go searching through miles of XML to see it happening, either.
All you have to do is what I’ve been telling you all along: Look at those operator properties. Either hit F4, or right click and choose the properties of a select operator.

Where I see these performance surprises! pop up is often when either:
- Developers develop on a far smaller amount of data than production contains
- Vendors have clients with high variance in database size and use
In both cases, small implementations likely mask the underlying performance issues, and they only pop up when run against bigger data. The whole “why doesn’t the same code run fast everywhere” question.
Well, not all features are created equally.
Simple Example
This is where table variables catch people off-guard. Even the “I swear I don’t put a lot of rows in them” crowd may not realize that the process to get down to very few rows is impacted by these @features.
SELECT TOP (1000) c.Id FROM dbo.Comments AS c ORDER BY c.Score DESC;
This query, on its own, is free to go parallel — and it does! It takes about 4.5 seconds to do so. It’s intentionally simple.
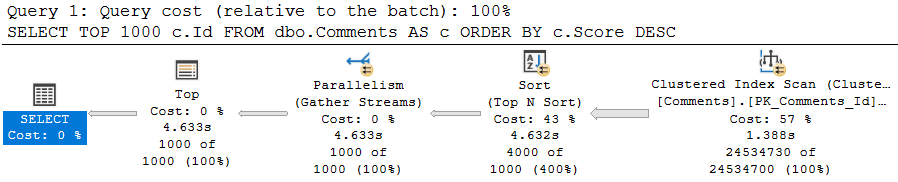
Once we try to involve a @table variable insert, parallelism goes away, time increases 3 fold, and the non-parallel plan reason is present in the plan XML.
DECLARE @t TABLE(id INT); INSERT @t ( id ) SELECT TOP 1000 c.Id FROM dbo.Comments AS c ORDER BY c.Score DESC;
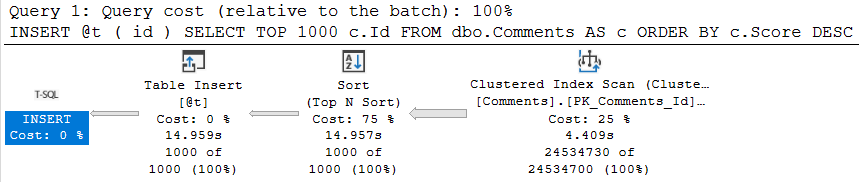
Truesy
This can be quite a disappointing ramification for people who love to hold themselves up as responsible table variable users. The same will occur if you need to update or delete from a @table variable. Though less common, and perhaps less in need of parallelism, I’m including it here for completeness.
This is part of why multi-statement table valued functions, which return @table variables, can make performance worse.
To be clear, this same limitation does not exist for #temp tables.
Anyway, this post went a little longer than I thought it would, so we’ll look at scalar functions in tomorrow’s post to keep things contained.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Help me understand these stats a little better please.
I get that parallel can allow multiple operations simultaneously and the point o the article is that table variable can interfere. In this case, the Index Scan and the Sort can be done in parallel to achieve an outcome both are done simultaneously, resulting in improvement. What I do NOT understand is why the dramatic difference in cost between the two plans for the same operations.
The Scan in the serial version is almost 3 times as long as the same Scan in the parallel. Similarly the Sort is more than twice as long. I would have expected those operations to be essentially the same cost, but in serial (i.e. parallel query finishes in about 4.6 seconds (1.38 and 4.6 in parallel) and query 2 finishes in about 6 seconds (1.38 and 4.6 in serial).
The short answer is that execution plan costs are largely meaningless, and you shouldn’t rely on them for anything.