What’s With Widths?
We don’t need to add a ton of columns to our query to have index usage change, but we do need to go back in time a little bit.
Here’s our query now, with just a one day difference in the where clause.
SELECT p.CreationDate,
COUNT_BIG(*) AS records
FROM dbo.Posts AS p
WHERE p.CreationDate >= '20131015'
AND p.OwnerUserId = 22656
GROUP BY p.CreationDate;
SELECT p.CreationDate,
COUNT_BIG(*) AS records
FROM dbo.Posts AS p
WHERE p.CreationDate >= '20131016'
AND p.OwnerUserId = 22656
GROUP BY p.CreationDate;
Not quite Halloween, but I’ll take the spooky factor.
The other difference is that now we’ve got the OwnerUserId column in there, which isn’t in our nonclustered index.
It’s in the where clause, not the select list, but if we added it there it would have a similar effect on the query. Either way, we have to do something with this new column, and we have to get it from somewhere.
CREATE INDEX CreationDate ON dbo.Posts(CreationDate);
Things Are Looking Up
The query plans for these will look a little bit different.
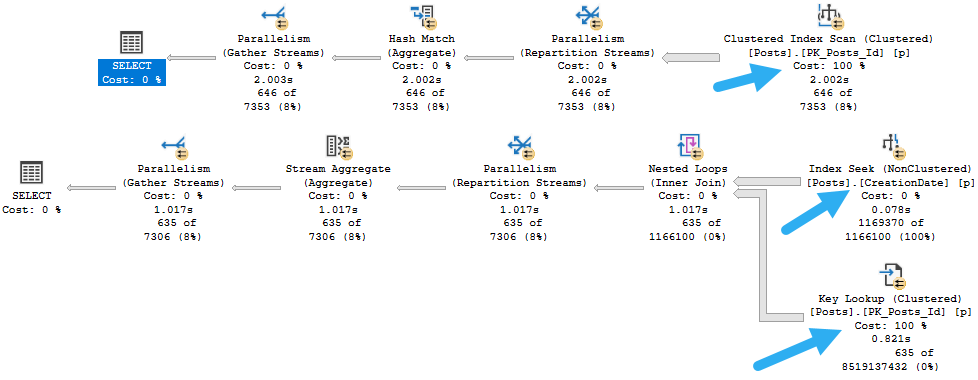
If you’re not familiar with what just happened here, a Key Lookup is a trick the optimizer has up its sleeve. It uses two indexes from the same table to satisfy one query.
We find rows in our nonclustered index that qualify for the filter on CreationDate. That’s a smart start!
Then we join the nonclustered index to the clustered index to find any columns we might need. Remember the clustered index has all the table columns in it.
Stuff like this is made possible by nonclustered indexes inheriting clustered index key columns. Crazy, right?
The Point At This Point
There are many internal details to explore around Key Lookups. There are even some interesting things about how clustered index keys get stored in nonclustered indexes.
What you need to know about Lookups right now is what they are (which we talked about), and that they represent a choice the optimizer has when it comes to index usage.
If you create a narrow index, say one that satisfies some part of the query like the join or where clause, but doesn’t fully contain all of the columns referenced in your query, it may not get used reliably. The usage is decided based on cardinality estimates. The more rows SQL Server expects, the less likely it is that your narrow index will get used.
For example, it may only get used when the value for CreationDate is estimated to return a small-ish number of rows. Parameterization and plan re-use can make this even more confusing.
Next, we’ll look at how we can encourage the optimizer to choose narrow indexes, and the problems we might run into.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Related Posts
- Starting SQL: Fixing Parameter Sensitivity Problems With SQL Server Queries
- Starting SQL: Why Is My SQL Server Query Suddenly Slower Than It Was Yesterday?
- SQL Server 2022 CTP 2.1 Improvements To Parameter Sensitive Plan Optimization
- SQL Server 2022 Parameter Sensitive Plan Optimization: Does Not Care To Fix Your Local Variable Problems