Your Fault
Yesterday we created an index, and things went pretty well. Good for us. By next week we’ll have six pack abs.
Today we’re going to look at things that I see happen pretty often in queries that mess with effciency.
If one were to sit and think carefully about the way B-Tree indexes are implemented, where key columns define order, one may see these problems coming a mile away.
Then again, one might expect a full formed datababby system to be able to figure some of these things out and use indexes appropriately anyway.
General Anti-Patterns
I’ve posted this on here a number of times, but here it goes again.
Things that keep SQL Server from being able to seek:
- Function(Column) = …
- Column + Column = …
- Column + Value = …
- Value + Column = …
- Column = @Value or @Value IS NULL
- Column LIKE ‘%…’
- Some implicit conversions (data type mismatches)
Seeks aren’t always necessary, or even desirable, and likewise scans aren’t always bad or undesirable. But if we’re going to give our queries the best chance of running well, our job is most often to give the optimizer every opportunity to make the right decisions. Being the optimizer is hard enough without us grabbing it by the nose and poking it in the eyes.
To fix code, or make code that looks like that tolerable to The Cool DBA Kids™, there are some options like:
- Computed columns
- Dynamic SQL
- Rewrites
Different options work well in different scenarios, of course. And since we’re here, I might as well foreshadow a future post: These patterns are most harmful when applied to the leading key column of an index. When they’re residual predicates that follow seek predicates, they generally make less of a difference. But we’re not quite there yet.
The general idea, though, is that as soon as we write queries in a way that obscure column data, or introduce uncertainty about what we’re searching for, the optimizer has a more difficult time of things.
Do It Again
Let’s compare a couple different ways of writing yesterday’s query. One good, one bad (in that order).
SELECT p.CreationDate,
COUNT_BIG(*) AS records
FROM dbo.Posts AS p
WHERE p.CreationDate >= '20131225'
GROUP BY p.CreationDate;
SELECT p.CreationDate,
COUNT_BIG(*) AS records
FROM dbo.Posts AS p
WHERE YEAR(p.CreationDate) = 2013
AND MONTH(p.CreationDate) = 12
AND DAY(p.CreationDate) >= 25
GROUP BY p.CreationDate;
The mistake people often make here is that they think these presentation layer functions have some relational meaning. They don’t.
They’re presentation layer functions. Let’s see those execution plans. Maybe then you’ll believe me.
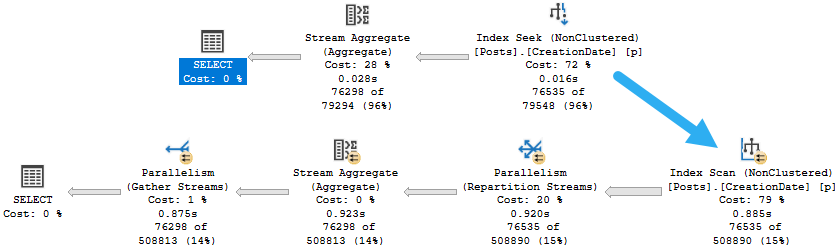
Things are not so hot when we pile a Mess Of Functions™ into the where clause, are they?
I mean, our CPUs are hot, but that’s generally not what we’re after.
The Use Of Indexes
We could still use our index. Many people will talk about functions preventing the use of indexes, but more precisely we just can’t seek into them.
But you know what can prevent the use of nonclustered indexes? Long select lists.
Next time, we’ll look at that.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Related Posts
- Starting SQL: Why Your SQL Server Query Can’t Go Parallel, Scalar Functions Edition
- Starting SQL: SARGability, Or Why Some SQL Server Queries Will Never Seek
- Starting SQL: Fixing Parameter Sensitivity Problems With SQL Server Queries
- Starting SQL: How Parameters Can Change Which Indexes SQL Server Chooses