Index Skit (0:39)
The most common types of indexes you’re going to see in your life are of the rowstore variety.
As much as I love columnstore, it’s probably not something you’re going to see a whole lot outside of data warehouses. Sure, some folks will have reporting over OLTP, and might find some utility for them, but they can be tough to manage with all those tiny modifications.
Let’s stick with the stuff that’ll help you the most: clustered and nonclustered rowstore indexes.
There are important things to know about indexes, and we’ll get more in-depth later on. For now, let’s talk about how they can help a query.
Clustered
Our table has a clustered index on it, which is also playing the part of a primary key. The primary key attribute makes it unique, of course. By default, if you create a primary key, it’ll also be used as the clustered index key. If you only create a clustered index, it won’t be unique by default.
Let’s not get bogged down there, though. Here’s our index.
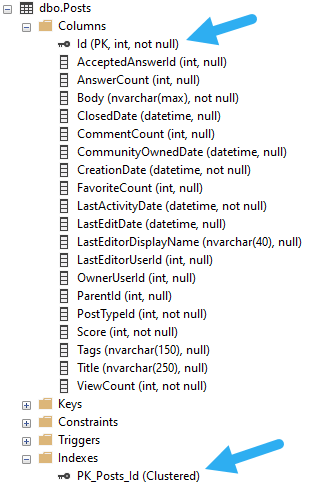
We can identify clustered indexes and which columns are in them pretty easily in SSMS.
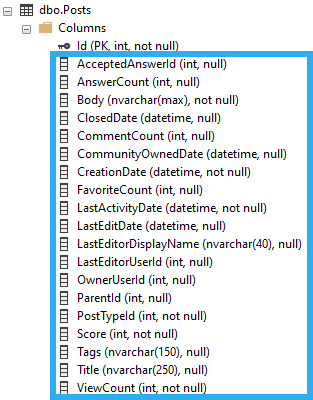
To simplify a bit, the clustered index is all these columns:
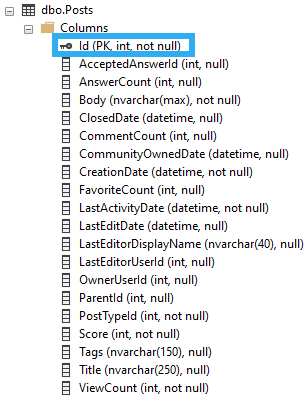
Ordered by this column:
That’s Great But
Having the Id column in order doesn’t help us find data in other columns, because they’re not in order.
Let’s say we wanted to find posts by CreationDate. The values for it aren’t in an order that helps us search through them.
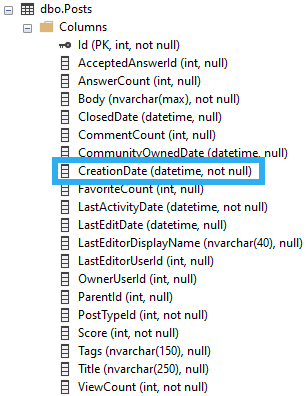
If our query is only concerned with the CreationDate column we can create a single-column index on it. As queries become more complicated and involve more columns, we need to consider wider indexes sometimes so that they stand a better chance of getting used, but we’ll come back to that later.
Here’s our overly-simple query.
SELECT p.CreationDate,
COUNT_BIG(*) AS records
FROM dbo.Posts AS p
WHERE p.CreationDate >= '20131225'
GROUP BY p.CreationDate;
And here’s how the optimizer decides to answer our query.

We have to scan all of the data pages in the clustered index looking for CreationDates that match our predicate.
Make It Plain
It’s not such a crazy idea to create additional indexes to speed up queries, but how exactly do they do that?
What is it about indexes that magically make queries go faster? According to the title, they put data in order, so let’s go with that.
It’s easy enough to create a helpful index here.
CREATE INDEX CreationDate ON dbo.Posts(CreationDate);
Tomorrow, we’ll look at ways to see if our index gets used, and different ways to measure if it improves our query.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.