Well, well, well
So you’re that odd soul who has been listening to rumors about table variables. Perhaps things about them only being in memory, or that they’re okay to use if you only put less than some arbitrary number of rows in them.
Those things are both wrong. But of course, my favorite rumor is the one about arbitrary numbers of rows being safe.
Ouch! What a terrible performance
Let’s do everything in our power to help SQL Server make a good guess.
We’ll create a couple indexes:
CREATE INDEX free_food ON dbo.Posts(OwnerUserId); CREATE INDEX sea_food ON dbo.Comments(UserId);
Those stats’ll be so fresh you could make tartare with them.
We’ll create our table variable with a primary key on it, which will also be the clustered index.
DECLARE @t TABLE( id INT PRIMARY KEY ); INSERT @t ( id ) VALUES(22656);
And finally, we’ll run the select query with a recompile hint. Recompile fixes everything, yeah?
SELECT AVG(p.Score * 1.) AS lmao
FROM @t AS t
JOIN dbo.Posts AS p
ON p.OwnerUserId = t.id
JOIN dbo.Comments AS c
ON c.UserId = t.id
OPTION(RECOMPILE);
GO
How does the query do for time? Things start off okay, but keep the cardinality estimate in mind.
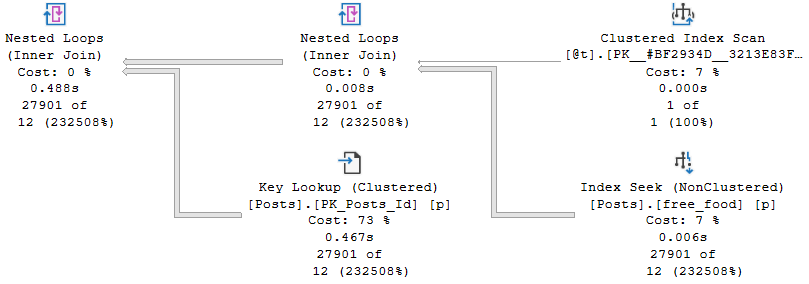
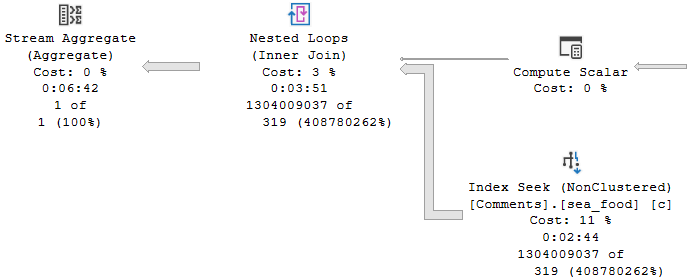
But quickly go downhill.
Fish are dumb, dumb, dumb
The whole problem here is that, even with just one row in the table variable, an index on the one column in the table variable, and a recompile hint on the query that selects from the table variable, the optimizer has no idea what the contents of that single row are.
That number remains a mystery, and the guess made ends up being wrong by probably more than one order of magnitude. Maybe even an order of manure.
Table variables don’t gather any statistical information about what’s in the column, and so has no frame of reference to make a better cardinality estimate on the joins.
If we insert a value that gets far fewer hits in both the Posts and Comments tables (12550), the estimate doesn’t really hurt. But note that the guesses across all operators are exactly the same.
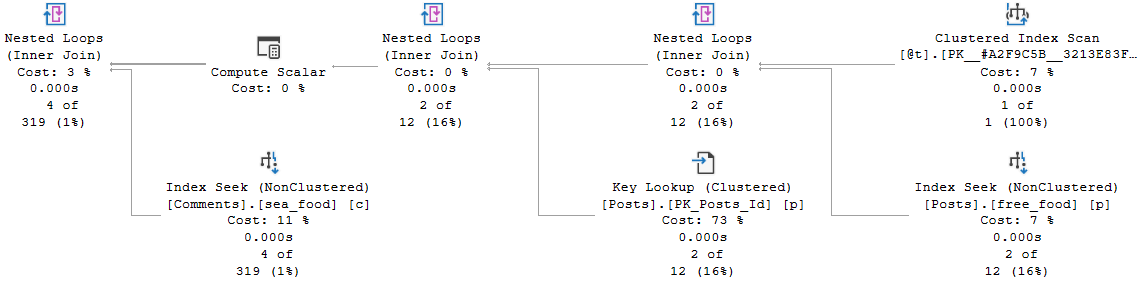
C’est la vie mon ami
You have a database. Data is likely skewed in that database, and there are already lots of ways that you can get bad guesses. Parameter sniffing, out of date stats, poorly written queries, and more.
Databases are hard.
The point is that if you use table variables outside of carefully tested circumstances, you’re just risking another bad guess.
All of this is tested on SQL Server 2019, with table variable deferred compilation enabled. All that allows for is the number of rows guessed to be accurate. It makes no attempt to get the contents of those rows correct.
So next time you’re sitting down to choose between a temp table and a table variable, think long and hard about what you’re going to be doing with it. If cardinality esimation might be important, you’re probably going to want a temp table instead.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Great post Erik, I feel I need to get this stuck to people’s screens “Table variables don’t gather any statistical information about what’s in the column” or maybe put on a T-shirt or coffee mug. Maybe not one for mass appeal…
Hah yeah, might need to work on it to make it a little more bumper sticker friendly, but I fully support the endeavor.