Sweet Like
Clustered indexes are great, really. Usually. Okay, if they’re bad it’s probably your fault.
Did you really need 10 columns in the key? Did you have to make it on a NVARCHA5(512)?
No. You messed that up. By that I mean the royal you. All of you.
The thing is, they’re of limited overall value for searching for data.
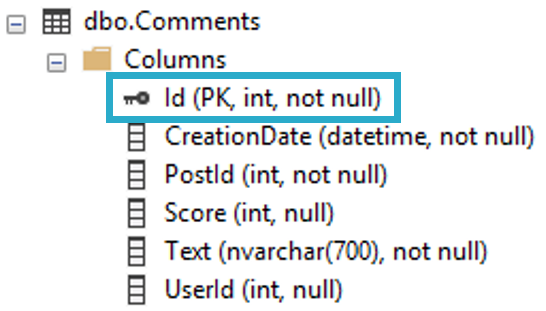
If every single join and where clause has this Id column in it, we might be okay. But the odds of that being the case are slim to none.
As soon as we want to search by any other columns without searching for a specific Id, we’re toast. That data doesn’t exist in a helpful order for searching.
I know I’ve mentioned it before, but that’s what indexes do to make data easier to find: they put it in order. Ascending, descending. It’s up to you.
The Meaning Of Life
There are two main parts of a nonclustered index: key columns, and included columns.
Sure, there’s other stuff you can do with them, like make them unique, or add filters (where clauses) to them, but we’ll talk about that later.
For now, feast your eyes on the majesty of the nonclustered index create statement.
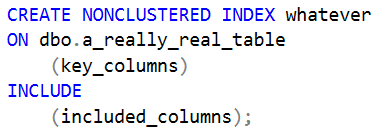
Look at all that. Can you believe how much faster is can make your queries?
Let’s talk about how that works.
Those Keys
If you want to visualize stuff key columns can help in a query, you can almost draw a Fibonacci whatever on top of it.
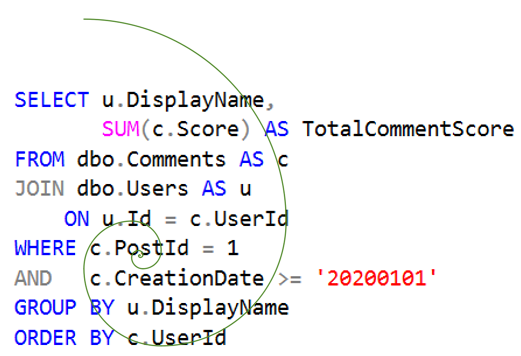
Much of the time, it makes sense to focus on the where clause first.
There will of course be times you’ll need to break from that, but as a general design pattern this is a helpful starting place. The stuff index key columns tend to help is under the from clause. That’s because these parts of the query are most often helped by having data in a pertinent order.
Sometimes things above the from clause can be improved above the from, when there’s an aggregate or windowing function involved, but those considerations are more advanced and specialized.
Inclusion Conclusion
Included columns are helpful for queries, because you can have a single index be the source of data for a query. No need for lookups, and fewer optimizer choices.
But included columns aren’t ordered the way key columns are. They’re kinda like window dressing.
Sure, you can use them to find data, it’s just less efficient without the ordering. You can think of them like all the non-key columns in your clustered index.
Some good uses for includes:
- Columns only in the select list
- Non-selective predicates
- Columns in filter definitions
Includes, though, are the place where I see people go overboard. Thinking back a little, if you’re selecting long lists of columns from wide tables, the optimizer might suggest very wide indexes to compensate for that.
The wider your index definitions are, the higher your chances of modification queries needing to touch them are.
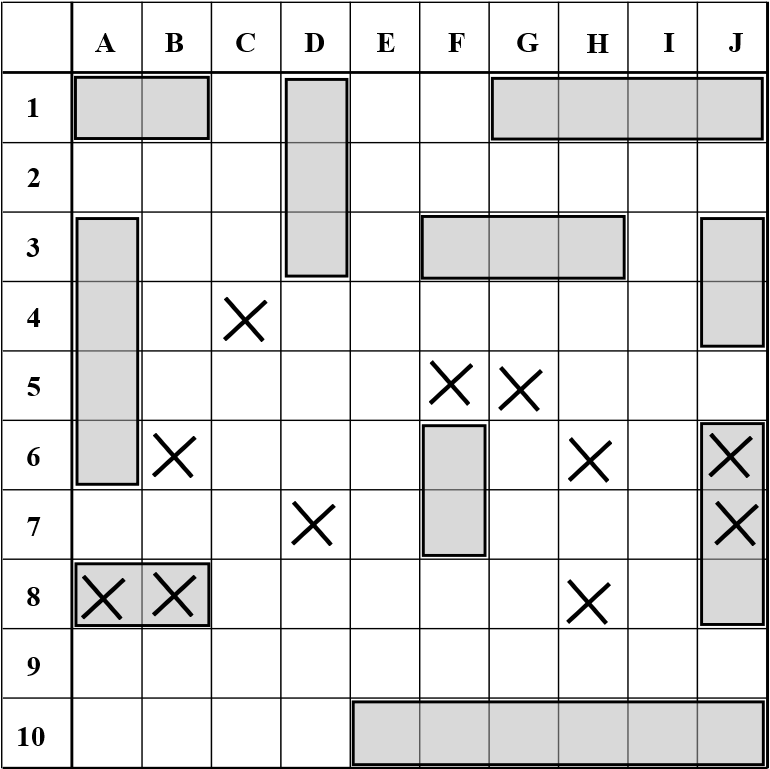
It’s a bit like a game of Battleship. The bigger your indexes get, the more of the board they take up, and the more likely it is you’re gonna get hit by one of those little plastic peg torpedoes.
Baby Teeth
We know we need indexes, and now we’ve got a rough idea of which parts of the index can help which part of our query.
Next, we’ll look at some of the deeper intricacies of index design, like the column-to-column dependencies that exist in row store indexes.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Related Posts
- Starting SQL: SARGability, Or Why Some SQL Server Queries Will Never Seek
- Starting SQL: Fixing Parameter Sensitivity Problems With SQL Server Queries
- Starting SQL: How Parameters Can Change Which Indexes SQL Server Chooses
- Starting SQL: Why Is My SQL Server Query Suddenly Slower Than It Was Yesterday?