Here And There
For many people, index tuning means occasionally adding an index when there’s a report about a slow query. Those indexes might come from a query plan, or from the missing index DMVs, where SQL Server stores every complaint the optimizer files when it thinks an index might make a query better.
Sure, there are some people who think index tuning means rebuilding indexes or running DTA and checking all the boxes, but I ban those IP addresses.
Of course, there’s a whole lot more to index tuning. Adding indexes is fine to a point, but you really should spring clean those suckers once in a while, too.
Look for overlapping indexes, unused indexes, and check for any Heaps that may have snuck in there. sp_BlitzIndex is a pretty cool tool for that.
But even for adding indexes, sometimes it takes more than one pass, especially if you’re taking advice from query plans and DMVs.
How The What
Let’s say you’re looking at a server for the first time, or you’re not quite comfortable with designing your own indexes. No judgment, there.
You see a query plan for some piece of code that’s running slowly, and it has a missing index request.
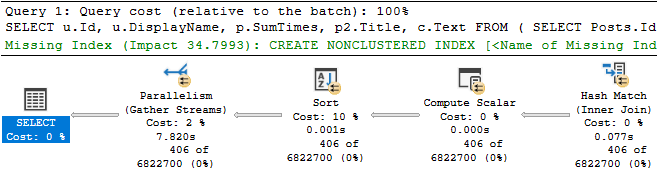
There’s only one missing index request — there’s not a bunch of hidden ones like in some plans — and it looks moderately helpful so you decide to try it.
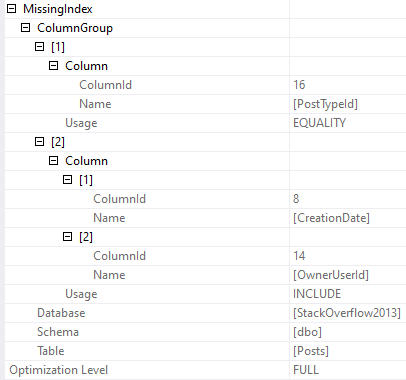
The thing is that as far as “stuff I want to go faster” in the plan, the clustered index scan on Posts is about 3x faster than the clustered index scan on Comments.
And the index that’s being asked for is only going to help us find PostTypeId = 1. It’s not going to help with the rest of or join or filtering very much.
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[Posts] ([PostTypeId]) INCLUDE ([CreationDate],[OwnerUserId])
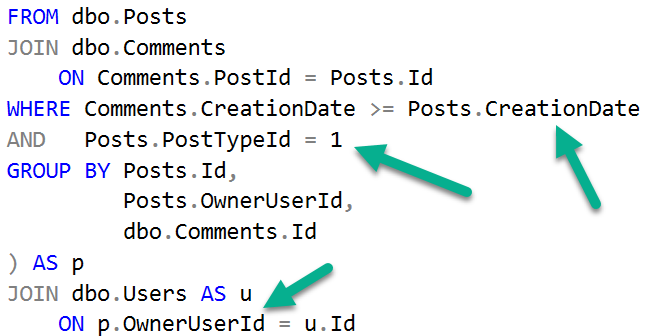
We still need to filter on CreationDate, and join on OwnerUserId later. Sometimes this index will be “good enough” and other times it “won’t”.
If PostTypeId were really selective, or if this query were searching for a particularly selective PostTypeId, then it’d probably be okay-ish.
But we’re not, so we may settle on this index instead.
CREATE NONCLUSTERED INDEX p ON [dbo].[Posts] ([PostTypeId], [CreationDate], [OwnerUserId]);
With that in place, we only get marginal improvement in the timing of the plan. It’s about 1.5 seconds faster.
Probably not what we’d wanna report to end users.
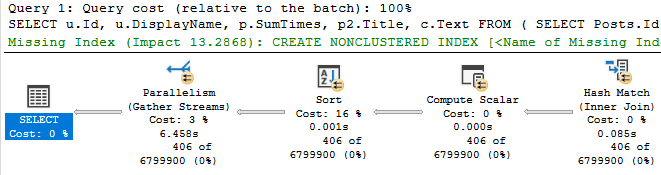
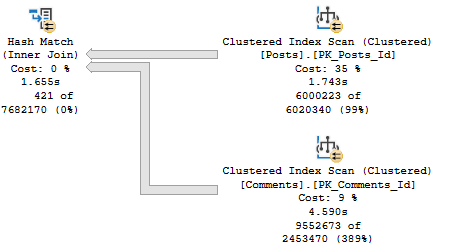
But we have new green text! This time it’s for the Comments table, which is where our pain point lies time-wise.
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[Comments] ([PostId],[CreationDate])
We add that, and reduce our query runtime to less than half of what it was originally.
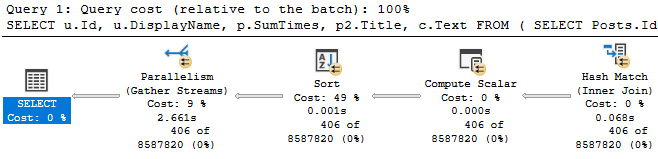
Is 2.6 seconds good? Or great? All depends on expectations.
Could we keep going and experimenting? Sure.
It all depends what we’re allowed to change, what our skill level is (mine is quite low, ho ho ho), and what our priorities are (these are also quite low).
This Is Just One Query
And since we had the luxury of having it in front of us, running it, adding an index, running it again to test the index, etc., we were able to spot the second index request that ended up helping even more than the first one.
If you don’t have that luxury, or if you just poke around the missing index DMVs every 3-6 months, you could miss stuff like this. Sure, that first request would be there, and it might look tempting enough for you to add, but the second one wouldn’t appear until after that. That’s the one that really helped.
Whenever you’re tuning indexes, or releasing code that’s going to use existing data in new ways, you’d be doing yourself a big favor to check in on this stuff at least weekly.
You might be an index tuning wiz and not need to — if you are, I’d be amazed if you made it this far into my blog post, though — or you may catch “obvious” new indexes during development.
But I’m going to tell you something about end users: they’re devious, mischievous, and they’re out to make you look bad.
As soon as they start using those new features of yours, they’re going to abuse them. They’re going to do all sorts of horrible things that you never would have dreamed of. And I’ll bet some different indexes would help you keep your good name.
Or at least your job.
Thanks for reading!
As a postscript to this: I don’t want you to think that missing index requests are the end-all be-all of indexing wisdom. There are lots of limitations, and suggested column order isn’t perfect. But if you’re just getting started, they’re a great way to start to understand indexing, and see the problems they do and don’t solve. And look, the only way to make them better would be to spend longer during compilation thinking about things. That’s not how the optimizer should be spending its time. We’re lucky to get these for free, and you should view them as a learning tool.
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
One thought on “Why Index Tuning Is An Iterative Process In SQL Server”
Comments are closed.