In Shorts
That silly looking subquery avoids two things:
- Trivial Plan
- Simple Parameterization
I use it often in my demo queries because I try to make the base query to show some behavior as simple as possible. That doesn’t always work out, but, whatever. I’m just a bouncer, after all.
The problem with very simple queries is that they may not trigger the parts of the optimizer that display the behavior I’m after. This is the result of them only reaching trivial optimization. For example, trivial plans will not go parallel.
If there’s one downside to making the query as simple as possible and using 1 = (SELECT 1), is that people get very distracted by it. Sometimes I think it would be less distracting to make the query complicated and make a joke about it instead.
The Trouble With Trivial
I already mentioned that trivial plans will never go parallel. That’s because they never reach that stage of optimization.
They also don’t reach the “index matching” portion of query optimization, which may trigger missing index requests, with all their fault and frailty.
/*Nothing for you*/ SELECT * FROM dbo.Users AS u WHERE u.Reputation = 2; /*Missing index requests*/ SELECT * FROM dbo.Users AS u WHERE u.Reputation = 2 AND 1 = (SELECT 1);
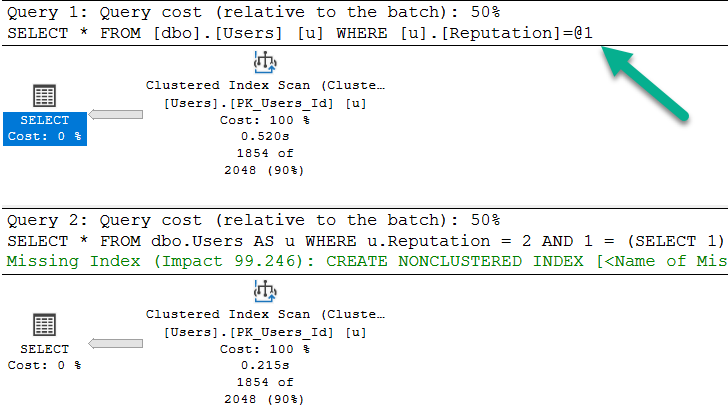
Note that the bottom query gets a missing index request, and is not simple parameterized. The only reason the first query takes ~2x as long as the second query is because the cache was cold. In subsequent runs, they’re equal enough.
What Gets Fully Optimized?
Generally, things that introduce cost based decisions, and/or inflate the cost of a query > Cost Threshold for Parallelism.
- Joins
- Subqueries
- Aggregations
- Ordering without a supporting index
As a quick example, these two queries are fairly similar, but…
/*Unique column*/ SELECT TOP 1000 u.Id --Not this! FROM dbo.Users AS u GROUP BY u.Id; /*Non-unique column*/ SELECT TOP 1000 u.Reputation --But this will! FROM dbo.Users AS u GROUP BY u.Reputation;
One attempts to aggregate a unique column (the pk of the Users table), and the other aggregates a non-unique column.
The optimizer is smart about this:
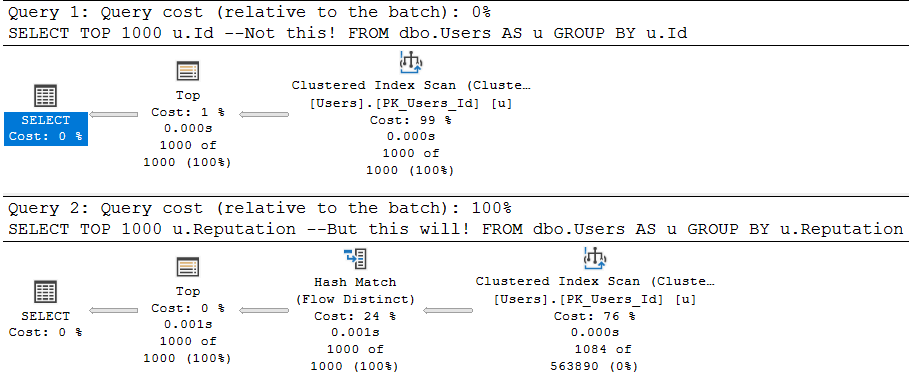
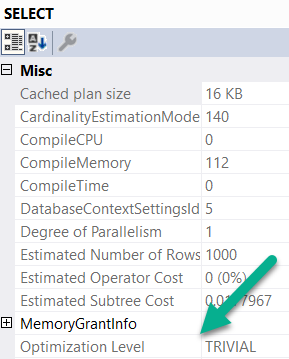
The first query is trivially optimized. If you want to see this, hit F4 when you’re looking at a query plan. Highlight the root operator (select, insert, update, delete — whatever), and look at the optimization level.
Since aggregations have no effect on unique columns, the optimizer throws the group by away. Keep in mind, the optimizer has to know a column is unique for that to happen. It has to be guaranteed by a uniqueness constraint of some kind: primary key, unique index, unique constraint.
The second query introduces a choice, though! What’s the cheapest way to aggregate the Reputation column? Hash Match Aggregate? Stream Aggregate? Sort Distinct? The optimizer had to make a choice, so the optimization level is full.
What About Indexes?
Another component of trivial plan choice is when the choice of index is completely obvious. I typically see it when there’s either a) only a clustered index or b) when there’s a covering nonclustered index.
If there’s a non-covering nonclustered index, the choice of a key lookup vs. clustered index scan introduces that cost based decision, so trivial plans go out the window.
Here’s an example:
CREATE INDEX ix_creationdate ON dbo.Users(CreationDate); SELECT u.CreationDate, u.Id FROM dbo.Users AS u WHERE u.CreationDate >= '20131229'; SELECT u.Reputation, u.Id FROM dbo.Users AS u WHERE u.Reputation = 2; SELECT u.Reputation, u.Id FROM dbo.Users AS u WITH(INDEX = ix_creationdate) WHERE u.Reputation = 2;
With an index only on CreationDate, the first query gets a trivial plan. There’s no cost based decision, and the index we created covers the query fully.
For the next two queries, the optimization level is full. The optimizer had a choice, illustrated by the third query. Thankfully it isn’t one that gets chosen unless we force the issue with a hint. It’s a very bad choice, but it exists.
When It’s Wack
Let’s say you create a constraint, because u loev ur datea.
ALTER TABLE dbo.Users
ADD CONSTRAINT cx_rep CHECK
( Reputation >= 1 AND Reputation <= 2000000 );
When we run this query, our newly created and trusted constraint should let it bail out without doing any work.
SELECT u.DisplayName, u.Age, u.Reputation
FROM dbo.Users AS u
WHERE u.Reputation = 0;
But two things happen:

The plan is trivial, and it’s auto-parameterized.
The auto-parameterization means a plan is chosen where the literal value 0 is replaced with a parameter by SQL Server. This is normally “okay”, because it promotes plan reuse. However, in this case, the auto-parameterized plan has to be safe for any value we pass in. Sure, it was 0 this time, but next time it could be one within the range of valid reputations.
Since we don’t have an index on Reputation, we have to read the entire table. If we had an index on Reputation, it would still result in a lot of extra reads, but I’m using the clustered index here for ~dramatic effect~
Table 'Users'. Scan count 1, logical reads 44440
Of course, adding the 1 = (SELECT 1) thing to the end introduces full optimization, and prevents this.
The query plan without it is just a constant scan, and it does 0 reads.
Rounding Down
So there you have it. When you see me (or anyone else) use 1 = (SELECT 1), this is why. Sometimes when you write demos, a trivial plan or auto-parameterization can mess things up. The easiest way to get around it is to add that to the end of a query.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Such a trivial post 😀 (Great read by the way)
All my posts are trivial, it’s the only way for me to write five a week, hahaha.
Great Post, ERIK!
Really nice explanation all ’round!
Thanks, Max!
Great Post! Very useful information and well explained!
There’s a first time for everything 🙂