Upon upgrading to SQL Server 2019 CTP2, you may see the new SOS_WORK_DISPATCHER wait type at the top of the list:
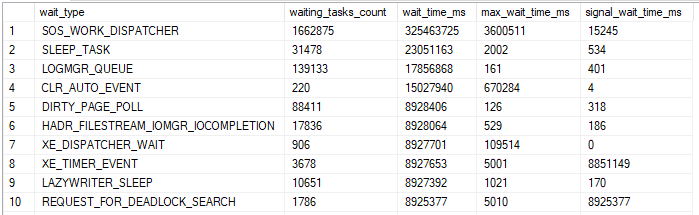
The above screenshot is server level wait stats from my four core desktop after SQL Server was running for a few hours. SQL Server wasn’t really doing much since start up, so it felt unlikely that this wait was a sign of a problem. However, I was curious about what this wait type meant and wanted to know more.
A Call to Call Stacks
One of the few good things to come out of twitter was an announcement that public symbols are now available for SQL Server 2019 CTP2:
Public PDB symbols for #SQLServer 2019 CTP 2.0 are now available! Updated instructions on the #SQLCallStackResolver Wiki at https://t.co/JTHYp1HvHF CC @SQL_Kiwi
— Arvind Shyamsundar (@arvisam) September 26, 2018
I for one appreciate the new, more open, Microsoft. Access to public symbols makes investigating unknown wait times significantly easier. Further helping the cause is the fact that the new wait type happens many times a second even when you aren’t doing anything in SQL Server. It was fairly easy to get call stacks for the wait using TF 3656, which is generally not recommended in production. Here is one example:
sqldk.dll!XeSosPkg::wait_info::Publish+0x1a9
sqldk.dll!SOS_Task::PreWait+0x14b
sqldk.dll!WaitableBase::Wait+0x183
sqldk.dll!WorkDispatcher::DequeueTask+0x5de
sqldk.dll!SOS_Scheduler::ProcessTasks+0x234
sqldk.dll!SchedulerManager::WorkerEntryPoint+0x2a1
sqldk.dll!SystemThread::RunWorker+0x91
sqldk.dll!SystemThreadDispatcher::ProcessWorker+0x2f3
sqldk.dll!SchedulerManager::ThreadEntryPoint+0x1e5
KERNEL32.DLL!BaseThreadInitThunk+0x14
ntdll.dll!RtlUserThreadStart+0x21
That’s a pretty short stack. The wait begins immediately after a task is dequeued. This made me think that workers start the wait when they don’t have a task to run and complete the wait once they do have a task to run, but this is hardly proof, since I’m just guessing at what this call stack means.
Just Add More Extended Events
From the call stack it seems reasonable to conclude that tasks are somehow related to the wait type. There are a handful of debug channel task related events available in extended events: task_completed, task_enqueued, and task_started. Debug extended events can be a pain because they often have no documentation, but these seemed straightforward enough. The event_counter target revealed very obvious collusion between the events:
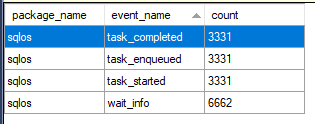
The wait_info extended event fires once for when a wait starts and once for when it completes. Every time I looked I had exactly twice as many events for wait_info as I did for each task-related extended event. Below is an instructive example from the event file. Note that the duration for the wait_info event is measured in milliseconds but the duration for the task event is measured in microseconds.
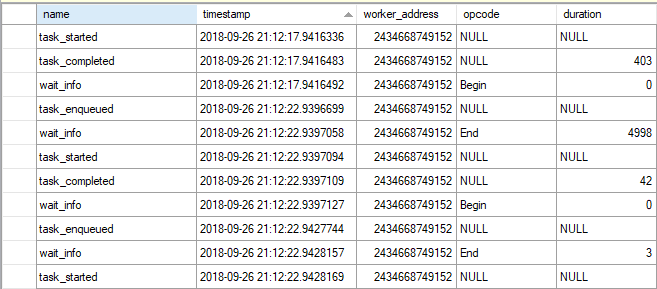
For worker 2434668749152, a task completed at 21:12:17.9416483. A wait type of SOS_WORK_DISPATCHER immediately began. About five seconds later, a task was enqueued to this worker. The SOS_WORK_DISPATCHER wait immediately ends after the task was enqueued, with a reported wait duration of 4998 ms. The task starts at 21:12:22.9397094 and completes at 21:12:22.9397109. Once again, a wait type of SOS_WORK_DISPATCHER immediately starts at 21:12:22.9397127. This time another task is very quickly enqueued at 21:12:22.9427744, so the wait ends with a duration of just 3 ms.
There are many similar patterns in the event file. I consider this to be pretty strong evidence that the SOS_WORK_DISPATCHER wait measures time that a worker sits idle without a task to run. It is common for systems to have many idle workers, so seeing a lot of wait time for SOS_WORK_DISPATCHER is normal and not cause for concern.
Robots are Taking Over
It is not clear to me why someone would be interested in this wait type. SQL Server automatically manages workers and creates and destroys them as needed. It’s true that as a query tuner I have some control over how many additional threads will be needed for a query, but if I’m investigating a performance or scalability problem I don’t care at all about the amount of time workers are sitting idle without a task to run. My wild guess is that this wait type was added to do some kind of tracking in Azure. Perhaps the robots needed some additional information to train a model.
Final Thoughts
In summary, the SOS_WORK_DISPATCHER wait type represents a sum of the total time for workers that don’t have tasks assigned to them. This appears to be a benign wait that can be filtered out of any queries on wait stats queries. When I first saw this wait type, I was hoping that it was some sort of representation of CPU idle time. I often work on workloads for which the goal is to push the server as hard as possible, so a simple measurement of total CPU idle time would be extremely useful for me. The number of workers on a system will change during a workload and there are lots of internal tasks, so sadly this wait type can’t be used for that type of analysis.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.