They Live
I’m not sure why scans got such a bad rap. Perhaps it’s a leftover from the Bad Old Days© when people worried about logical fragmentation and page splits.
What I mean to say is: scans are often treated with a level of revulsion and focus that distracts people from larger issues, and is often due to some malpractice on their part.
Sure, scans can be bad. Sometimes you do need to fix them. But make that decision when you’re looking at an actual execution plan, and not just making meme-ish guesses based on costs and estimates.
You’re better than that.
It Follows
Let’s start with a simple query:
SELECT TOP (1)
p.*
FROM dbo.Posts AS p;
There’s no where clause, no join, and we’ll get a scan, but it’s driven by the TOP.
If we get look at the actual execution plan, and hit F4/get the Properties of the clustered index scan, we’ll see it does a minimal number of reads.
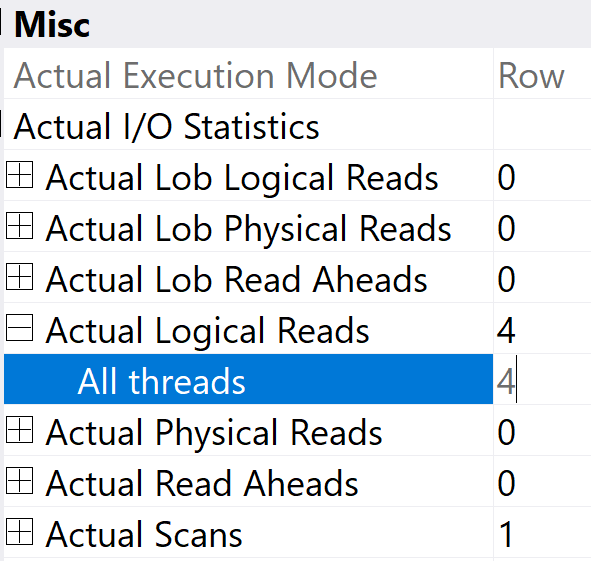
The four reads to get a single row are certainly not the number of reads it would take to read this entire Posts table.
The reason it’s not 1 read is because the Posts table contains the nvarchar(max) Body column, which leads to reading additional off row/LOB pages.
C.H.U.D
Let’s look at a situation where you might see a clustered index scan(!), a missing index request(!), and think you’ll have the problem solved easily(!), but… no.
SELECT TOP (1000)
u.DisplayName,
p.Score,
_ = dbo.InnocentScan(p.OwnerUserId)
FROM dbo.Posts AS p
JOIN dbo.Users AS u
ON p.OwnerUserId = u.Id
WHERE p.Score = 1
ORDER BY p.Id;
Costs are really wacky sometimes. Like here.
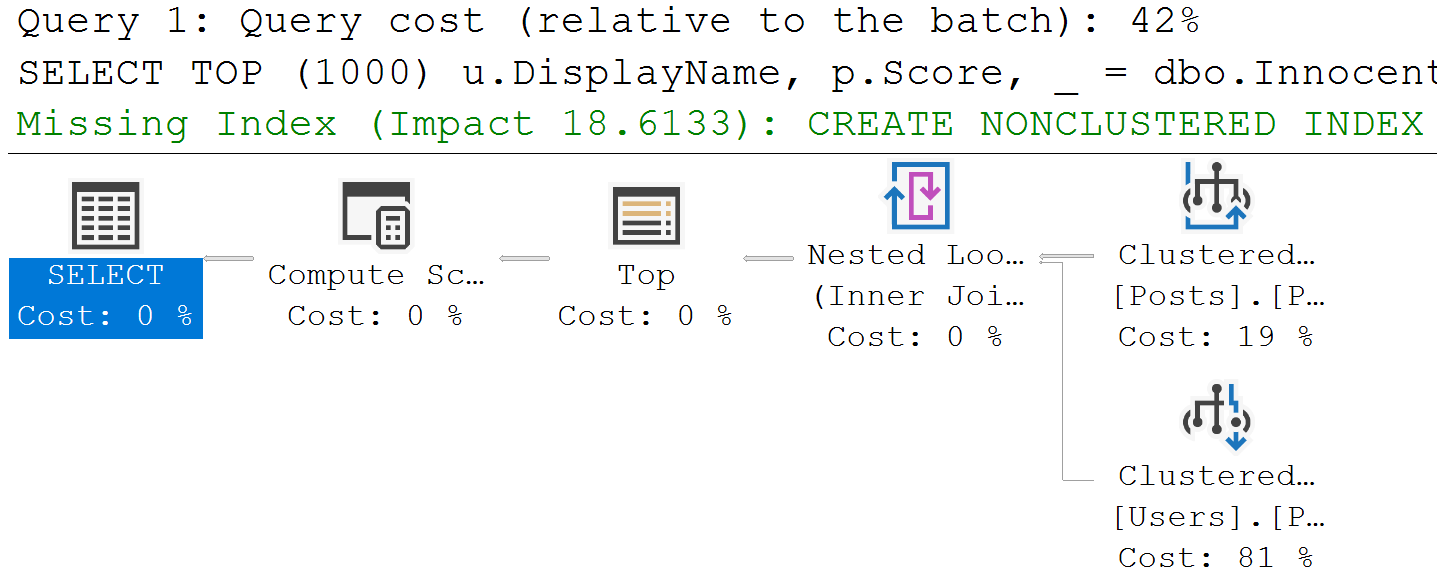
In this really unhelpful query plan (thanks, SSMS, for not showing what the clustered thing is), we have:
- A clustered index scan of Posts
- A clustered index seek of Users
The optimizer tells us that adding an index will reduce the estimated effort needed to execute the query by around 18%. Mostly because the estimated effort needed to scan the clustered index is 19% of the total operator costs.
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[Posts] ([Score]) INCLUDE ([OwnerUserId])
Got it? Missing index requests don’t care about joins.
Geistbusters
If one were to look at the actual execution plan, one may come to the conclusion that an index here would not solve a gosh. darn. thing.
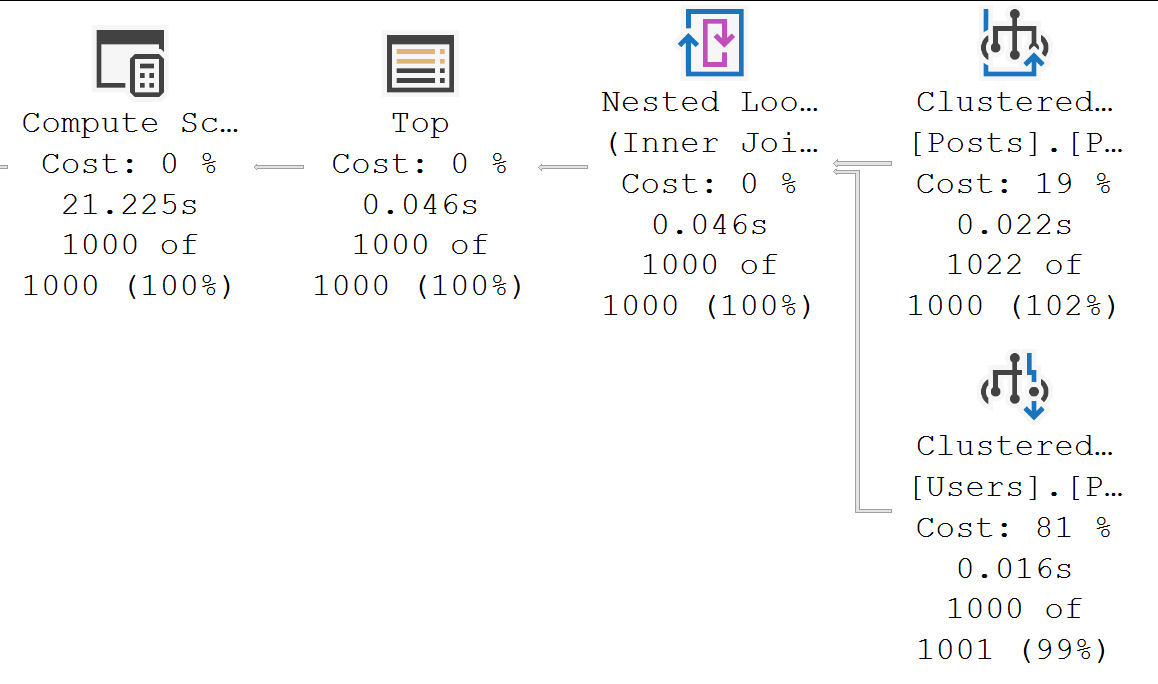
21 seconds is spent in the operator that costs 0%, and less than 40 milliseconds is spent between the two operators that make up 100% of the plan cost.
Very sad for you if you thought that missing index request would solve all your problems.
What About Scans?
I know, the title of this post is about retrieving data via an index scan, but we ended up talking about how scans aren’t always the root of performance issues.
It ended up that way because as I was writing this, I had to help a client with an execution plan where the problem had nothing to do with a clustered index scan that they were really worried about.
To call back to a few other points about things I’ve made so far in this series:
- The operator times in actual execution plans are the most important thing for you to look at
- If you’re not getting a seek when you think you should, ask yourself some questions:
- Do I have an index that I can actually seek to data in?
- Do I have a query written to take advantage of my indexes?
If you’re not sure, hit the link below. This is the kind of stuff I love helping folks out with.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
One thought on “Understand Your Plan: Getting Data With A Scan Operator”
Comments are closed.