Lamp
This issue is one that could be linked to other times when the optimizer defers certain portions of optimization to later stages. It’s also something that could lead to complications, because the end result is multiple execution plans for the same query.
But it goes back to a couple basic approaches to query writing that I think people need to keep in mind: write single purpose queries, and things that make your job easier make the optimizer’s job harder.
A good example of a multi-purpose query is a merge statement. It’s like throwing SQL Server a knuckleball.
Fiji
Another example of a knuckleball is this knucklehead pattern:
SELECT
p.*
FROM dbo.Posts AS p
WHERE (p.OwnerUserId = @OwnerUserId OR @OwnerUserId IS NULL)
AND (p.CreationDate >= @CreationDate OR @CreationDate IS NULL);
SELECT
p.*
FROM dbo.Posts AS p
WHERE (p.OwnerUserId = ISNULL(@OwnerUserId, p.OwnerUserId))
AND (p.CreationDate >= ISNULL(@CreationDate, p.CreationDate));
GO
SELECT
p.*
FROM dbo.Posts AS p
WHERE (p.OwnerUserId = COALESCE(@OwnerUserId, p.OwnerUserId))
AND (p.CreationDate >= COALESCE(@CreationDate, p.CreationDate))
ORDER BY p.Score DESC;
GO
I hate seeing this, because I know how many bad things can happen as a result of this.
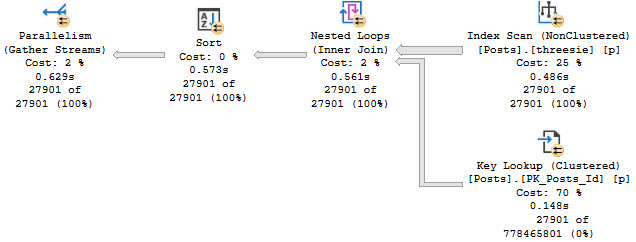
One example I love is creating these two indexes and running the first query up there.
CREATE INDEX onesie ON dbo.Posts(OwnerUserId, Score, CreationDate); CREATE INDEX threesie ON dbo.Posts(ParentId, OwnerUserId);
The optimizer chooses the wrong index — the one that starts with ParentId — even though the query is clearly looking for a potential equality predicate on OwnerUserId.
Deferential
It would be nice if the optimizer did more to sniff out NULL values here to come up with more stable plans for the non-NULL values, essentially doing the job that dynamic SQL does by only adding predicates to the where clause when they’re not NULL.
It doesn’t have to look further at actual values on compilation, because that’s essentially a RECOMPILE hint on every query.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Related Posts
- Things SQL Server vNext Should Address: How Did I Do?
- Things SQL Server vNext Should Address: Add Lock Pages In Memory To Setup Options
- Things SQL Server vNext Should Address: Add Cost Threshold For Parallelism To Setup Options
- Changes Coming To SQL Server’s STRING_SPLIT Function: Optional Ordinal Position