Grey Matter
Often when query tuning, I’ll try a change that I think makes sense, only to have it backfire.
It’s not that the query got slower, it’s that the results that came back were wrong different.
Now, this can totally happen because of a bug in previously used logic, but that’s somewhat rare.
And wrong different results make testers nervous. Especially in production.
Here’s a Very Cheeky™ example.
Spread’em
This is my starting query. If I run it enough times, I’ll get a billion missing index requests.
WITH topusers AS
(
SELECT TOP (1)
u.Id, u.DisplayName
FROM dbo.Users AS u
ORDER BY u.Reputation DESC
)
SELECT u.Id,
u.DisplayName,
SUM(p.Score * 1.0) AS PostScore,
SUM(c.Score * 1.0) AS CommentScore,
COUNT_BIG(*) AS CountForSomeReason
FROM topusers AS u
JOIN dbo.Posts AS p
ON p.OwnerUserId = u.Id
JOIN dbo.Comments AS c
ON c.UserId = u.Id
WHERE p.Score >= 5
AND c.Score >= 1
GROUP BY u.Id, u.DisplayName;
For the sake of argument, I’ll add them all. Here they are:
CREATE INDEX ix_tabs
ON dbo.Users ( Reputation DESC, Id )
INCLUDE ( DisplayName );
CREATE INDEX ix_spaces
ON dbo.Users ( Id, Reputation DESC )
INCLUDE ( DisplayName );
CREATE INDEX ix_coke
ON dbo.Comments ( Score) INCLUDE( UserId );
CREATE INDEX ix_pepsi
ON dbo.Posts ( Score ) INCLUDE( OwnerUserId );
CREATE NONCLUSTERED INDEX ix_tastes_great
ON dbo.Posts ( OwnerUserId, Score );
CREATE NONCLUSTERED INDEX ix_less_filling
ON dbo.Comments ( UserId, Score );
With all those indexes, the query is still dog slow.
Maybe It’s Me
I’ll take my own advice. Let’s break the query up a little bit.
DROP TABLE IF EXISTS #topusers;
WITH topusers AS
(
SELECT TOP (1)
u.Id, u.DisplayName
FROM dbo.Users AS u
ORDER BY u.Reputation DESC
)
SELECT *
INTO #topusers
FROM topusers;
CREATE UNIQUE CLUSTERED INDEX ix_whatever
ON #topusers(Id);
SELECT u.Id,
u.DisplayName,
SUM(p.Score * 1.0) AS PostScore,
SUM(c.Score * 1.0) AS CommentScore,
COUNT_BIG(*) AS CountForSomeReason
FROM #topusers AS u
JOIN dbo.Posts AS p
ON p.OwnerUserId = u.Id
JOIN dbo.Comments AS c
ON c.UserId = u.Id
WHERE p.Score >= 5
AND c.Score >= 1
GROUP BY u.Id, u.DisplayName;
Still dog slow.
Variability
Alright, I’m desperate now. Let’s try this.
DECLARE @Id INT,
@DisplayName NVARCHAR(40);
SELECT TOP (1)
@Id = u.Id,
@DisplayName = u.DisplayName
FROM dbo.Users AS u
ORDER BY u.Reputation DESC;
SELECT @Id AS Id,
@DisplayName AS DisplayName,
SUM(p.Score * 1.0) AS PostScore,
SUM(c.Score * 1.0) AS CommentScore,
COUNT_BIG(*) AS CountForSomeReason
FROM dbo.Posts AS p
JOIN dbo.Comments AS c
ON c.UserId = p.OwnerUserId
WHERE p.Score >= 5
AND c.Score >= 1
AND (c.UserId = @Id OR @Id IS NULL)
AND (p.OwnerUserId = @Id OR @Id IS NULL);
Let’s get some worst practices involved. That always goes well.
Except here.
Getting the right results seemed like it was destined to be slow.
Differently Resulted
At this point, I tried several rewrites that were fast, but wrong.
What I had missed, and what Joe Obbish pointed out to me, is that I needed a cross join and some math to make it all work out.
WITH topusers AS
(
SELECT TOP (1)
u.Id, u.DisplayName
FROM dbo.Users AS u
ORDER BY u.Reputation DESC
)
SELECT t.Id AS Id,
t.DisplayName AS DisplayName,
p_u.PostScoreSub * c_u.CountCSub AS PostScore,
c_u.CommentScoreSub * p_u.CountPSub AS CommentScore,
c_u.CountCSub * p_u.CountPSub AS CountForSomeReason
FROM topusers AS t
JOIN ( SELECT p.OwnerUserId,
SUM(p.Score * 1.0) AS PostScoreSub,
COUNT_BIG(*) AS CountPSub
FROM dbo.Posts AS p
WHERE p.Score >= 5
GROUP BY p.OwnerUserId ) AS p_u
ON p_u.OwnerUserId = t.Id
CROSS JOIN ( SELECT c.UserId, SUM(c.Score * 1.0) AS CommentScoreSub, COUNT_BIG(*) AS CountCSub
FROM dbo.Comments AS c
WHERE c.Score >= 1
GROUP BY c.UserId ) AS c_u
WHERE c_u.UserId = t.Id;
This finishes instantly, with the correct results.
The value of a college education!
Realizations and Slowness
After thinking about Joe’s rewrite, I had a terrible thought.
All the rewrites that were correct but slow had gone parallel.
“Parallel”
Allow me to illustrate.
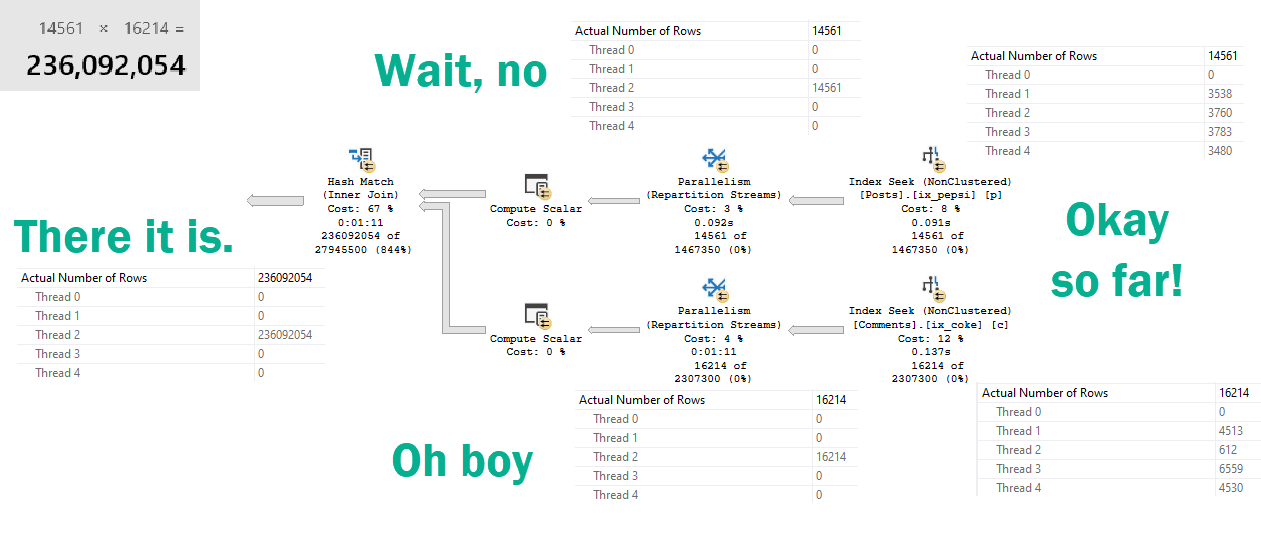
Repartition Streams usually does the opposite.
But here, it puts all the rows on a single thread.
“For correctness”
Which ends up in a 236 million row parallel-but-single-threaded-cross-hash-join.
Summary Gates Are On My Side
Which, of course, is nicely summarized by P. White.
SQL Server uses the correct join (inner or outer) and adds projections where necessary to honour all the semantics of the original query when performing internal translations between apply and join.
The differences in the plans can all be explained by the different semantics of aggregates with and without a group by clause in SQL Server.
What’s amazing and frustrating about the optimizer is that it considers all sorts of different ways to rewrite your query.
In milliseconds.
It may have even thought about a plan that would have been very fast.
But we ended up with this one, because it looked cheap.
Untuneable
The plan for Joe’s version of the query is amazingly simple.
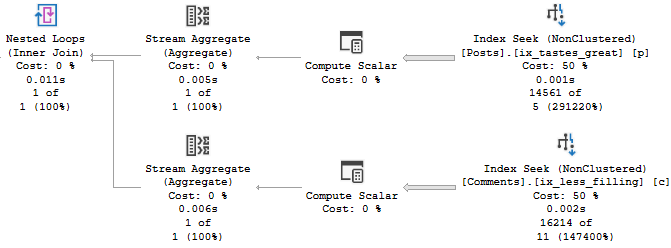
Sometimes giving the optimizer a different query to work with helps, and sometimes it doesn’t.
Rewriting queries is tough business. When you change things and still get the same plan, it can be really frustrating.
Just know that behind the scenes the optimizer is working hard to rewrite your queries, too.
If you really want to change the execution plan you end up with, you need to present the logic to the optimizer in different ways, and often with different indexes to use.
Other times, you just gotta ask Joe.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
One thought on “The Hardest Part Of SQL Server Query Tuning: Getting The Right Results”
Comments are closed.