Locality
Every action has some latency attached to it. Depending on how far you have to go, it could be a lot or a little.
And of course, it also depends on some situations you might run into along the way.
That’s one reason why batch mode can introduce such a performance improvement: CPU instructions are run on batches of rows at a time local to the CPU, rather than a single row at a time. Less fetching is generally a good thing. Remember all those things they told you about cursors and RBAR?
For years, I’ve been sending people over to this post by Jeff Atwood, which does a pretty good job of describing those things.
But you know, I need something a little more specific to SQL Server, and using a slightly different metric: We’re gonna assign $Query Bucks$ to those latencies.
After all, time is money.
Gold Standard
Using a similar formula to Jeff’s, let’s look at how expensive it gets once you cross from memory to disk.
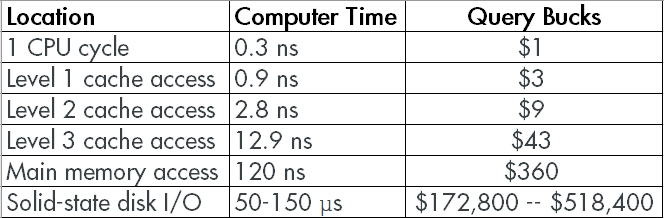
See the end there, when you jump from nanoseconds to microseconds? At those prices, you start to understand why people like me tell you to solve problems with more memory instead of faster disks. Those numbers are for local storage, of course, and main memory is still leaving Road Runner clouds around it.
If you’re on a SAN — and I don’t mean that SAN disks are slower; they’re not — you have something else to think about.
What I mean is the component in between that can be a real problem: The N in SAN. The Network.
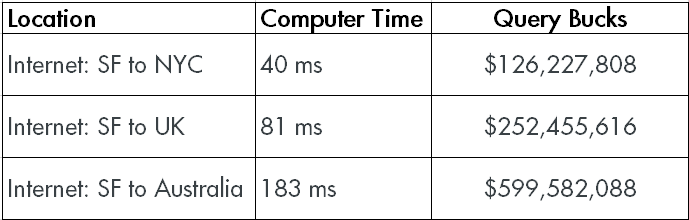
If you add latency in just the milliseconds, costs pretty quickly jump up into numbers that’d make athletes blush. And if you’ve ever seen those 15 second I/O warnings in the error log…
This is where a lot of people under-provision themselves into nightmare. 10Gb Ethernet connections can move data fairly quickly, at around 1.2 GB/s. Which is great for data that’s easily accounted for in 100s of MB. It’s less great for much bigger data, and it’s worse when there’s a lot of other traffic on the same network.
Sensitivity
Competition for these resources, which is really common for database workloads that often have multiple queries all reading and writing data simultaneously, can take what would be an otherwise fine SAN and make it look like a tarpit.
You have to be really careful about these things, and how you choose to address them when you’re dealing with SQL Server.
Standard Edition is in particularly rough shape, with the buffer pool being a laughable 128GB. In order to keep things tidy, your indexes really need to be spot on, so you don’t have unnecessary things ending up there.
The more critical a workload is, the more you have riding on getting things right, which often means getting these numbers as low as possible.
Hardware that’s meant to help businesses consolidate isn’t always set up (or designed) to put performance first. Once you start attaching prices to those decisions that show how much time they can cost your workloads is a good way to start making better decisions.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.