Bestest
If we want to start this post in the right place, we have to go back to 2009. That was the first time a (much) young(er) Erik Darling wrote dynamic SQL that didn’t suck.
There was a terrible piece of SSRS report code that used the standard catch-all pattern repeated over most of a dozen columns: (a.col = @a_parameter OR @a_parameter IS NULL)
I neither pioneered the non-sucky dynamic SQL approach, nor did I end up solving the problem entirely just by implementing non-sucky dynamic SQL. I did get things most of the way there, but every so often something bad would still happen:
- I’d hit the ascending key problem
- I’d hit a parameter sniffing problem
At no point did I stop, take a deep breath, and just use a recompile hint on this piece of code that would run every 6-8 hours at most.
I was obsessed. I was possessed. I had to do things the right way.
But the right way didn’t always give me the best results, and I had a bad case of Egg-On-Face syndrome from swearing that I did things the right way but still ended up with a bad result.
Not all the time, but when it happened I’d get just as much guff as when things were always bad.
Goodie Howser
Good dynamic SQL and good stored procedures can suffer from the same issue: Parameter Sensitivity.
- Plan A works great for Parameter A
- Plan A does not work great for Parameter B
- Plan B works great for Parameter B
- Plan B does not work great for Parameter A
And so on. Forever. Until the dragons return. Which, you know, any day now would be great 🤌
In our quest to solve the problems with IF branching, we’ve tried a lot of things. Most of them didn’t work. Stored procedures worked for the most part, but we’ve still got a problem.
A parameter sensitivity problem.
The problem within stored procedures is a lot like the problems we saw with IF branches in general: the optimizer can’t ever pause to take a breath and make better decisions.
It would be nice if the concept of deferred name resolution had a deeper place in plan creation that would allow for deferred query optimization when IF branch boundaries are involved.
Instead, we’ll probably just keep getting different ways to work with JSON.
Looking forward to FOR YAML PATH queries, too.
Toothsome
The lovely part about dynamic SQL is that you get to construct your own query, and you can take what you know about data distributions to construct different queries.
You know all the Intelligent Query Processing and Adaptive doodads and gizmos galore that the optimizer is getting added to it? You could have been the optimizer all along.
But you were too busy rebuilding indexes and other memes that don’t bear mentioning at this late date.
We still need to write dynamic SQL the right way, but we also need to offer the optimizer a way to understand that while every parameter is created equally, not all data distributions are.
In other words, we need to give it some room to breathe.
But here I am meandering again. Let’s get on to the SQL.
Grim
I’m going to use the example from yesterday’s post to show you what you can do to further optimize queries like this.
To make the code fit in the post a little better, I’m going to skip the IF branch for the Posts table and go straight to Votes. Using dynamic SQL here will get you the same behavior at stored procedures, though.
CREATE OR ALTER PROCEDURE
dbo.counter_if_dynamic
(
@PostTypeId int = NULL,
@VoteTypeId int = NULL,
@CreationDate datetime = NULL
)
AS
SET NOCOUNT, XACT_ABORT ON;
BEGIN
DECLARE
@sql nvarchar(4000) = N'',
@posts_parameters nvarchar(4000) = N'@PostTypeId int, @CreationDate datetime',
@votes_parameters nvarchar(4000) = N'@VoteTypeId int, @CreationDate datetime';
/*
Cutting out the Posts query for brevity.
This will behave similarly to stored procedures
in separating the execution plan creation out.
*/
IF @VoteTypeId IS NOT NULL
BEGIN
SELECT
@sql += N'
/*dbo.counter_if_posts*/
SELECT
c = COUNT_BIG(*)
FROM dbo.Posts AS p
JOIN dbo.Votes AS v
ON p.Id = v.PostId
WHERE v.VoteTypeId = @VoteTypeId
AND v.CreationDate >= @CreationDate
'
IF @VoteTypeId IN
(2, 1, 3, 5, 10, 6, 16, 15, 11, 8)
BEGIN
SELECT
@sql +=
N'AND 1 = (SELECT 1);'
END;
ELSE
BEGIN
SELECT
@sql +=
N'AND 2 = (SELECT 2);'
END;
EXEC sys.sp_executesql
@sql,
@votes_parameters,
@VoteTypeId,
@CreationDate;
END;
END;
GO
I determined which values to assign to each branch by grabbing a count from the Votes table. You could theoretically automate this a bit by dumping the count into a helper table, and updating it every so often to reflect current row counts.
You’re essentially building your own histogram by doing that, which for this case makes sense because:
- There’s a limited range of values to store and evaluate for an equality predicate
- Getting the count is very fast, especially if you get Batch Mode involved
I basically ran the proc with recompile hints to see at which row threshold for the VoteTypeId filter I’d tip between Nested Loops and Hash Joins, which is what bit us yesterday.
Running Wild
Let’s compare these two runs!
DBCC FREEPROCCACHE
GO
EXEC dbo.counter_if_dynamic
@PostTypeId = NULL,
@VoteTypeId = 7,
@CreationDate = '20080101';
GO
EXEC dbo.counter_if_dynamic
@PostTypeId = NULL,
@VoteTypeId = 2,
@CreationDate = '20080101';
GO
Here’s what happens:
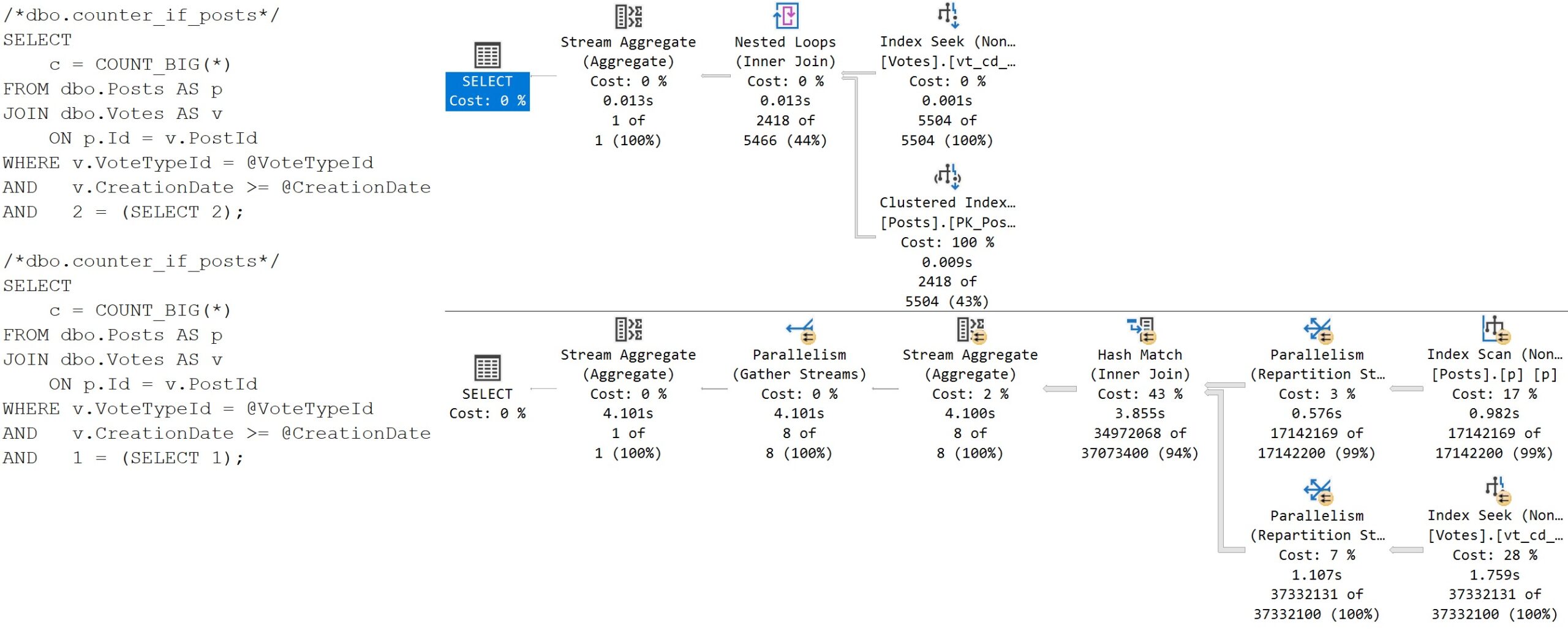
For this example, we can consider this separation good enough.
D-Rive
Perhaps the larger point behind this series would be that multi-purpose stored procedures are a pretty bad idea. In many cases they’re completely avoidable, but in others the queries are similar-enough that grouping them into one proc makes sense at first glance.
If you’re going to do this, you need to be prepared to provide some additional separation for each query, or at least each branch of the logic.
Stored procedures can provide a reasonable amount of shelter, but you can still encounter parameter sensitivity issues.
In the end, using parameterized dynamic SQL allows you to generate queries that are just different enough without changing the logic of the query so that the optimizer spits out different query plans for them.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Related Posts
- SQL Server 2022 Parameter Sensitive Plan Optimization: How PSP Can Help Some Queries With IF Branches
- SQL Server IF Branches And Query Performance Part 4: Do Stored Procedures Work?
- SQL Server IF Branches And Query Performance Part 3: Local Variables Still Suck
- SQL Server IF Branches And Query Performance Part 2: Trying To Fix Parameters Doesn’t Work
Hi, Erik!
Thanks, great post. Could you please clarify this part:
IF @VoteTypeId IN
(2, 1, 3, 5, 10, 6, 16, 15, 11, 8)
BEGIN
SELECT
@sql +=
N’AND 1 = (SELECT 1);’
END;
ELSE
BEGIN
SELECT
@sql +=
N’AND 2 = (SELECT 2);’
END;
Can you clarify what you need clarified because I think I clarified that in the main post.
If we slightly rewrite the part of the code just for the simplicity of clarifying (I understand the difference between the dynamic SQL and the simple Select) we get this:
IF @VoteTypeId IS NOT NULL
BEGIN
IF @VoteTypeId IN
(2, 1, 3, 5, 10, 6, 16, 15, 11, 8)
Begin
SELECT
c = COUNT_BIG(*)
FROM dbo.Posts AS p
JOIN dbo.Votes AS v
ON p.Id = v.PostId
WHERE v.VoteTypeId = @VoteTypeId
AND v.CreationDate >= @CreationDate
AND 1 = (SELECT 1);
Else
SELECT
c = COUNT_BIG(*)
FROM dbo.Posts AS p
JOIN dbo.Votes AS v
ON p.Id = v.PostId
WHERE v.VoteTypeId = @VoteTypeId
AND v.CreationDate >= @CreationDate
AND 2 = (SELECT 2);
End
End
This part seems to me unclarified unclarity. I don’t get the point of such an IF.
I think you need to start at the beginning of the series, to be honest. I answered this throughout.
I’ve read 4 previous posts and all of them are great. The multi-purpose stored procedures are a pretty bad idea but they are very common. A project manager wants one API method with thousand parameters and all of them can be null.
As I understand with this Where trick AND 1 = (SELECT 1) or AND 2 = (SELECT 2) you force the optimizer to make two different plans for the same select: the first plan for the @VoteTypeId in (2, 1, 3, 5, 10, 6, 16, 15, 11, 8) and rows count for these IDs are pretty similar. And the second plan for others @VoteTypeId with other similar rows count. Am I right?
Yep, you got it!
Rather than constructing a histogram, would it make sense to query the histogram the query optimiser has built?
eg.
IF @VoteTypeId IN (
SELECT top 5 hist.range_high_key
FROM sys.stats AS s
CROSS APPLY sys.dm_db_stats_histogram(s.[object_id], s.stats_id) AS hist
WHERE s.[name] = N’_WA_Sys_00000005_0BC6C43E’
and distinct_range_rows = 0
order by equal_rows desc, range_high_key)
Yeah, totally, if you know which stats object the optimizer is currently using and always going to use for cardinality estimation.
Hard coding stuff like that makes me a little nervous!