Yep, I know
It’s the first public CTP. Things will change. Things will get better. Think about the rich history of Microsoft fixing stuff immediately, like with adding an ordinal position to STRING_SPLIT.
That came out in SQL Server 2016, and uh… Wait, they just added the ordinal position in SQL Server 2022. There were two major versions in between that function getting released and any improvements.
With that in mind, I’m extending as much generosity of spirit to improvements to the function at hand: GENERATE_SERIES.
Quite a while back, I blogged about how much I’d love to have this as a function. We… sort of got it. It doesn’t do dates natively, but you can work around some of that with date functions.
In this post, I want to go over some of the disappointing performance issues I found when testing this function out.
Single Threaded In A Parallel Plan
First up, reading streaming results from the function is single threaded. That isn’t necessarily bad on its own, but can result in annoying performance issues when you have to distribute a large number of rows.
If you have to ask what the purpose or use case for 10 million rows is, it’s your fault that SQL Server doesn’t scale.
Got it? Yours, and yours alone.
DROP TABLE IF EXISTS
dbo.art_aux;
CREATE TABLE
dbo.art_aux
(
id int NOT NULL PRIMARY KEY CLUSTERED
);
The first way we’re going to try this is with a simple one column table that has a primary key/clustered index on it.
Of course, we won’t expect a parallel insert into the table itself because of that index, but that’s okay. For now.
INSERT INTO
dbo.art_aux WITH(TABLOCK)
(
id
)
SELECT
gs.value
FROM GENERATE_SERIES
(
START = 1,
STOP = 10000000
) AS gs
OPTION(MAXDOP 8);
The query plan for this insert looks about like so:
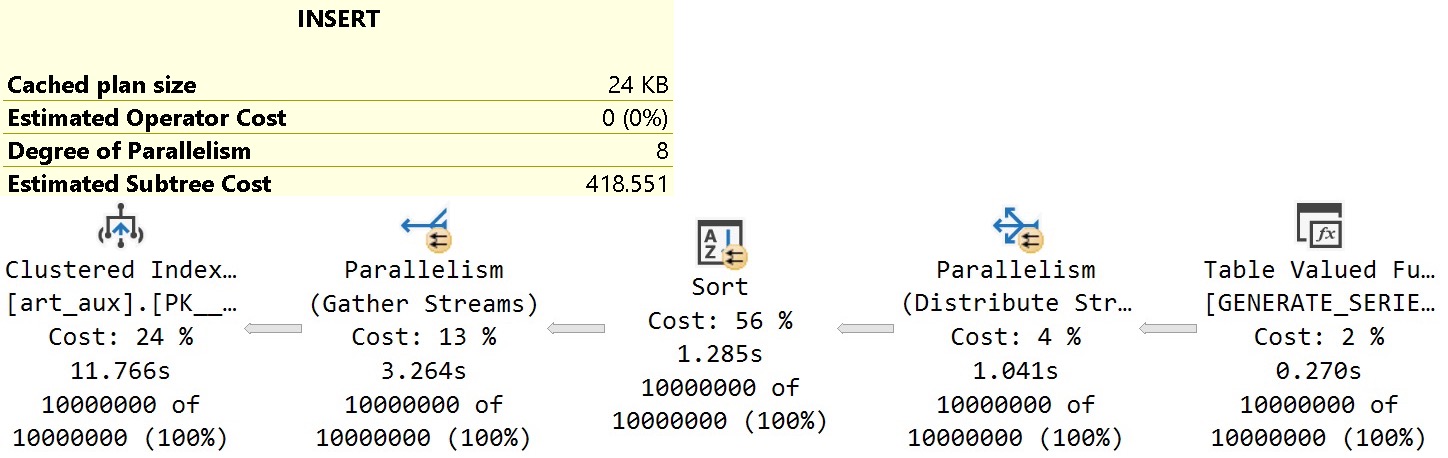
I’m only including the plan cost here to compare it to the serial plan later, and to understand the per-operator cost percentage breakdown.
It’s worth noting that the Distribute Streams operator uses Round Robin partitioning to put rows onto threads. That seems an odd choice here, since Round Robin partitioning pushes packets across exchanges.
For a function that produces streaming integers, it would make more sense to use Demand partitioning which only pulls single rows across exchanges. Waiting for Round Robin to fill up packets with integers seems a poor choice, here.
Then we get to the Sort, which Microsoft has promised to fix in a future CTP. Hopefully that happens! But it may not help with the order preserving Gather Streams leading up to the Insert.

It seems a bit odd ordered data from the Sort would hamstring the Gather Streams operator’s ability to do its thing, but what do I know?
I’m just a bouncer, after all.
But The Serial Plan
Using the same setup, let’s make that plan run at MAXDOP 1.
INSERT INTO
dbo.art_aux WITH(TABLOCK)
(
id
)
SELECT
gs.value
FROM GENERATE_SERIES
(
START = 1,
STOP = 10000000
) AS gs
OPTION(MAXDOP 1);
You might expect this to run substantially slower to generate and insert 10,000,000 rows, but it ends up being nearly three full seconds faster.
Comparing the query cost here (1048.11) vs. the cost of the parallel plan above (418.551), it’s easy to understand why a parallel plan was chosen.
It didn’t work out so well, though, in this case.
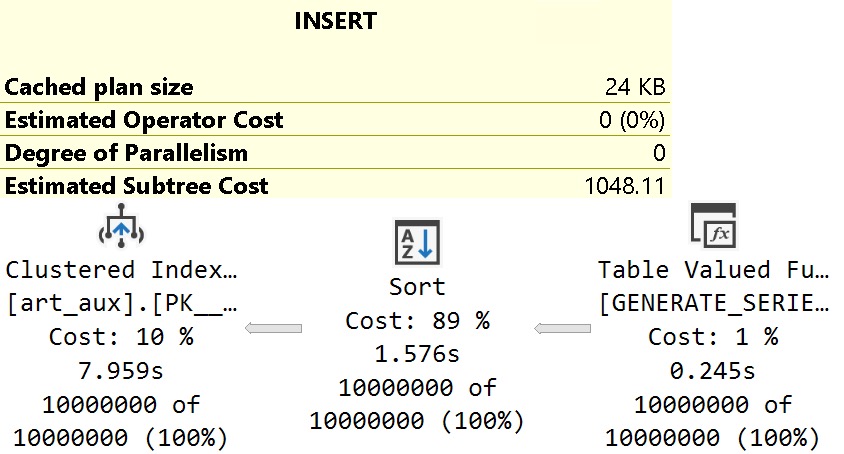
With no need to distribute 10,000,000 rows out to 8 threads, sort the data, and then gather the 8 threads back to one while preserving that sorted order, we can rely on the serial sort operator to produce and feed rows in index-order to the table.
Hopefully that will continue to be the case once Microsoft addresses the Sort being present there in the first place. That would knock a second or so off the the overall runtime.
Into A Heap
Taking the index out of the picture and inserting into a heap does two things:
- Removes the need for sorted results
- Removes restrictions around a fully parallel insert
But it also… Well, let’s just see what happens. And talk about it. Query plans need talk therapy, too. I’m their therapist.
DROP TABLE IF EXISTS
dbo.art_aux;
CREATE TABLE
dbo.art_aux
(
id int NOT NULL
);
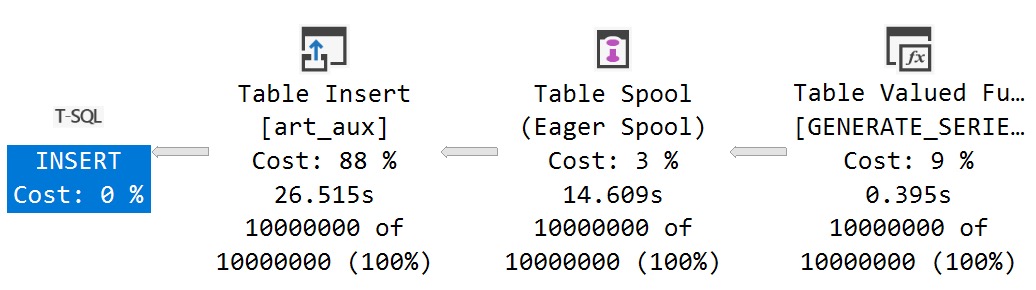
The Eager Table Spool here is for halloween protection, I’d wager. Why we need it is a bit of a mystery, since we’re guaranteed to get a unique, ever-increasing series of numbers from the function. On a single thread.
Performance is terrible here because spooling ten million rows is an absolute disaster under any circumstance.
With this challenge in mind, I tried to get a plan here that would go parallel and avoid the spool.
Well, mission accomplished. Sort of.
Crash And Burn
One thing we can do is use SELECT INTO rather than relying on INSERT SELECT WITH (TABLOCK) to do try to get it. There are many restrictions on the latter method.
SELECT
id =
gs.value
INTO dbo.select_into
FROM GENERATE_SERIES
(
START = 1,
STOP = 10000000
) AS gs
OPTION(MAXDOP 8);
This doesn’t make things better:
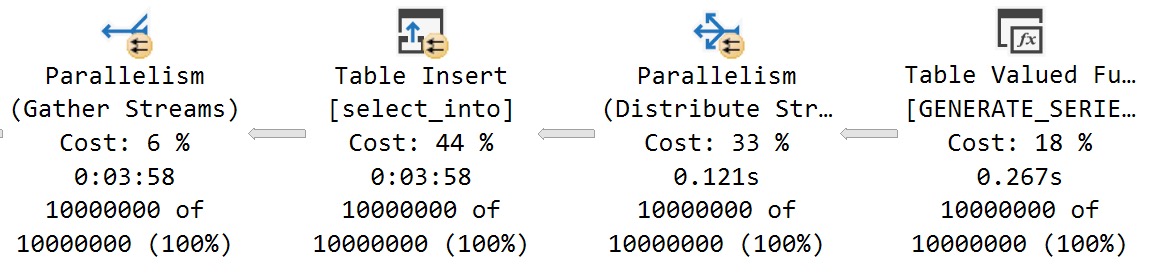
This strategy clearly didn’t work out.
Bummer.
Again, I’d say most of the issue is from Round Robin partitioning on the Distribute Streams.
Finish Him
The initial version of GENERATE_SERIES is a bit rough around the edges, and I hope some of these issues get fixed.
And, like, faster than issues with STRING_SPLIT did, because it took a really long time to get that worked on.
And that was with a dozen or so MVPs griping about it the whole time.
But there’s an even bigger problem with it that we’ll look at tomorrow, where it won’t get lost in all this stuff.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Wow, I got so stoked when I initially saw you mention that generate_series is being added (I did enjoy it in my short time with PG) and then immediately that stoke was wiped away; my current use cases would not allow for such a performance drag. That said, I am stoked about you mentioning Round Robin partitioning, not because I am excited about that particularly, but because I often want to know more about the “back-end” of SQLServer but don’t even know where to start.
Really interesting post, thanks!
PS: it is ABOUT TIME string_split has an ordinal position in the output, dang.
Heh heh, yeah. I’ve heard there are fixes in the works for some of this stuff, but I hate holding my breath on these things.
I’d love to know what the barriers are at MICROS~1 to actually providing the features needed with the performance needed (i.e. faster than existing roll-your-own solutions), and why the issues can’t be ironed out in early release programs or even via Azure SQL DB as a testbed (other than the ongoing lottery of what mechanisms are available for user feedback during any given moon phase). I suspect I also wouldn’t like that knowledge.
Very interested to see what tomorrow’s post is going to bring!
Problems with the summer intern program 🙃