But My Tempdb
Using the scenario from yesterday’s post as an example of why you might want to think about rewriting queries with Table Spools in them to use temp tables instead, look how the optimizer chooses a plan with an Eager Table Spool.
The “Eager” part means the entire set of rows is loaded into a temporary object at once.
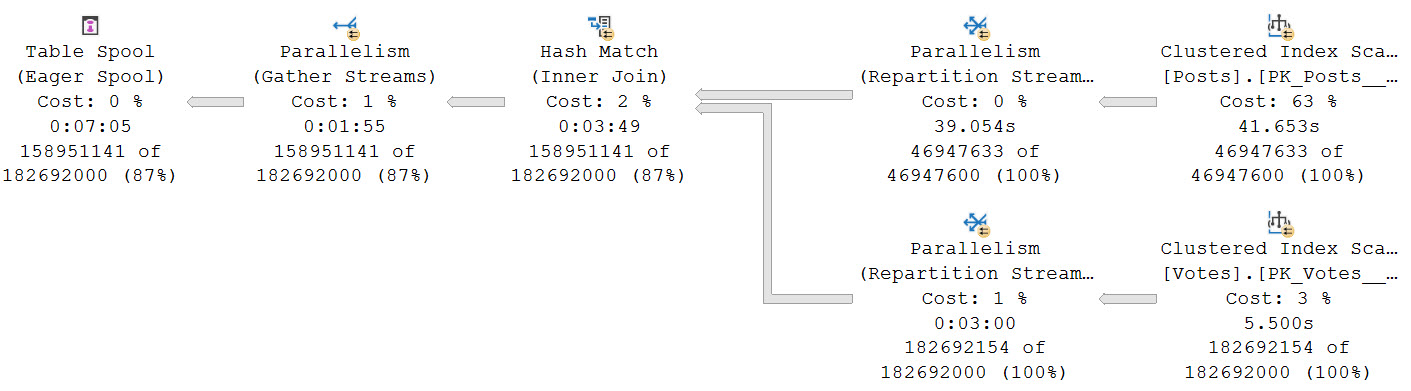
That’s a lot of rows, innit? Stick some commas in there, and you might just find yourself staring down the barrel of a nine digit number.
Worse, we spend a long time loading data into the spool, and doing so in a serial zone. There’s no good way to know exactly how long the load is because of odd operator times.
If you recall yesterday’s post, the plan never goes back to parallel after that, either. It runs for nearly 30 minutes in total.
Yes Your Tempdb
If you’re gonna be using that hunka chunka tempdb anyway, you might as well use it efficiently. Unless batch mode is an option for you, either as Batch Mode On Rowstore, or tricking the optimizer, this might be your best bet.
Keep in mind that Standard Edition users have an additional limitation where Batch Mode queries are limited to a DOP of 2, and don’t have access to Batch Mode On Rowstore as of this writing. The DOP limitation especially might make the trick unproductive compared to alternatives that allow for MOREDOP.
For example, if we dump that initial join into a temp table, it only takes about a minute to get loaded at a DOP of 8. That is faster than loading data into the spool (I mean, probably. Just look at that thing.).
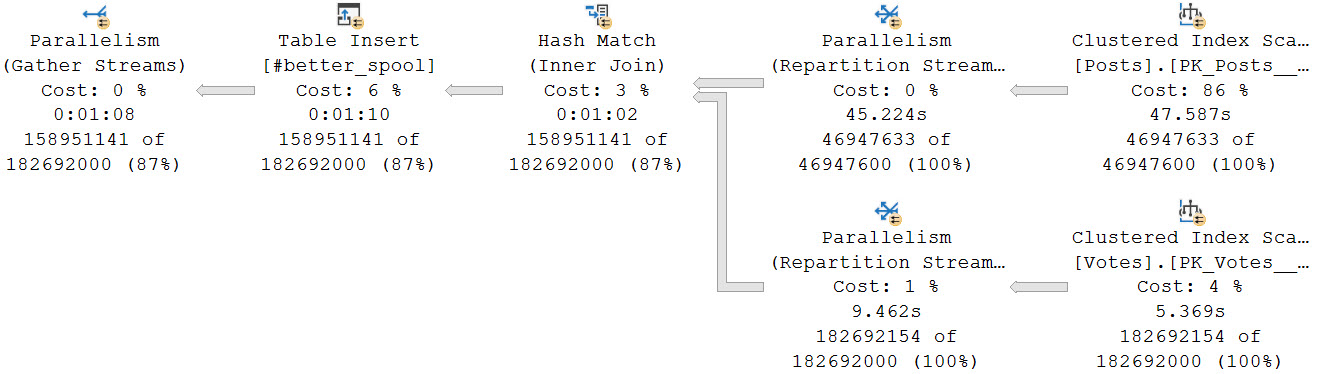
The final query to do the distinct aggregations takes about 34 seconds.

Another benefit is that each branch that does a distinct aggregation is largely in a parallel zone until the global aggregate.

In total, both queries finish in about a 1:45. A big improvement from nearly 30 minutes relying on the Eager Table Spool and processing all of the distinct aggregates in a serial zone. The temp table here doesn’t have that particular shortcoming.
In the past, I’ve talked a lot about Eager Index Spools. They have a lot of problems too, many of which are worse. Of course, we need indexes to fix those, not temp tables.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
SELECT
v.PostId,
v.UserId,
v.BountyAmount,
v.VoteTypeId,
v.CreationDate
INTO #better_spool
FROM dbo.Votes AS v
JOIN dbo.Posts AS p
ON p.Id = v.PostId;
SELECT
PostId = COUNT_BIG(DISTINCT s.PostId),
UserId = COUNT_BIG(DISTINCT s.UserId),
BountyAmount = COUNT_BIG(DISTINCT s.BountyAmount),
VoteTypeId = COUNT_BIG(DISTINCT s.VoteTypeId),
CreationDate = COUNT_BIG(DISTINCT s.CreationDate)
FROM #better_spool AS s;