Gretzky
Windowing functions solve a lot of interesting problems, and allow for some useful query rewrites at times.
The problem is that you’ve been sold a bill of goods by people using preposterously small databases. Today’s laptop hardware swallows little sample databases whole, and doesn’t expose the problems that data to hardware mismatches do.
Here’s a somewhat extreme example, by way of my home server, which is a Lenovo P17 that I bumped up until I hit around the $5000 mark. Here’s what I ended up with:
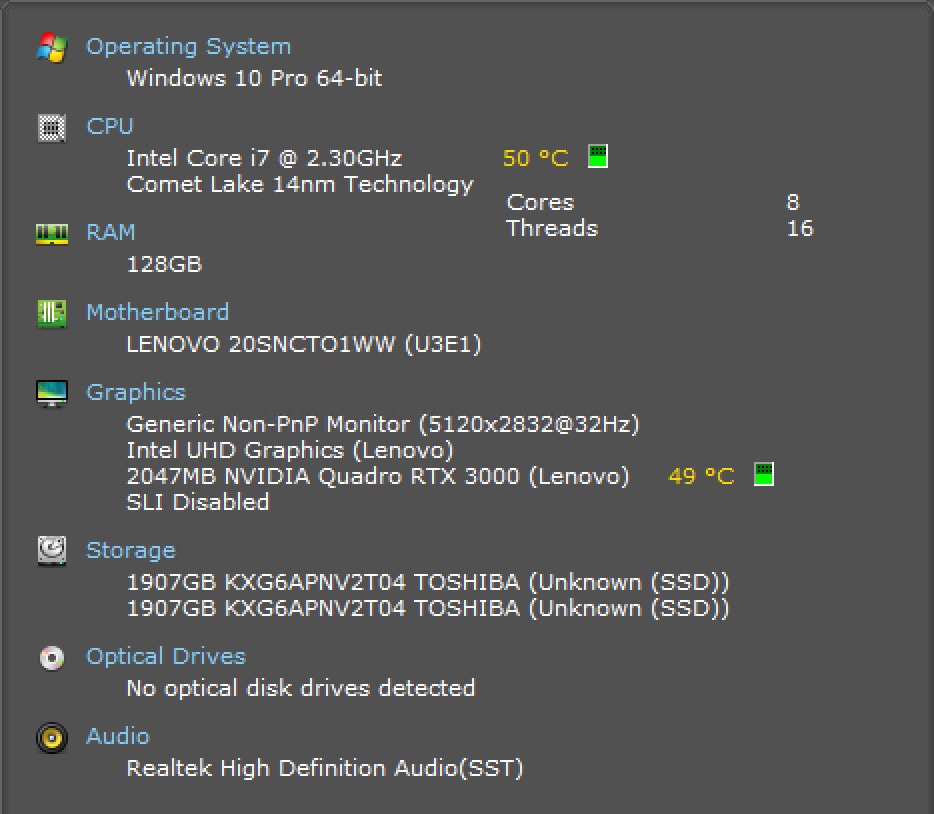
To put that in perspective, most cloud cost estimators will put you at around $5000 a month for similar hardware. I get it — no one pays list — but you get the idea.
But I said all that to say this: you take all those fabulous lessons about amazing window functions from the blog post to work with you and try to apply them to your data and… gee, we’ve been waiting an awful long time here, haven’t we?
Truth Poster
I’m not gonna do that to you. After all we’ve been through together! How could you ever think that?
First, let’s talk about some thing that will screw windowing function performance up:
- Having columns from different tables in the partition by or order by clause
- Not specifying ROWS instead of the default RANGE to avoid an on-disk spool
- Applying system or user defined functions to columns in the partition by or order by clause
- Selecting unnecessary columns along with the windowing function (makes indexing more difficult why, we’ll talk about that in a minute)
If you’re doing any of those things, it’s gonna be a rough ride indexing your way out of performance problems.
Let’s look at why!
Queryable
We’re going to use this handsome devil as an example.
I’m using a little trick on SQL Server to return no rows to SSMS, but still have to process the entire ugly part of the query first.
That’s the point of filtering to where the row number equals zero. No time to wait for all that.
WITH
p AS
(
SELECT
p.OwnerUserId,
p.PostTypeId,
p.Score,
x =
ROW_NUMBER() OVER
(
PARTITION BY
p.OwnerUserId,
p.PostTypeId
ORDER BY
p.Score DESC
)
FROM dbo.Posts AS p
WHERE p.OwnerUserId = 22656
)
SELECT
p.*
FROM p
WHERE x = 0;
Here’s the query plan without a useful index, just to set the stage for why we want to tune this, and what we want to fix:

To paraphrase:
- The clustered index of the Posts table doesn’t fit in the 96GB of RAM I have assigned to this VM, so we do ~25 seconds of reading from disk
- Since we don’t have an index that presents data in the order requested by the query, SQL Server has to get it lined up for us
All worthy reasons to tune thing, I’d say. Our goal is to give SQL Server an object that fits in memory to read from, which also stored data in the order we need for the windowing function.
What’s The Wrong Index?
Precision is the name of the game, here. These indexes won’t help us.
With partition by columns out of order:
CREATE INDEX p ON
dbo.Posts
(
PostTypeId,
OwnerUserId,
Score DESC
);
With Score in ascending order:
CREATE INDEX p ON
dbo.Posts
(
OwnerUserId,
PostTypeId,
Score
);
While it’s possible that swapping PostTypeId and OwnerUserId would yield the same results, it’s better to tailor the index to the query as it’s written if we’re creating a new one.
If we already had an index in place, I might consider testing altering the query. Looking at these, though, you can start to get a sense of how writing a windowing function that spans columns in multiple tables will cause problems with ordering.
Now, either one of those indexes would at least give the query a smaller object to initially access data from, which will improve performance but still not get us where we want to be.
Here’s the query plan shape for either of those indexes:

What’s The Right Index?
Finally, this index will help us:
CREATE INDEX p ON
dbo.Posts
(
OwnerUserId,
PostTypeId,
Score DESC
);
This arranges data just-so, and our query happily uses it:

It’s difficult to argue with the results here! This finishes in 25 milliseconds at DOP 1, compared to ~550ms at DOP 8 with the other index.
You Don’t Write Queries Like That, Though
When I have to fix these performance issue for clients, I usually have to do one of the following things:
- Rewrite the query to use a smaller select list
- Create a wider index if I can’t rewrite the query (but I’m not doing this here, because it’s a really bad idea for a table as wide as the Posts table)
- Get Batch Mode involved (on Enterprise Edition, anyway. Don’t bother with it on Standard Edition.)
Let’s switch the query up to something like this:
WITH
p AS
(
SELECT
p.*,
x =
ROW_NUMBER() OVER
(
PARTITION BY
p.OwnerUserId,
p.PostTypeId
ORDER BY
p.Score DESC
)
FROM dbo.Posts AS p
WHERE p.PostTypeId = 1
)
SELECT
p.*
FROM p
WHERE x = 0;
When we select everything from the Posts table and use a less selective predicate, the optimizer stops choosing our index because it estimates the cost of doing a bunch of lookups higher than just scanning the clustered index.
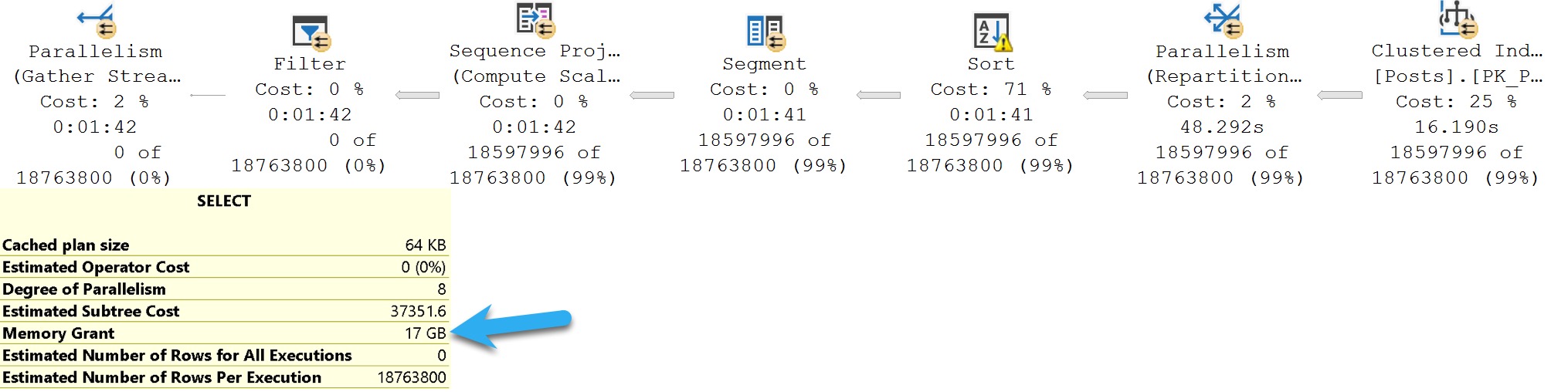
A couple things happen, too:
- Selecting all the columns asks for a huge memory grant, at 17GB
- We spill, and spill a ton. We spend nearly a full minute spilling to disk
Rewriting The Query
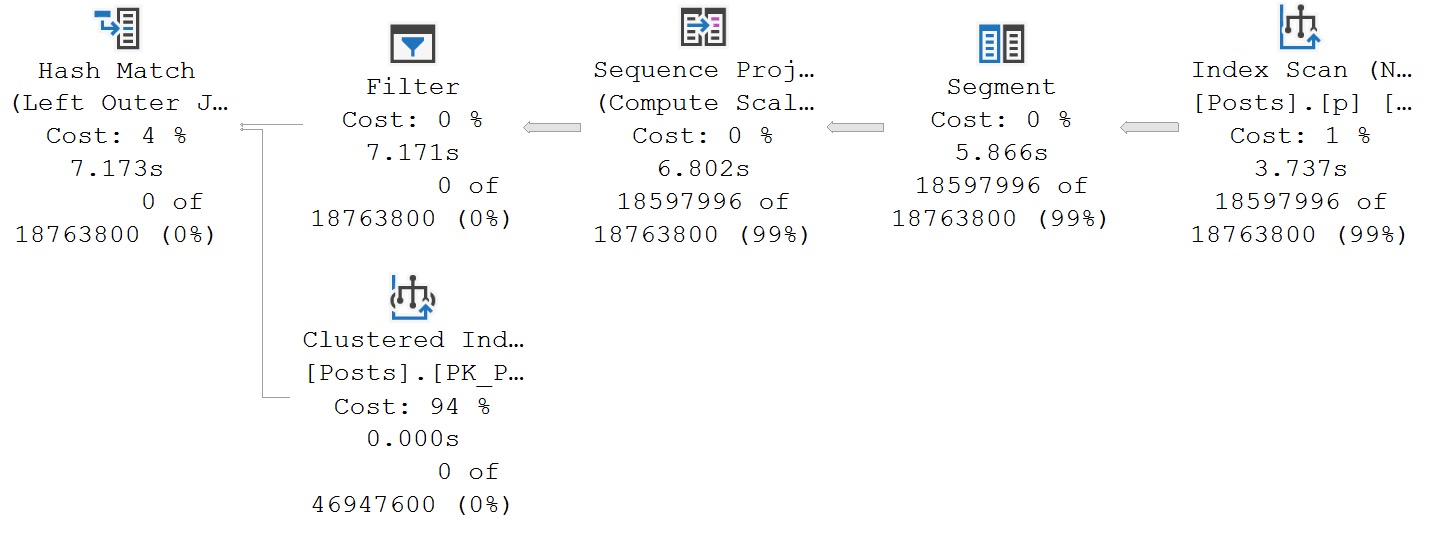
We can use the primary key of the table to create a more favorable set of conditions for our query to run by doing this:
WITH
p AS
(
SELECT
p.Id,
x =
ROW_NUMBER() OVER
(
PARTITION BY
p.OwnerUserId,
p.PostTypeId
ORDER BY
p.Score DESC
)
FROM dbo.Posts AS p
WHERE p.PostTypeId = 1
)
SELECT
p2.*
FROM p
LEFT JOIN dbo.Posts AS p2
ON p.Id = p2.Id
WHERE x = 0;
It’s a common enough pattern, but it pays off. You may not like it, but this is what peak performance looks like, etc.
Future Days
We’ll cover that in tomorrow’s post, since I think it deserves a good bit of attention.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Great write up. Small correction – If I’m reading the results correctly, I think your statement of “This finishes in .25 milliseconds” should be “This finishes in 25 milliseconds”. That is, there’s an extraneous dot in there.
Ooh thanks! Fixed!
NP. What’s a couple of orders of magnitude between friends? 🍻
Don’t sweat the small stuff!