Pete And Repeat
Building on yesterday’s post about cleaning up old indexes: Once you’ve gotten rid of indexes that aren’t used anymore, you’re gonna have some more work to do. I know, it sucks, but hopefully it won’t be too difficult or confusing. If it is, hit the link at the end of the post to drop me a line for some consulting help.
The next thing I usually do is look for nonclustered indexes that have overlapping columns in the key to merge together.
Here are two basic patterns to look at, in order of how useful they are to us currently:
- Key columns are an exact match
- Key columns are super/sub-sets of other indexes
- Key columns match to a point, but then differ
- Key columns are the same, but in a different order
For the second two, I put those aside at first. Remember that we already got rid of indexes that aren’t used at all to make queries go faster, so now we’re left with indexes that do get used (though how much will vary dramatically from database to database).
Order Is Everything
Key column order matters to us, because it defines how queries can access data in the index. Let’s take an imaginary index keyed on columns (A, B, C).
If you want to search on:
- A: Fast
- A, B: Fast:
- A, B, C: Fast
- B: Slower
- B, C: Slower
- C: Slower
Column A being the leading key column in the index means that index data is sorter first by column A. If there are any duplicates in there, then column B will be sorted within that group.
One way to visualize that is like this:
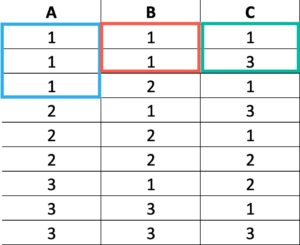
Finding any value(s) in column A is easy, because they’re in sorted order. But finding values in any combination of B/C means we have to scan through all the values to find ones we care about, if we’re not also searching on A.
If we have indexes on
- A, B, C
- B, A C
Are they identical? Maybe sorta kinda. This is where domain knowledge about your application comes into play, and knowing if queries most often filter on A or B, and which queries are more important to the workload. If you’re not sure, leave’em both alone for now.
Definitional
Let’s say you have a bunch of indexes from the first two categories, where the key columns might look something like this:
Duplicates:
- Key: A, B Includes (D, E)
- Key: A, B Includes (D, E, F, G)
Super/sub-sets:
- Key: D, E Includes (A, B)
- Key: D, E, F Includes (A, B, C)
There are some other things we need to consider about the indexes:
- Included columns: Can be merged safely; order doesn’t mater
- Only stored at the leaf level, not ordered
- Uniqueness: Can only be preserved for exact key matches
- Unique D, E is different from D, E, F
- Filters: Look at usage metrics to figure out these
- A filtered may not be useful to all queries, especially when parameterized
Practical
In theory, wider indexes are better indexes, because they’re more useful to more queries.
With indexes that fully cover all the columns our queries reference, we don’t need to worry about the optimizer sometimes choosing our index and sometimes choosing the clustered index depending on how many rows it thinks it’s going to have to deal with.
That’s generally a positive, but there are some caveats:
- Indexing columns that are updated frequently can exacerbate locking and deadlocking
- Indexing max columns over and over again can really bloat out our database
- Indexing to include every column in the table creates whole copies of the table
That being said, you can run into certain locking problems if you’re using a garbage isolation level like Read Committed:
You have to strike a careful balance with indexes. Enough, but not too many. Covering, but not in a counterproductive way.
To find indexes that can be removed because they’re overlapping, a good, free tool is sp_BlitzIndex. It’s part of an open source project that I’ve spent a lot of time on. It’ll warn you about indexes that are exact and borderline duplicates, so that you can start looking at which are safe to merge together.
In some posts to follow, we’ll cover index design strategies that work, and how you can improve on SQL Server’s missing index requests.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Related Posts
- Software Vendor Mistakes With SQL Server: Indexing #Temp Tables Incorrectly
- Software Vendor Mistakes With SQL Server: Thinking Index Rebuilds Solve Every Problem
- Software Vendor Mistakes With SQL Server: Lowering Fill Factor For Every Index
- Software Vendor Mistakes With SQL Server: Not Using Filtered Indexes Or Indexed Views