Understanding
I’ve covered this sort of information in previous posts, like:
But some points should be made together, so I’m going to combine them a bit, and expand on a few points too.
I know that it’s probably an overly-lofty goal to expect people who don’t seem to have the hang of indexing regular tables down to not repeat those errors with #temp tables.
But hey, hope burns eternal. Like American Spirits (the cigarettes, not some weird metaphorical thing that Americans possess, or ghosts).
Nonclustered Index Follies: Creating Them Before You Insert Data
I’m not saying that you should never add a nonclustered index to a #temp table, but I am saying that they shouldn’t be your first choice. Make sure you have a good clustered index on there first, if you find one useful. Test it. Test it again. Wait a day and test it again.
But more importantly, don’t do this:
CREATE TABLE #bad_idea
(
a_number int,
a_date datetime,
a_string varchar(10),
a_bit bit
);
CREATE INDEX anu ON #bad_idea(a_number);
CREATE INDEX ada ON #bad_idea(a_date);
CREATE INDEX ast ON #bad_idea(a_string);
CREATE INDEX abi ON #bad_idea(a_bit);
Forget for a minute that these are a bunch of single-column indexes, which I’m naturally and correctly opposed to.
Look what happens when we try to insert data into that #temp table:
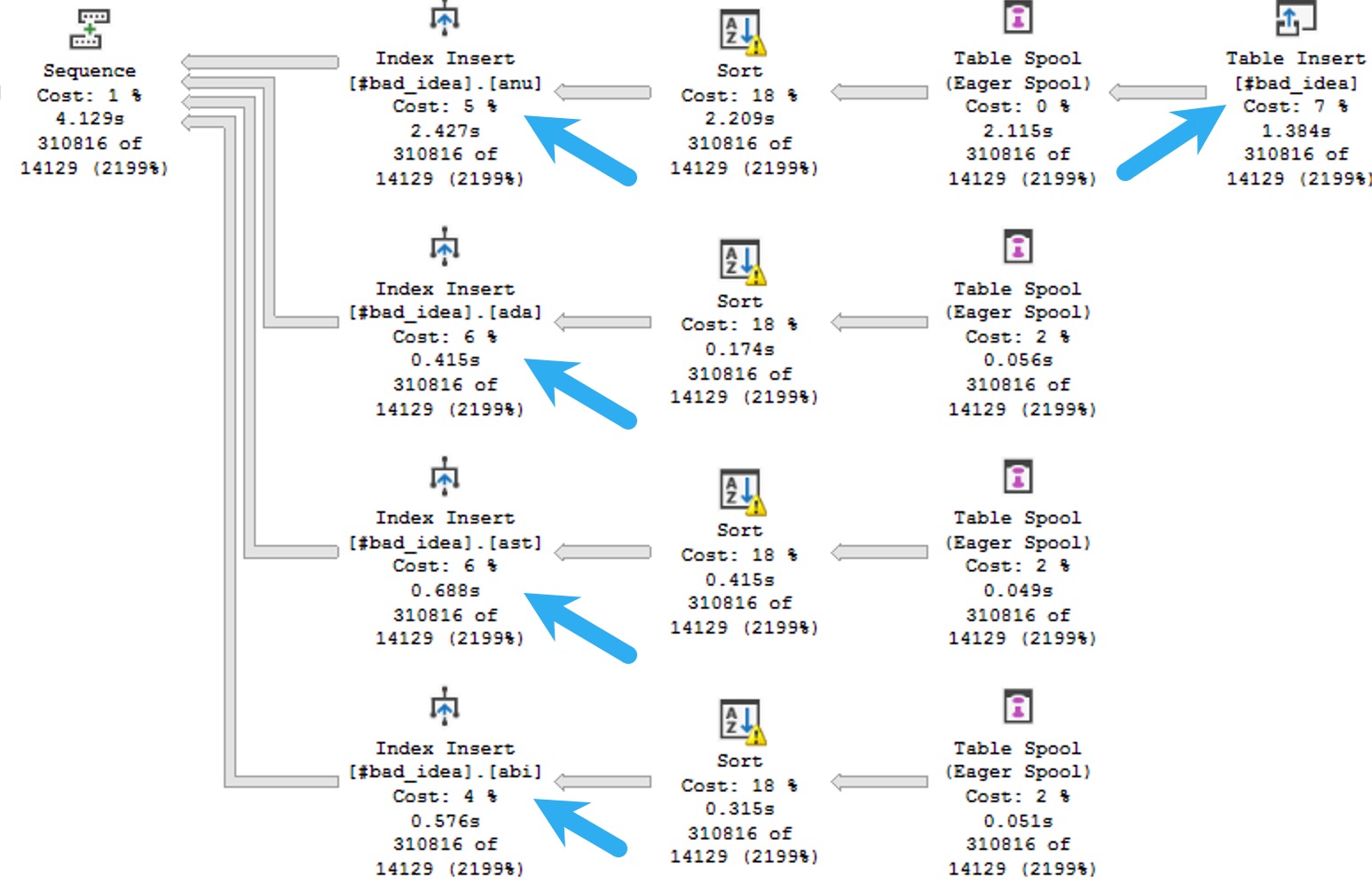
You have to insert into the heap (that’s the base table here, since we don’t have a clustered index), and then each of the nonclustered indexes. In general, if you want nonclustered indexes on your #temp tables, you should create them after you insert data, to not mess with parallel inserts and to establish statistics with a full scan of the data.
Nonclustered Index Follies: If You Need Them, Create Them Inline
If for some insane reason you decide that you need indexes on your #temp table up front, you should create everything in a single statement to avoid recompilations.
CREATE TABLE #bad_idea
(
a_number int,
INDEX anu (a_number),
a_date datetime,
INDEX ada (a_date),
a_string varchar(10),
INDEX ast (a_string),
a_bit bit,
INDEX abi (a_bit)
);
I don’t have a fantastic demo for that, but I can quote a Great Post™ about #temp tables:
-
Do not explicitly drop temp tables at the end of a stored procedure, they will get cleaned up when the session that created them ends.
-
Do not alter temp tables after they have been created.
-
Do not truncate temp tables
-
Move index creation statements on temp tables to the new inline index creation syntax that was introduced in SQL Server 2014.
There are some other good points there, too. Pay attention to those as well.
Of course, there is one interesting reason for dropping #temp tables: running out of space in tempdb. I tend to work with clients who need help tuning code and processes that hit many millions of rows or more.
If you’re constantly creating large #temp tables, you may want to clean them up when you’re done with them rather than letting self-cleanup happen at the end of a procedure.
This applies to portions of workloads that have almost nothing in common with OLTP, so you’re unlikely to experience the type of contention that the performance features which apply there also apply here. Reporting queries rarely do.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Related Posts
- Software Vendor Mistakes With SQL Server: Not Getting Parallel Inserts Into #Temp Tables
- Software Vendor Mistakes With SQL Server: Not Using #Temp Tables
- Software Vendor Mistakes With SQL Server: Thinking Index Rebuilds Solve Every Problem
- Software Vendor Mistakes With SQL Server: Lowering Fill Factor For Every Index