Lately I’ve been doing some exploratory performance testing on Azure SQL Managed Instances in preparation for a migration to that platform. This blog post documents some storage testing results and may even have practical advice near the end. All testing was done on a gen5 general purpose instance with 8 vCores.
The Test Query
The test case is relatively simple. I want to do about 1 GB of physical reads without doing any read-ahead reads. To accomplish that, I loaded 130k rows into a table making sure that only one row could fit on each data page. I also wrote a simple nested loop join query that doesn’t allow for nested loop prefetching. Here’s a picture of the query plan:
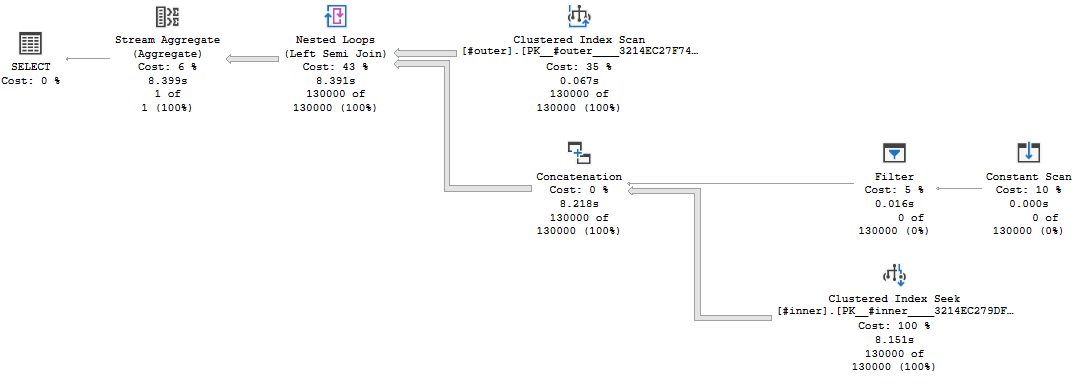
The presence of the concat operator on the inner side of the nested loop prevents the prefetch optimization. This limitation is unusually annoying, but I’m using it to my advantage here to stress I/O as much as I can. Here’s the T-SQL used to generate the query plan in the picture:
use tempdb;
CREATE TABLE #outer (
ID BIGINT IDENTITY(1, 1) NOT NULL,
DUMMY BIGINT NOT NULL,
PRIMARY KEY (ID)
);
INSERT INTO #outer (DUMMY)
SELECT TOP (130000) 0
FROM master..spt_values t1
CROSS JOIN master..spt_values t2;
CREATE TABLE #inner (
ID BIGINT IDENTITY(1, 1) NOT NULL,
BIG_DUMMY CHAR(5000) NOT NULL,
PRIMARY KEY (ID)
);
INSERT INTO #inner (BIG_DUMMY)
SELECT TOP (130000) '0'
FROM master..spt_values t1
CROSS JOIN master..spt_values t2;
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
SELECT COUNT_BIG(*)
FROM #outer o
WHERE o.DUMMY = 1
OR EXISTS (
SELECT 1
FROM #inner i
WHERE i.ID = o.ID
)
OPTION (MAXDOP 1, QueryRuleOff BuildSpool);
For the different cases, I ran the SELECT query at MAXDOP 1 and MAXDOP 2 and cleared the buffer pool before each query execution.
Is Tempdb no longer the outhouse?
For user databases on managed instances, the documentation states that you should expect I/O latency of around 5-10 ms. However, tempdb is attached locally so we might get better latency there. Wanting to start off on a positive note, I elected to try testing in tempdb first. Here are the test results for the tempdb database:

The managed instance spends more time waiting for I/O compared to testing on my local machine’s tempdb, but the MAXDOP 2 query has the nice property of nearly being twice as fast as the MAXDOP 1 query. Both queries on the managed instance have roughly the same amount of I/O wait time. The MAXDOP 2 query is primarily faster because the I/O waits are spread fairly evenly between both threads. I will note that I was a bit lazy with my test query and I didn’t ensure that an appropriate amount of work is sent to each thread, but things worked out well enough for this kind of test.
My next test was performed in a user database that was created solely for the purpose of this testing. The initial database size was about 1.5 GB. The code is the same as before, but I just created user tables instead of temp tables. The test results were not good. Both queries ran for over a minute and the MAXDOP 2 query was slower than the MAXDOP 1 query. The documentation says the following:
If you notice high IO latency on some database file or you see that IOPS/throughput is reaching the limit, you might improve performance by increasing the file size.
In this case, I might improve performance if I increase my data file size to greater than 128 GB. I didn’t want to do that for a few reasons:
- It costs money and I don’t like spending money.
- There’s an instance level storage limit of 2 or 8 TB for general purpose (depending on vCore count).
- Creating a database with 99% free space is silly and a well-meaning DBA could shrink it without realizing the performance implications.
For you, dear reader, I increased the database size to 132 GB. I did not observe any performance improvements after doing so, despite testing many times. Here are the test results so far:
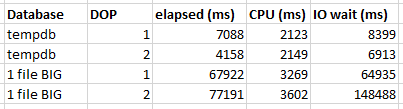
Tempdb has 12 data files btw
The chart below makes me wonder if creating multiple files for a small database would be helpful:

If I can get 500 IOPS per database file and I have four database files, logically speaking I would expect to get 2000 IOPS for a single database with four files. I’m personally a big fan of databases with multiple files. I’ve seen a lot of performance problems fixed or mitigated by going beyond the default one data file per database rule.
There is at least one downside to creating multiple small files for one database on managed instances: there’s a documented limit of 280 total files for the general purpose tier. This limit is there because each file takes up a minimum of 128 GB on the storage backend and a general purpose instance can only use up to 35 TB of storage on the backend: 280 * 128 = 35 * 1024. It is amusing to consider how master, model, and msdb take up about 750 GB of storage behind the scenes.
On my instance, I’m nowhere near the 280 file limit/35 TB storage backend limit, so I created a small database (significantly below 128 GB) with about 4 files and tested the query again. Here are the full results:
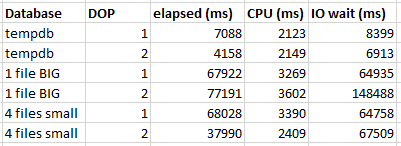
MAXDOP 1 query performance is pretty much the same as before, but the MAXDOP 2 query runtime decreased from 77 seconds to 37 seconds. That’s a huge improvement. The MAXDOP 2 query is also roughly twice as fast as the MAXDOP 1 query which is nice to see. The only thing that I did to improve parallel query performance was to create a new database with 4 data files instead of 1.
Practical Applications
To get the obvious out of the way: if you’re writing temporary data to user tables instead of temp tables on Managed Instance, you probably shouldn’t be doing that.
I don’t have any production workloads in managed instances yet, but I’ll go ahead and attempt to give some guidance on file counts. You should consider exceeding 1 data file per database if all of the following are true:
- Your database is under 128 GB
- You care about I/O performance for that database or your I/O waits for that database are higher than you’d like
- Your instance isn’t close to the 35 TB backend limit
It will always be workload dependent, but you may see a performance improvement by splitting your database into multiple files. Do note that you’ll need to spread your data over all of the files (rebuild your tables and indexes after adding files) and you’ll want the files to be the same sizes with the same autogrowth settings. Also, there are other situations where you may want more than one data file for a database. Do not interpret the above to mean that databases already above 128 GB only need a single file.
If you’ve got a managed instance with only one database, perhaps you’re wondering if it would be a good idea to give it 96 data files. In theory, that will allow that database to hit the instance IOPS limit of 30k-40k. I can say that I’ve run with 96 file user databases in Enterprise and I didn’t observe any issues other than an annoying initial setup. The scenario for that was a large ETL system and I was trying to reduce PFS and GAM contention, so it’s quite a bit different than what you would run on a managed instance.
I would be somewhat cautious with creating significantly more data files for one database than your vCore count. In that configuration, I would also try to avoid excess autogrowth events as that is one place you might run into trouble. In general, when doing unusual things, you should test very carefully. That same advice is applicable here. It might work out well or it might not help at all. Stop asking me, I’ve used the cloud for like a week.
Final Thoughts
In some scenarios on Azure SQL Managed Instances, you may be above to improve I/O performance for small databases FOR FREE by spreading your data over multiple data files. Isn’t that wonderful?
Thanks for reading!
I know it’s a different product, but this is consistent with Brent Ozar’s findings back in 2019 for SQLDB. https://www.brentozar.com/archive/2019/02/theres-a-bottleneck-in-azure-sql-db-storage-throughput/
I was hoping it would get better. The cost required for Business Critical vs the IOPS is not in line, and this has been the case for years with Azure.
Great post!
I am waiting the next one for write I/O performance.
On-Prem still cheaper and faster
Great post, –Brent–, –Erik–, Joe!
I saw the link to this post that Brent Ozar sent out and thought to myself, “Hey, this sounds like something Joe Obbish would write.” Sure enough! It’s great to see you posting again, Joe!
how would you performance test azure sql (SaaS, not managed)?
– you can’t DBCC DROPCLEANBUFFERS; and you can’t QueryRuleOff BuildSpool