Maybe Probably
It’s likely also obvious that your join clauses should also be SARGable. Doing something like this is surely just covering up for some daft data quality issues.
SELECT
COUNT_BIG(*) AS records
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON ISNULL(p.OwnerUserId, 0) = u.Id;
If 0 has any real meaning here, replace the NULLs with zeroes already. Doing it at runtime is a chore for everyone.
But other things can be thought of as “SARGable” too. But perhaps we need a better word for it.
I don’t have one, but let’s define it as the ability for a query to take advantage of index ordering.
World War Three
There are no Search ARGuments here. There’s no argument at all.
But we can plainly see queries invoking functions on columns going all off the rails.
Here’s an index. Please enjoy.
CREATE INDEX c ON dbo.Comments(Score);
Now, let’s write a query. Once well, once poorly. Second verse, same as the first.
SELECT TOP(1)
c.*
FROM dbo.Comments AS c
ORDER BY
c.Score DESC;
SELECT TOP(1)
c.*
FROM dbo.Comments AS c
ORDER BY
ISNULL(c.Score, 0) DESC;
The plan for the first one! Yay!
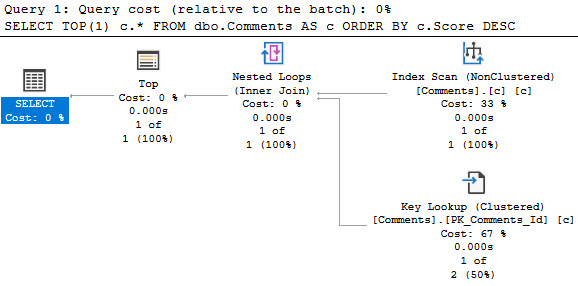
Look at those goose eggs. Goose Gossage. Nolan Ryan.
The plan for the second one is far less successful.

We’ve done our query a great disservice.
Not Okay
Grouping queries, depending on scope, can also suffer from this. This example isn’t as drastic, but it’s a simple query that still exhibits as decent comparative difference.
SELECT
c.Score
FROM dbo.Comments AS c
GROUP BY
c.Score
HAVING
COUNT_BIG(*) < 0;
SELECT
ISNULL(c.Score, 0) AS Score
FROM dbo.Comments AS c
GROUP BY
ISNULL(c.Score, 0)
HAVING
COUNT_BIG(*) < 0;
To get you back to drinking, here’s both plans.
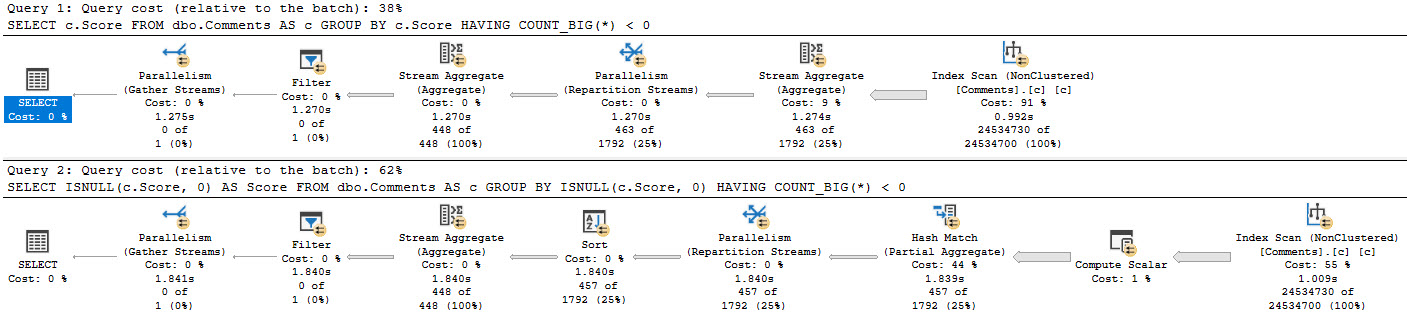
We have, once again, created more work for ourselves. Purely out of vanity.
Indexable
Put yourself in SQL Server’s place here. Maybe the optimizer, maybe the storage engine. Whatever.
If you had to do this work, how would you prefer to do it? Even though I think ISNULL should have better support, it applies to every other function too.
Would you rather:
- Process data in the order an index presents it and group/order it
- Process data by applying some additional calculation to it and then grouping/ordering
That’s what I thought.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Related Posts
- SQL Server 2017 CU 30: The Real Story With SelOnSeqPrj Fixes
- Getting The Top Value Per Group With Multiple Conditions In SQL Server: Row Number vs. Cross Apply With MAX
- Getting The Top Value Per Group In SQL Server: Row Number vs. Cross Apply Performance
- Multiple Distinct Aggregates: Still Harm Performance Without Batch Mode In SQL Server
Another great post Ill be showing to newbies. Good stuff Erik!