Better Late
A few weeks back, my friend Randolph (B|T) and I collaborated a bit on a blog post about Optimize For Ad Hoc Workloads.
Now that I’m a Microsoft Approved Blogger™️ and you all have to take me Very Seriously™️, I’d like to make a few of the points here in my own words, though I highly suggest reading Randolph’s post because it’s much better.
Randolph writes for a living. I’m just a consultant with some free time.
The result you want from Optimize For Ad Hoc Workloads is probably closer to what Forced Parameterization does
When people complain about lots of “single use” plans, they probably want there to be fewer of them. Turning on Forced Parameterization will promote plan reuse. Turning on Optimize For Ad Hoc Workloads won’t do that.
- With Forced Parameterization, literal values are replaced (when possible) with parameters, which promotes plan re-use
- Turning on Optimize For Ad Hoc Workloads compiles a new plan for queries with literal values, and then just caches a stub
Parameterization, and further Parameter Sniffing, has an ominous meaning for many of you.
I see it all the time, folks jumping through every hoop in the world to not have a parameter get sniffed. Recompiling, Unknown-ing, Local Variable-ing. Sad. Very sad.
Bottom line: If you want fewer single use plans, parameterize your damn queries.
Turning Optimize For Ad Hoc Workloads on can make workload analysis difficult
You know how sometimes you have a performance issue, and then you go look in the plan cache, and queries don’t have execution plans? This setting can make that happen.
Why? Because stubs aren’t query plans. Never have been. Never will be.
If we run these queries, they’ll both get a stub, because each one has a different literal value. These are “single use” plans, even though SQL Server compiled and use the “same” plan for each one.
SELECT
c = COUNT_BIG(*)
FROM dbo.Votes AS v
WHERE v.VoteTypeId = 2
AND 1 = (SELECT 1); --Skip a Trivial Plan/Simple Parameterization
GO
SELECT
c = COUNT_BIG(*)
FROM dbo.Votes AS v
WHERE v.VoteTypeId = 4
AND 1 = (SELECT 1); --Skip a Trivial Plan/Simple Parameterization
GO
Here are the plans:
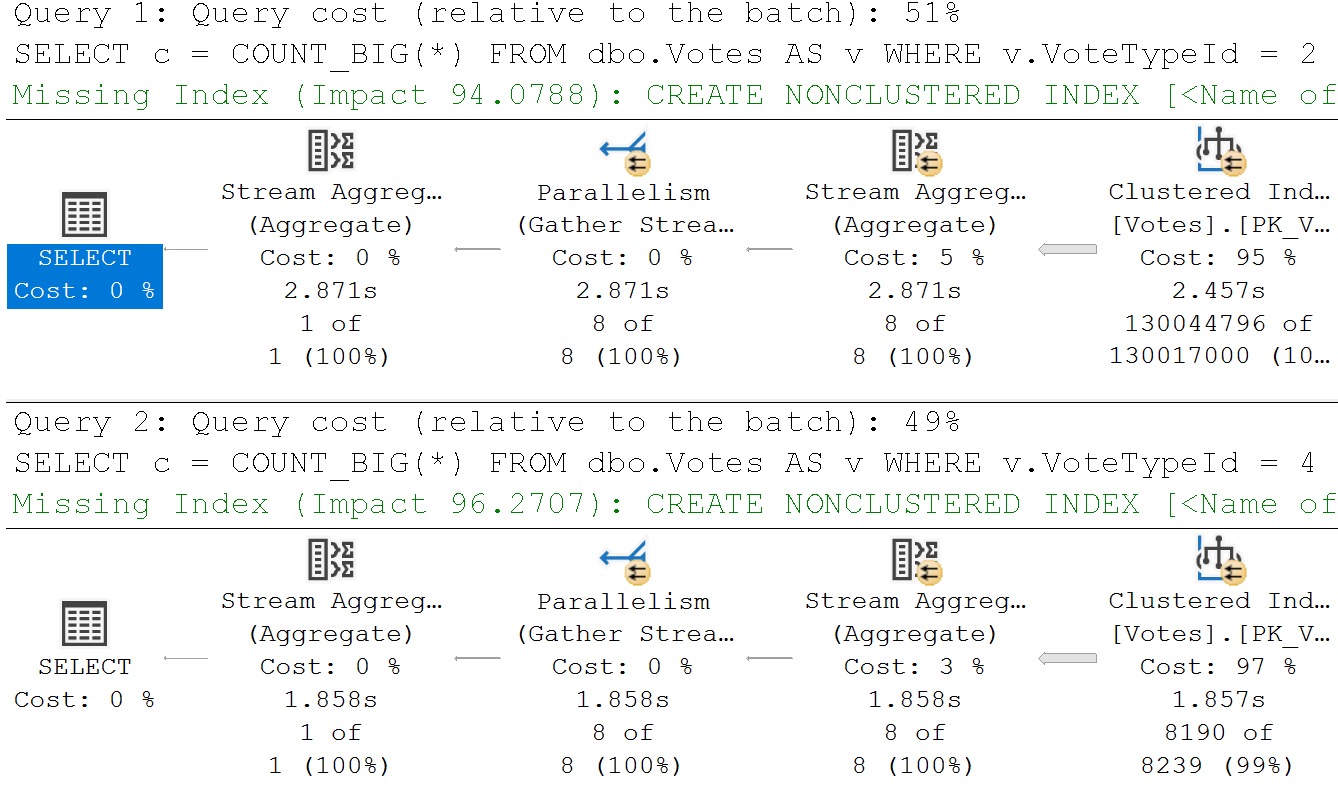
But here’s why they’re “different” and each one gets a stub:
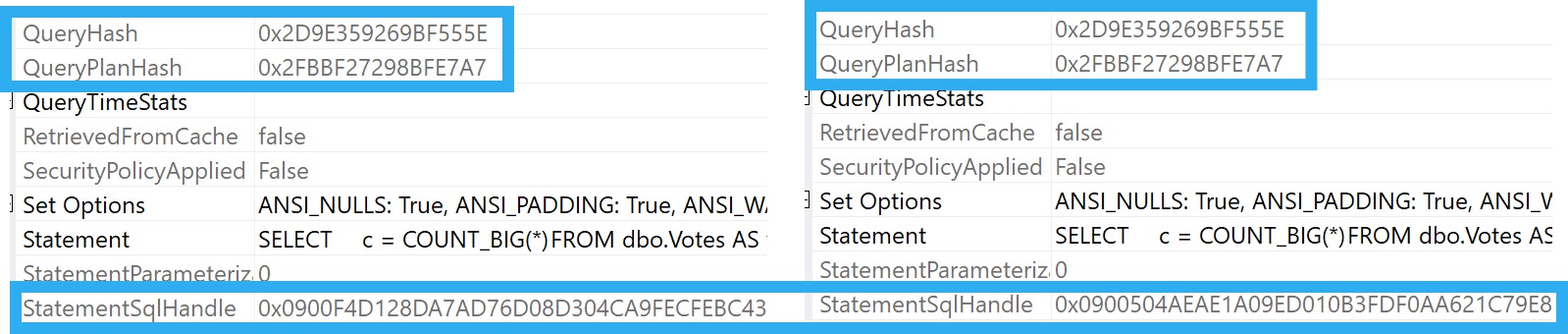
Even though the Query Hash and Query Plan Hash are identical, each one has a different SQL Handle.
I’m using a simple demo to show you the end result, but you can probably see why this would be more difficult to deal with in real life.
The “same” query might run more than once, but if a literal in the where clause is different, you’ll have two stubs
Thinking about the situation above:
- Did we really want to compile the same execution plan twice?
- What’s the point of having two stubs for what amounts to the exact same query and plan?
If we had turned on Forced Parameterization, that’s what would have happened: The where clause would have had the literal 4 and 2 values replaced with a parameter, and we would have gotten a cached and re-used plan.
The problem we hit is that we got two different SQL Handles because the 4 and 2 hash out differently.
That’s a problem that gets solved with parameterization, forced or fixed in code.
You’ll still compile full plans for queries to execute with
This is another misconception I run into a lot. For every time a query runs that SQL Server can’t find a matching SQL Handle for, you’ll get a new plan generated, even if only a stub is cached.
If you have a lot of big, complicated queries that take a long time to compile, that can be unpleasant.
And look, I’m not afraid of recompiling plans. In the right place, that can be awesome.
This can also be annoying if you have queries constantly coming in and compiling new plans.
It’s been a while since I’ve seen this scenario cause CPU to hit 100% (or even close to it), but in today’s Unfortunate Cloud Age© any CPU reduction you can make to end up on smaller, less expensive instances can make you look like a Bottom Line Hero™️.
Constant query compilation, and long query compilation, can contribute to that.
The stubs still count towards the total number of plans you can have cached
By default, you have a limit of 160,036 total plans allowed in the cache, and other limits in total size based on available memory.
Plan stubs still contribute towards the total count. Lots of single use stubs can still cause “bloat”.
The questions you have to ask here, are:
- How much larger are my query plans than the stubs?
- Is that savings worth it to not have plans in cache available to analyze?
- Do you capture query plans in a different way? (Query Store, monitoring tool, etc.)
Lots of stubs aren’t necessarily more useful.
When you end up with “the same” unparameterized query running over and over again, you might miss out on aggregate resource usage for it
One way that it can be useful to look at your server’s workload is seeing which queries:
- Execute the most
- Use the most total CPU
- Are attached to missing index requests
A lot of plan cache analysis scripts (even ones I’ve written and worked on) will group by or correlate on SQL Handle for different things.
If you have a different SQL Handle for every execution of “the same” query with different literals, you’ll miss out on them.
You’ll have to look by something else, like Query Hash, Query Plan Hash, or Plan Handle instead.
You can run into this regardless of Optimize For Ad Hoc Workloads being enabled, but a lot of folks out there tend to ignore rows returned by analysis scripts that don’t also have a query plan.
Stubs Ahoy.
The Setting Is Poorly Named
Last but not least: this is a poorly named setting.
I still run into folks who think that enabling this gives the optimizer some special powers for ad hoc queries.
It doesn’t. The only thing it does is cache a plan stub instead of the entire plan on “first execution”.
This isn’t a documentation problem either, this is a not-reading-the-documentation problem.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Good reminders. I’ve enabled this on servers where we have a high percentage of “single use” plans in the first place (for a variety of reasons). But yeah – it’s not the behavior you expect by the name.
Neat! Did you try Forced Parameterization on them to see if that increased plan usage?
One of the more pernicious reasons for lack of plan reuse is ADO.Net’s “AddWithValue” function, which tries to guess (badly) which data type a parameter is. As a rule it will pass all strings as nvarchar at whatever length the actual string is. See https://www.dbdelta.com/addwithvalue-is-evil/