Previously
We had a couple queries we wanted to make fast, but SQL Server’s missing index request had mixed results.
Our job now is to figure out how to even things out. To do that, we’re gonna need to mess with out index a little bit.
Right now, we have this one:
CREATE INDEX whatever
ON dbo.Posts(PostTypeId, LastActivityDate)
INCLUDE(Score, ViewCount);
Which is fine when we need to Sort a small amount of data.
SELECT TOP (5000)
p.LastActivityDate,
p.PostTypeId,
p.Score,
p.ViewCount
FROM dbo.Posts AS p
WHERE p.PostTypeId = 4
AND p.LastActivityDate >= '20120101'
ORDER BY p.Score DESC;
There’s only about 25k rows with a PostTypeId of 4. That’s easy to deal with.
The problem is here:
SELECT TOP (5000)
p.LastActivityDate,
p.PostTypeId,
p.Score,
p.ViewCount
FROM dbo.Posts AS p
WHERE p.PostTypeId = 1
AND p.LastActivityDate >= '20110101'
ORDER BY p.Score DESC;
Theres 6,000,223 rows with a PostTypeId of 1 — that’s a question.
Don’t get me started on PostTypeId 2 — that’s an answer — which has 11,091,349 rows.
Change Management
What a lot of people try first is an index that leads with Score. Even though it’s not in the WHERE clause to help us find data, the index putting Score in order first seems like a tempting fix to our problem.
CREATE INDEX whatever
ON dbo.Posts(Score DESC, PostTypeId, LastActivityDate)
INCLUDE(ViewCount)
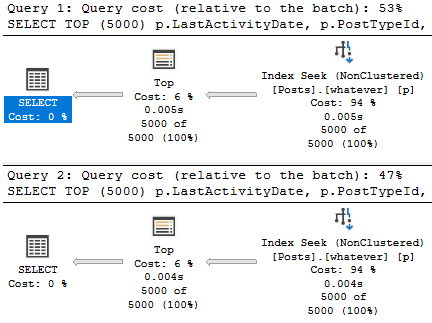
The result is pretty successful. Both plans are likely fast enough, and we could stop here, but we’d miss a key point about B-Tree indexes.
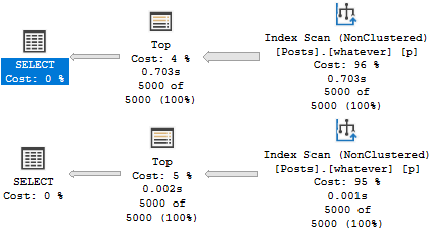
What’s a bit deceptive about the speed is the amount of reads we do to locate our data.
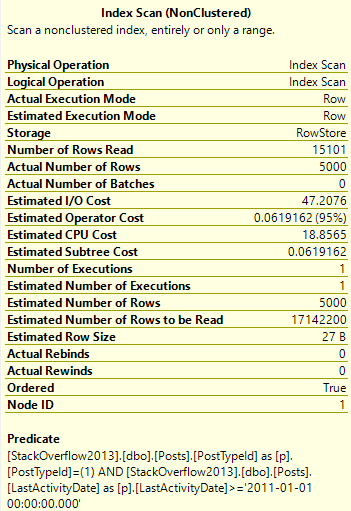
We only need to read 15k rows to find the top 5000 Questions — remember that these are very common.
We need to read many more rows to find the top 5000… Er… Whatever a 4 means.
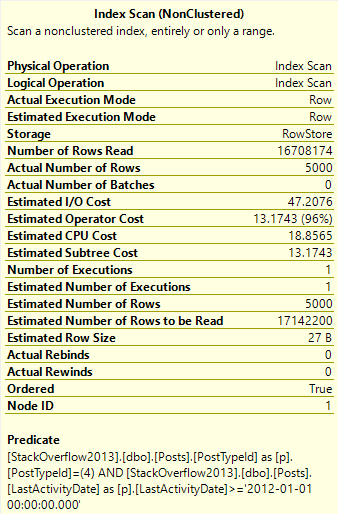
Nearly the entire index is read to locate these Post Types.
Meet In The Middle
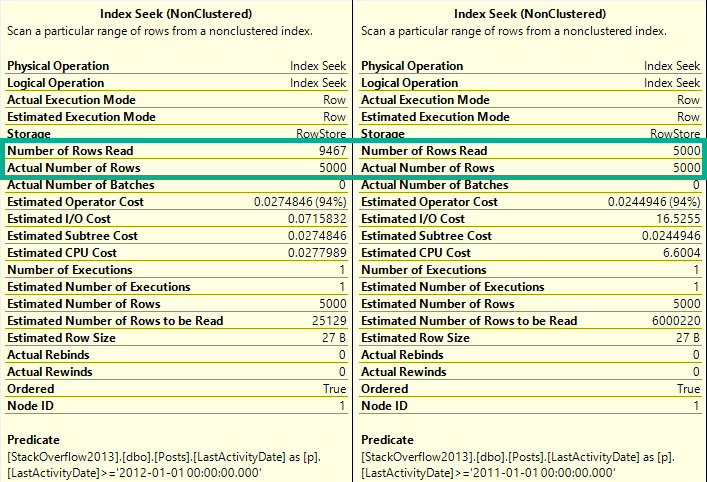
The point we’d miss if we stopped tuning there is that when we add key columns to a B-Tree index, the index is first ordered by the leading key column. If it’s not unique, then the second column is ordered within each range of values.
Putting this together, let’s change our index a little bit:
CREATE INDEX whatever
ON dbo.Posts(PostTypeId, Score DESC, LastActivityDate)
INCLUDE(ViewCount) WITH (DROP_EXISTING = ON);
With the understanding that seeking to a single PostTypeId column will bring us to an ordered Sort column for that range of values.
Now our plans look like this:
Which allows us to both avoid the Sort and keep reads to a minimum.
Interior Design
When designing indexes, it’s important to keep the goal of queries in mind. Often, predicates should be the primary consideration.
Other times, we need to take ordering and grouping into account. For example, if we’re using window functions, performance might be unacceptable without indexing the partition by and order by elements, and we may need to move other columns to parts of the index that may not initially seem ideal.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Makes sense; not that you needed any confirmation. 🙂
I like how you made this a challenge! It was a fun thought experiment!
I thought, “he wants us to think; this isn’t just ‘predicate indexing'”.
There is a single-valued equality predicate and a “left equal and/or expanding” (probably a better term for this) predicate. So, the kneejerk keys are not optimal for both, or other, statements.
The engine must scan the [seek] range, anyway (may be able to bail out under certain circumstances or conditions), at least it’s ordered, as requested, and can return the matching rows on LastActivityDate.
This was fun!
Thanks! Glad you enjoyed following along.
Yeah, I think that’s an overlooked index design choice a lot of the time.
I’ll try to do more posts like these in the future.
What would you do if the where condition is still a predicate after you have an index that would support it? It’s still scanning the whole table. The dates just aren’t selective enough?
Sorry, I’m not getting your question. Can you explain a little more?
i’ve got a query with a few joins, mostly left. the only where clause is ActivityEndTime > @startDateTime AND ActivityStartTime < @endDateTime and this is still showing up as a predicate and avoiding the index on starttime/endtime and doing a full scan. Puzzled why?