A Long Time Ago
I had to write some hand-off training about query tuning when I was starting a new job.
As part of the training, I had to explain why writing “complicated logic” could lead to poor plan choices.
So I did what anyone would do: I found a picture of a pirate, named him Captain Or, and told the story of how he got Oared to death for giving confusing ORders.
This is something that I unfortunately still see people doing quite a bit, and then throwing their hands up as queries run forever.
I’m going to show you a simple example of when this can go wrong, and also beg and plead for the optimizer team to do something about it.
Big Bully
“Write the query in the simplest way possible”, they said.
So we did, and we got this.
SELECT u.Id, MAX(p.Score)
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON u.Id = p.OwnerUserId
OR u.Id = p.LastEditorUserId
WHERE p.PostTypeId IN (1, 2)
GROUP BY u.Id;
Note the OR in the join condition — we can match on either of those columns.
Here’s the index we created to make this SUPERFAST.
CREATE NONCLUSTERED INDEX 36chambers
ON dbo.Posts ( OwnerUserId, LastEditorUserId, PostTypeId )
INCLUDE ( Score );
If we’re good DBAs, still doing as we’re told, we’ll read the query plan from right to left.
The first section we’re greeted with is this:
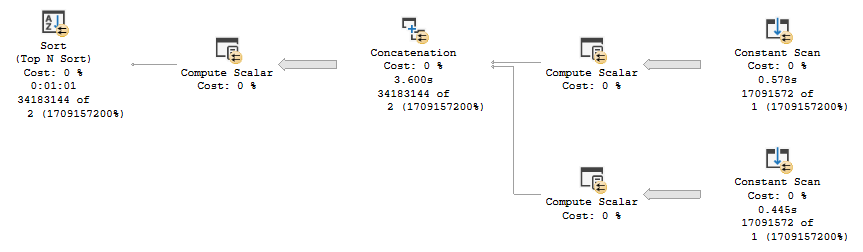
We spend a full minute organizing and ordering data. If you want to poke around, the plan XML is here.
The columns in the Compute Scalars are OwnerUserId and LastEditorUserId.
Next in the plan is this fresh hell:
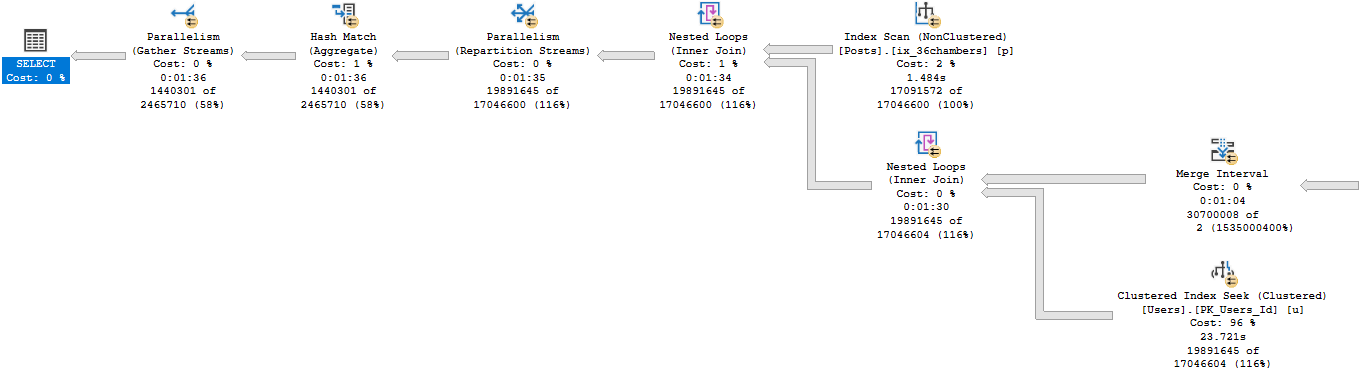
24 seconds seeking into the Users table and joining that to the results of the Constant Scans, etc.
What’s a little confusing here is that the scan on the Posts table occurs on the outer side of Nested Loops.
It’s also responsible for feeding rows through the Constant Scans. That’s their data source.
Overall, this query takes 1:36 seconds to run.
My gripe with it is that it’s possible to rewrite this query in an obvious way to fix the problem.
Magick
Using a second join to Posts clears things up quite a bit.
SELECT u.Id, MAX(p.Score)
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON u.Id = p.OwnerUserId
AND p.PostTypeId IN (1, 2)
JOIN dbo.Posts AS p2
ON u.Id = p2.LastEditorUserId
AND p2.PostTypeId IN (1, 2)
GROUP BY u.Id;
I know, it probably sounds counterintuitive to touch a table twice.
Someone will scream that we’re doing more reads.
Someone else will faint at all the extra code we wrote.
But when we run this query, it finishes in 10 seconds.

This plan does something a bit different. It joins the nonclustered index we have on Posts to itself.
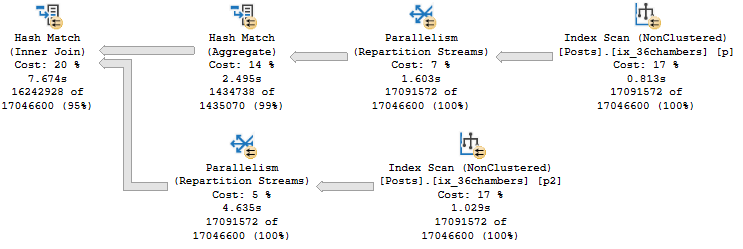
The optimizer has a rule that makes this possible, called Index Intersection.
Extra Magick
A more accurate description of what I’d want the optimizer to consider here would be the plan we get when we rewrite the query like this.
SELECT u.Id, MAX(p.Score)
FROM dbo.Users AS u
CROSS APPLY
(
SELECT p.Score
FROM dbo.Posts AS p
WHERE u.Id = p.OwnerUserId
AND p.PostTypeId IN (1, 2)
UNION ALL
SELECT p2.Score
FROM dbo.Posts AS p2
WHERE u.Id = p2.LastEditorUserId
AND p2.PostTypeId IN (1, 2)
) AS p
GROUP BY u.Id;
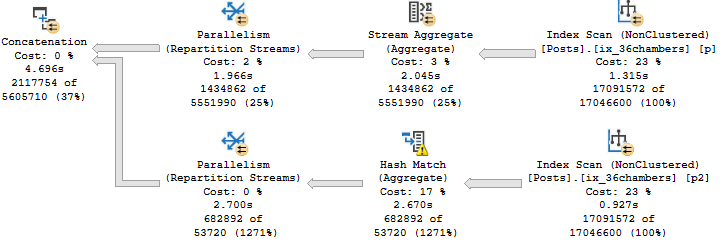
This query runs a bit faster than the second one (around 7 seconds), and the plan is a little different.
Rather than a Hash Join between the index on the Posts table, we have a Concatenation operator.
The rest of the plan looks like this:
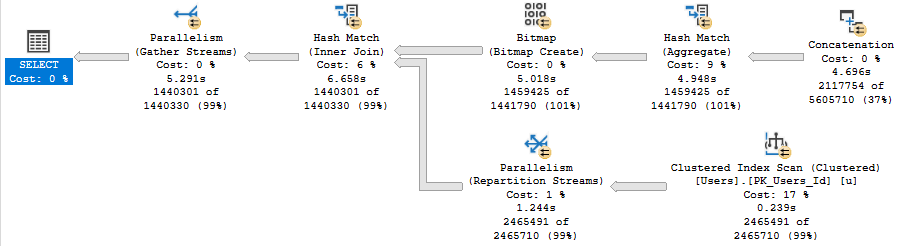
The optimizer has a rule that can produce this plan, too, called Index Union.
Problemagick
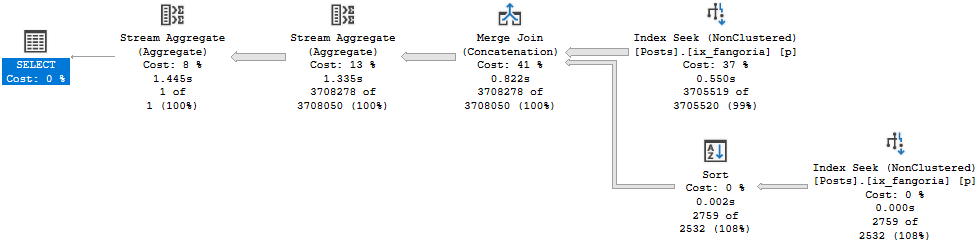
The thing is, these rules seem to be favored more with WHERE clauses than with JOINs.
CREATE INDEX ix_fangoria
ON dbo.Posts(ClosedDate);
SELECT COUNT_BIG(*) AS records
FROM dbo.Posts AS p
WHERE p.ClosedDate IS NULL
OR p.ClosedDate >= '20170101'
AND 1 = (SELECT 1);
CREATE INDEX ix_somethingsomething
ON dbo.Posts(PostTypeId);
CREATE INDEX ix_wangchung
ON dbo.Posts(AcceptedAnswerId);
SELECT COUNT_BIG(*) AS records
FROM dbo.Posts AS p
WHERE p.PostTypeId = 1
AND p.AcceptedAnswerId = 0
AND 1 = (SELECT 1);
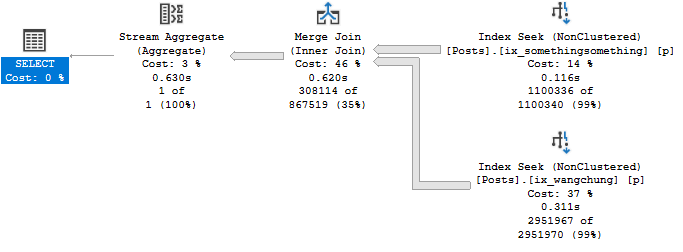
Knackered
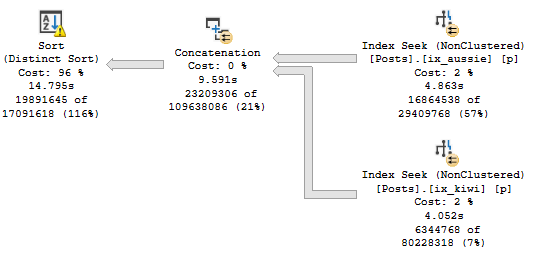
It is possible to get these kind of plans with joins, but not without join hints and a couple indexes.
CREATE INDEX aussie
ON dbo.Posts (OwnerUserId, PostTypeId, Score);
CREATE INDEX kiwi
ON dbo.Posts (LastEditorUserId, PostTypeId, Score);
SELECT u.Id, MAX(p.Score)
FROM dbo.Users AS u
JOIN dbo.Posts AS p
WITH (FORCESEEK)
ON u.Id = p.OwnerUserId
OR u.Id = p.LastEditorUserId
WHERE p.PostTypeId IN (1, 2)
GROUP BY u.Id;
There’s more background from, of course, Paul White, here and here.
Even with Paul White ~*~Magick~*~, the hinted query runs for ~16 seconds.
If you remember, the Index Intersection plan ran for around 10 seconds, and the Index Union plan ran for around 7 seconds.
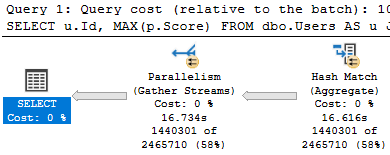
This plan uses Index Union:
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Hi Erik,
I’m not sure the query in the first Magick section is correct? Wouldn’t having two inner joins to the posts table only return records where the user Id is in both OwnerUserId and LastEditorUserId fields?
Re-writing it to use two left outer joins with a COALESCE() call brings back the expected results on my system
SELECT u.Id,
/*because the score could come from either post table join, use a COALESCE() function*/
MAX(COALESCE(p.Score, p2.score))
FROM dbo.Users AS u
LEFT JOIN dbo.Posts AS p
ON u.Id = p.OwnerUserId
AND p.PostTypeId IN (1, 2)
LEFT JOIN dbo.Posts AS p2
ON u.Id = p2.LastEditorUserId
AND p2.PostTypeId IN (1, 2)
GROUP BY u.Id;
Or, I could be reading it wrong, it’s first thing in the morning this side of the pond
Keep up the good work
Hi,
Have thought about it some more, and the solution in the first Magick section only works for users that have an entry in both OwnerUserId and LastEditorUserId.
I don’t have SO database to test whether this is always true for this particular dataset, but conceivably a user could have a single post that they are the owner of, but that was last edited by someone else, in which case one of the two inner joins wouldn’t return anything so they would be excluded from the resultset.
I think, could still be barking up the wrong tree
Hi Ross!
No, you’re right. The query just gave me the plan shape I wanted to show people quickly.
Thanks,
Erik