ANSI Blandard
Sometimes there are very good reasons to use either coalesce or isnull, owing to them having different capabilities, behaviors, and support across databases.
But isnull has some particular capabilities that are interesting, despite its limitations: only two arguments, specific to SQL Server, and uh… well, we can’t always get three reasons, as a wise man once said.
There is one thing that makes isnull interesting in certain scenarios. Let’s look at a couple.
Green Easy
First, we’re gonna need an index.
CREATE INDEX party
ON dbo.Votes
(CreationDate, VoteTypeId)
INCLUDE
(UserId);
Yep, we’ve got an index. Survival of the fittest.
Here are some queries to go along with it. Wouldn’t want our index getting lonely, I suppose.
All that disk entropy is probably scary enough.
SELECT TOP (10)
u.DisplayName
FROM dbo.Users AS u
WHERE NOT EXISTS
(
SELECT
1/0
FROM dbo.Votes AS v
WHERE v.UserId = u.Id
AND v.VoteTypeId IN (1, 2, 3)
AND ISNULL(v.CreationDate, '19000101') > '20131201'
)
ORDER BY u.CreationDate DESC;
SELECT TOP (10)
u.DisplayName
FROM dbo.Users AS u
WHERE NOT EXISTS
(
SELECT
1/0
FROM dbo.Votes AS v
WHERE v.UserId = u.Id
AND v.VoteTypeId IN (1, 2, 3)
AND COALESCE(v.CreationDate, '19000101') > '20131201'
)
ORDER BY u.CreationDate DESC;
Pager Back
The first query uses isnull, and the second query uses coalesce. Just in case that wasn’t obvious.
I know, I know — I’ve spent a long time over here telling you not to use isnull in your where clause, lest ye suffer the greatest shame to exist, short of re-gifting to the original gift giver.
Usually, when you wrap a column in a function like that, bad things happen. Seeks turn into Scans, wine turns into water, spaces turn into tabs, the face you remember from last call turns into a November Jack O’Lantern.
But in this case, the column wrapped in our where clause, which is the leading column of the index, is not nullable.
SQL Server’s optimizer, having its act together, can figure this out and produce an Index Seek plan.
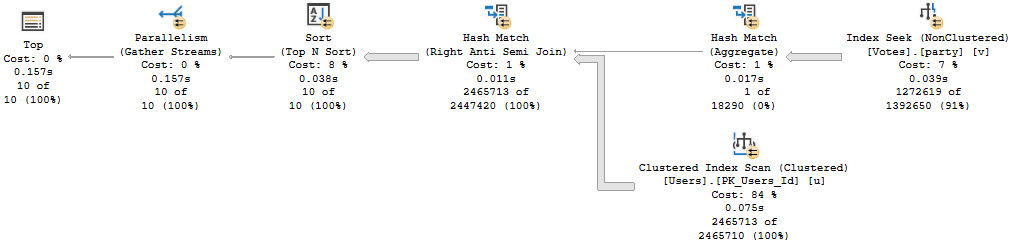
The null check is discarded, and end up with a Seek to the CreationDate values we care about, and a Residual Predicate on VoteTypeId.

Big Famous
The second query, the one that uses coalesce, has a few things different about it. Let’s cut to the plan.
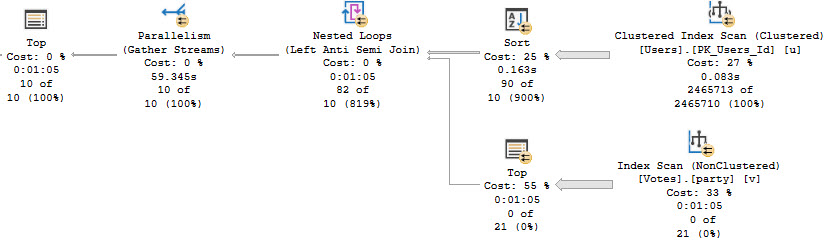
Rather than 157ms, this query runs for over a minute by five seconds. All of the time is spent in the Top > Index Scan. We no longer get an Index Seek, either.

Notice that the predicate on CreationDate is a full-on case expression, checking for null-ness. This could be an okay scenario if we had something to Seek to, but without proper indexing and properly written queries, it’s el disastero.
The reason that the query changes is due to the optimizer deciding that a row goal would make things better. This is why we have a Nested Loops Join, and the Top > Index Scan. It doesn’t work out very well.
This isn’t the only time you might see this, but it’s probably the worst.
SUBTLERY
You can also see this with a pattern I often advocate against, using a Left Join to find rows that don’t exist:
SELECT TOP (10)
u.DisplayName
FROM dbo.Users AS u
LEFT JOIN dbo.Votes AS v
ON v.UserId = u.Id
AND v.VoteTypeId IN (1, 2, 3)
AND ISNULL(v.CreationDate, '19000101') > '20131201'
WHERE v.Id IS NULL
ORDER BY u.CreationDate DESC;
SELECT TOP (10)
u.DisplayName
FROM dbo.Users AS u
LEFT JOIN dbo.Votes AS v
ON v.UserId = u.Id
AND v.VoteTypeId IN (1, 2, 3)
AND COALESCE(v.CreationDate, '19000101') > '20131201'
WHERE v.Id IS NULL
ORDER BY u.CreationDate DESC;
It’s not as bad here, but it’s still noticeable.
The plan with isnull looks about like so:
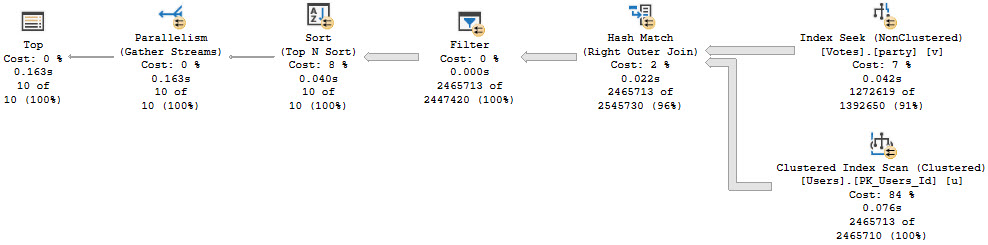
At 163ms, there’s not a lot to complain about here.
The coalesce version does far worst, at just about 1.5 seconds.
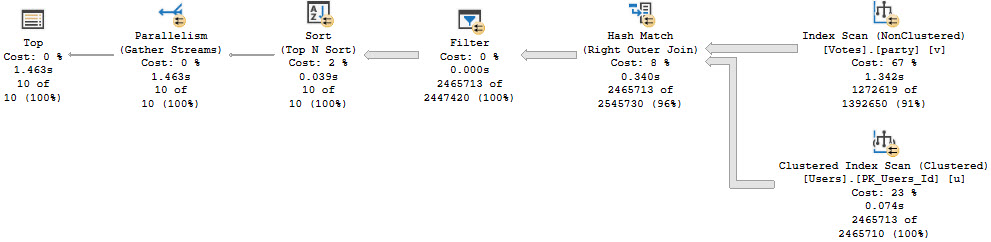
We Learned Some Things
In SQL Server, using functions in where clauses is generally on the naughty list. In a narrow case, using the built-in isnull function results in better performance than coalesce on columns that are not nullable.
This pattern should generally be avoided, of course. On columns that are nullable, things can really go sideways in either case. Of course, this matters most when the function results in an otherwise possible Index Seek is impossible, and we can only use an Index Scan to find rows.
An additional consideration is when we can Seek to a very selective set of rows first. Say we can get things down to (for the purposes of explanation only) around 1000 rows with a predicate like Score > 10000.
For the remaining 1000 rows, it’s not likely that an additional Predicate like the ones we saw today would have added any drama to the execution time of a relatively simple query.
They may, however, lead to poor cardinality estimates in more complicated queries.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I think it is more detailed here
https://michaeljswart.com/2018/03/t-sql-options-for-comparing-distinctness/
No, these are two different concepts. Thanks, though.
Interesting: What’s the best way to achieve this pattern?
Given: (a) Column A is nullable for both tables, (b) I want to ensure that DestTable ends up just like SrcTable, (c) I’m trying not to “churn” the entire DestTable when only a few rows need modifications, (d) I might have “n” columns to do this with (whereas only ColumnA is shown). Thanks!
ISNULL sounds like it only helps if column is non-null (this is nullable). Better pattern?
UPDATE d
SET ColumnA = s.ColumnA
FROM DestTable d
JOIN SrcTable s ON s.DezzyId = d.Id
WHERE COALESCE(d.ColumnA, ”) != COALESCE(s.ColumnA, ”)
For performance questions, head over to http://dba.stackexchange.com/