Handcuffed
When you’re looking for queries to tune, it’s important to understand which part is causing the slowdown.
That’s why Actual Execution plans are so valuable in newer versions of SQL Server and SSMS. Getting to see operator timing and wait stats for a query can tell you a lot about what kind of problem you’re facing.
Let’s take a look at some examples.
Diskord
If you’re looking at a query plan, and all the time is spent way to the right, when you’re reading from indexes, it’s usually a sign of one or two things:
- You’re missing a good index for the query
- You don’t have enough memory to cache data relevant to the query
If you run the query a second time, and it has the same characteristics — meaning we should now have the data cached in the buffer pool but we don’t — then one or both of those two things is true.
If you run the query a second time and it’s fast because all the data we care about is cached, then it’s more likely that only the second thing is true.

For example, every time I run this query it takes 20 seconds because every time it has to read the clustered index from disk into memory to get a count. That’s because my VM has 96 GB of RAM, and the clustered index of the Posts table is about 120 GB. I can’t fit the whole thing into the buffer pool, so each time I run this query has the gas station sushi effect on the buffer pool.
If I add a nonclustered index — and keep in mind I don’t really condone adding single key column nonclustered indexes like this — the query finishes much faster, because the smaller nonclustered index takes less time to read, and it fits into the buffer pool.
CREATE INDEX pr ON dbo.Posts
(
Id
);

If our query had different characteristics, like a where clause, join, group by, order by, or windowing function, I’d consider all of those things for the index definition. Just grabbing a count can still benefit from a smaller index, but there’s nothing relational that we need to account for here.
Proc Rock
Let’s say you already have ideal indexes for a query, but it’s still slow. Then what?
There are lots of possible reasons, but we’re going to examine what a CPU bound query looks like. A good example is one that needs to process a lot of rows, though not necessarily return a lot of rows, like a count or other aggregate.
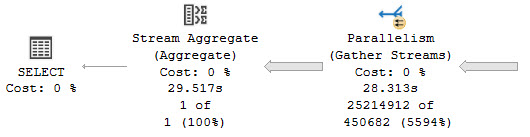
While this query runs, CPUs are pegged like suburban husbands.

For queries of this stature, inducing batch mode is often the most logical choice. Why? Because CPU instructions are run over batches of rows at once, rather than a single row at a time.
With a small number of rows — like in an OLTP workload — you probably won’t notice any real gains. But for this query that takes many millions of rows and produces an aggregate, it’s Hammer Time™

Rather than ~30 seconds, we can get our query down to ~8 seconds without making a single other change to the indexes or written form.
Under Compression
For truly large data sets, compression indexes is a great choice for further reducing I/O bound portions of queries. In SQL Server, you have row, page, and column store (clustered and nonclustered) compression available to you based on the type of workload you’re running.
When you’re tuning a query, it’s important to keep the type of bottleneck you’re facing in mind. If you don’t, you can end up trying to solve the wrong problem and getting nowhere.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
great post Erik, but can you explain what you mean by “gas station sushi effect”
Grand opening, grand closing