One Who Overflew
In the Stack Overflow database, the biggest (and probably most important) table is Posts.
The Comments table should be truncated hourly. Comments were a mistake.
But the Posts table suffers from a serious design flaw in the public data dump: Questions and Answers are in the same table.
I’ve heard that it’s worse behind the scenes, but I don’t have any additional details on that.
Aspiring Aspirin
This ends up with some weird data distributions. Certain attributes can only ever be “true” for a question or an answer.
For example, only questions can have a non-zero AcceptedAnswerId, or AnswerCount. Some questions might have a ClosedDate, or a FavoriteCount, too. In the same way, only answers can have a ParentId. This ends up with some really weird patterns in the data.

Was it easier at first to design things this way? Probably. But introducing skew like this only makes dealing with parameter sniffing issues worse.
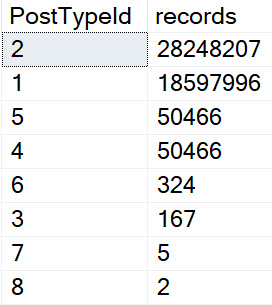
Even though questions and answers are the most common types of Posts, they’re not the only types of Posts. Even if you make people specify a type along with other things they’re searching for, you can end up with some really different query plans.
Designer Drugs
When you’re designing tables, try to keep this sort of stuff in mind. It might not be a big deal for small tables, but once you realize your data is getting big, it might be too late to make the change. It’s not just a matter of changes to the database, but the application, too.
Late stage redesigns often lead to the LET’S JUST REWRITE THE WHOLE APPLICATION FROM THE GROUND UP projects that take years and usually never make it.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Related Posts
- SQL Server 2022 CTP 2.1 Improvements To Parameter Sensitive Plan Optimization
- SQL Server 2022 Parameter Sensitive Plan Optimization: Does Not Care To Fix Your Local Variable Problems
- SQL Server 2022 Parameter Sensitive Plan Optimization: How PSP Can Help Some Queries With IF Branches
- SQL Server 2022 Parameter Sensitive Plan Optimization: Sometimes There’s Nothing To Fix
You’re not wrong but it’s definitely swings & roundabouts.
My last company started with specific comment types in specific tables. Each new comment type spawned a new table which goes completely to hell when you are asked to show a properly threaded history. Or (and there’s no solution for this) someone thinks that they want it all in a spread sheet.
It also makes dev really slow because nobody will ever permit a copy-paste design because they visualise internal notes as something fundamentally different to the consumer comment… so you proliferate supporting code and suddenly you have: comment/int note/reply/action/… which means huge changes for “simple” requests or new features with less functionality because if you had considered it before you would have the hooks.
So in our second design which did take ages to roll out we went to single column. Now the devs just had to decide how to manage the type in the front-end. I’m not saying we didn’t have interesting challenges but far fewer than with the multi-table design
The advantage to the single comments table is that time is correctly captured, threading still requires getting the parent record correctly but is comparatively simple.
Threading multi-table conversations is the stuff of madness.
That sounds like the other end of the spectrum. I would probably not normalize to that extreme, either.
In the Stack databases, there are a limited number of post types, and questions and answers make up the majority.
I would probably opt for questions, answers, and other. Right now, Comments already have a separate table.
Thanks!