Led Better
In yesterday’s post, we looked at MSTVFs. Today, we’re going to look at inlined functions.
And I know, that sounds weird. But it’s because we’re going to circle back to scalar valued functions, and how they’re inlined in SQL Server 2019 as well.
There’s stuff in here you’ll have to look out for when you move to SQL Server 2019.
Side By Side
The first thing we need is the function itself, which is just an inlined version of the others.
CREATE OR ALTER FUNCTION dbo.CommentsAreHorribleInline(@Id INT) RETURNS TABLE WITH SCHEMABINDING AS RETURN SELECT (SELECT SUM(Score) FROM dbo.Posts AS p WHERE p.OwnerUserId <= @Id) - (SELECT COUNT_BIG(*) FROM dbo.Comments AS c WHERE c.UserId <= @Id) AS Tally GO
Where these differ from both kinds of functions, is that you can’t find them ANYWHERE on their own.
They don’t appear in any DMVs, or in the plan cache as isolated code. Since they’re inlined, it’s just a part of whatever query references it.
Let’s start simple, though:
SELECT * FROM dbo.CommentsAreHorribleInline(22656); SELECT * FROM dbo.CommentsAreHorribleInline(138);
Like in the other posts, the chief difference between these two plans is the index access choice.
The 22656 plan scans the clustered index, and the 138 plan does a nonclustered index seek with a key lookup.
Check the other posts in the series for pictures of that if you’re interested.
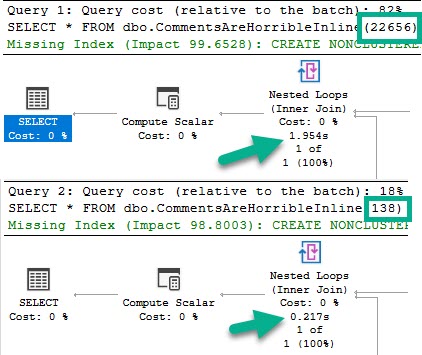
As in the other examples, the clustered index scan is considerably slower than the nonclustered index seek plan.
But that’s not where things are interesting. Where they’re interesting is when we call the function in a “larger” query.
SELECT TOP (5) u.DisplayName,
(SELECT * FROM dbo.CommentsAreHorribleInline(u.Id))
FROM dbo.Users AS u
GO
Spool And Spool Alike
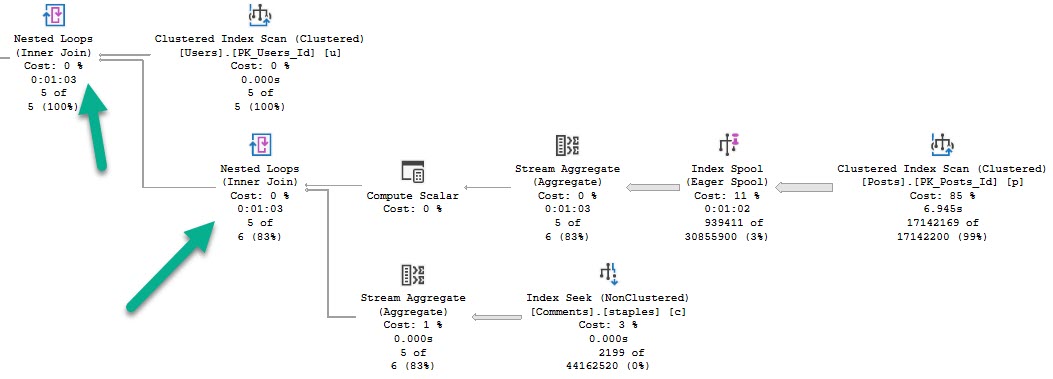
This query runs for a full minute.

We see why early on — an eager index spool.
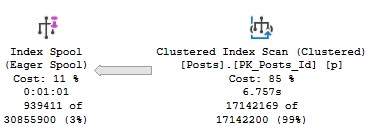
This appears to happen because the optimizer is drunk as hell doesn’t like the idea of scanning the clustered index, or recycling the seek + lookup 5 times.
The index reflects what a two column clustered index keyed on OwnerUserId would look like.
Think about it like if you selected OwnerUserId and Score into a #temp table and put a clustered index on the table with the key on OwnerUserId.
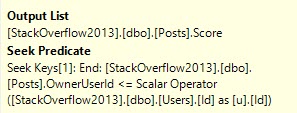
Remember that part of the reason for this plan change is that we’re no longer just subtracting one aggregate from another like when we call the function on its own, there’s the additional “join” to the Users table. Correlated subqueries are just that — joins.
Futurist
I’d love to have more to say about how this changes in SQL Server 2019, but an identical pattern occurs, similar to what I blogged about earlier in the summer.
I caught some private flack about how the TOP (1) pattern in that post could easily be replace with an aggregate like MIN.
While that’s totally true, there’s no similar replacement for this pattern. We could expand the index to cover the Score column to get rid of the spool, which goes back to another post I wrote about 2019 optimizer features, where you’ll need wider (covering) indexes for them to be used.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.