Dodo
We’ve got a set of missing index requests for a single table, and we’ve got the queries asking for them.
Going back to our queries and our index requests, all the queries have two things in common:
- They filter on OwnerUserId
- They order by Score
There are of course other elements in the where clause to attend to, but our job is to come up with one index that helps all of our queries.
Query Real Hard
To recap, these are our queries.
SELECT TOP (10)
p.*
FROM dbo.Posts AS p
WHERE p.OwnerUserId = 22656
ORDER BY p.Score DESC;
GO 10
SELECT TOP (10)
p.*
FROM dbo.Posts AS p
WHERE p.OwnerUserId = 22656
AND p.CreationDate >= '20130101'
ORDER BY p.Score DESC;
SELECT TOP (10)
p.*
FROM dbo.Posts AS p
WHERE p.OwnerUserId = 22656
AND p.PostTypeId = 1
ORDER BY p.Score DESC;
SELECT TOP (10)
p.*
FROM dbo.Posts AS p
WHERE p.OwnerUserId = 22656
AND p.LastActivityDate >= '20130101'
ORDER BY p.Score DESC;
SELECT TOP (10)
p.*
FROM dbo.Posts AS p
WHERE p.OwnerUserId = 22656
AND p.Score > 0
ORDER BY p.Score DESC;
Index Real Dumb
Which means that all of our missing index requests are going to be on maybe a couple key columns, and then include every other column in the Posts table.
This is a bad idea, so we’re going to dismiss the includes and focus on keys.
CREATE INDEX [OwnerUserId_LastActivityDate_Includes]
ON [StackOverflow2013].[dbo].[Posts] ([OwnerUserId], [LastActivityDate]);
CREATE INDEX [OwnerUserId_Score_Includes]
ON [StackOverflow2013].[dbo].[Posts] ([OwnerUserId], [Score]);
CREATE INDEX [OwnerUserId_PostTypeId_Includes]
ON [StackOverflow2013].[dbo].[Posts] ([OwnerUserId], [PostTypeId]);
CREATE INDEX [OwnerUserId_CreationDate_Includes]
ON [StackOverflow2013].[dbo].[Posts] ([OwnerUserId], [CreationDate]);
CREATE INDEX [OwnerUserId_Includes]
ON [StackOverflow2013].[dbo].[Posts] ([OwnerUserId]);
Now that we’ve got a more sane bunch of requests to focus on, let’s do something thinking.
I hate thinking, so we won’t do a lot of it.
Indexes put data in order, and equality predicates preserve ordering of secondary index columns. That makes putting the key on (OwnerUserId, Score) a no-brainer. One could make an entire career out of avoiding sorting in the database.
But now we have three other columns to think about: LastActivityDate, PostTypeId, and CreationDate.
We could spend a whole lot of time trying to figure out the best order here, considering things like: equality predicates vs inequality predicates, and selectivity, etc.
But what good would it do?
Dirty Secret
No matter what order we might put index key columns in after Score, it won’t matter. Most of our queries don’t search on OwnerUserId and then Score. Only one of them does, and it doesn’t search on anything else.
That means that most of the time, we’d be seeking to OwnerUserId, and then performing residual predicates against other columns we’re searching on.
On top of that, we’d have whatever overhead there is of keeping things in order when we modify data in the key of the index. Not that included columns are free-of-charge to modify, but you get my point. There’s no order preserved in them.
In reality, a good-enough-index for the good-enough-optimizer to come up with a good-enough-plan looks like this:
CREATE INDEX good_enough
ON dbo.Posts
(OwnerUserId, Score)
INCLUDE
(PostTypeId, CreationDate, LastActivityDate);
Planama
The index above does two things:
- It helps us search on a selective predicate on OwnerUserId
- It keeps Score in order after the quality so the order by is free
- It has all the other potential filtering elements so we can apply predicates locally
- It teaches us that include column order doesn’t matter
All of the query plans will look roughly like this, regardless of the where clause:
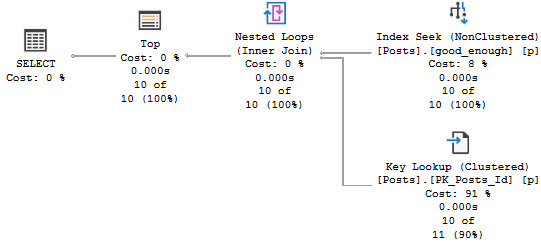
What Difference Does It Make?
Alright, so we’ve got one good-enough index for a bunch of different queries. By adding the index, we got all of them to go from taking ~600ms to taking 0ms.
What else did we do?
- We made them faster without going parallel
- They no longer need memory to sort data
And we did it without creating a gigantic covering index.
Of course, the optimizer still thinks we need indexes…

But do we really need them?
No.
77% of nothing is nothing.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
One thought on “Deduplicating SQL Server Missing Index Requests Part 3”
Comments are closed.