Headed Serial
Getting it out of the way, yes, we can create this nonclustered row store index to store our data in oh-so-perfect order for the windowing function:
CREATE INDEX row_store
ON dbo.Comments
(
UserId,
CreationDate
);
Keeping in mind that sort direction matters in how you write your query and define your index, this particular topic has, in my mind, been done to death.
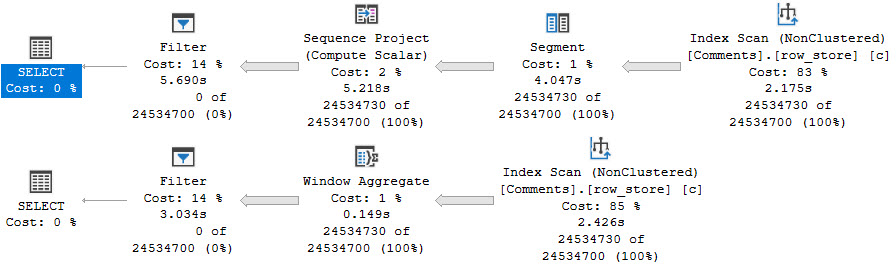
Look ma, no Sort! Whoopie.
We also get serial plans. For the row store query, it’s about twice as fast, even single-threaded.
For the column store query, it’s about twice as slow.
Headed Parallel
Here are some interesting things. You’re going to want to speak to the manager.
Let’s force these to go parallel. For science.
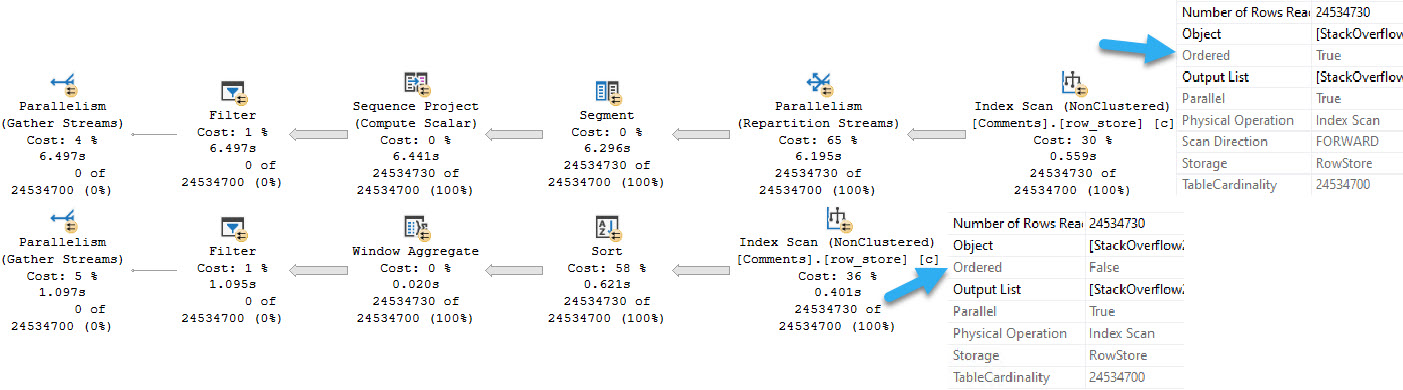
Not only is the parallel version of the row mode plan a full second slower, but… look at that batch mode plan.
Look at it real close. There’s a sort before the Window Aggregate, despite reading from the same nonclustered index that the row mode plan uses.
But the row mode plan doesn’t have a Sort in it. Why? Because it reads ordered data from the index, and the batch mode plan doesn’t.
This must be hard to do, with all the support added for Batch Mode stuff, to still not be able to do an ordered scan of the data.
For those of you keeping track at home: yes, we are sorting sorted data.
Column-Headed
Let’s try an equivalent column store index:
CREATE COLUMNSTORE INDEX column_store_ordered
ON dbo.Comments
(
UserId,
CreationDate
)
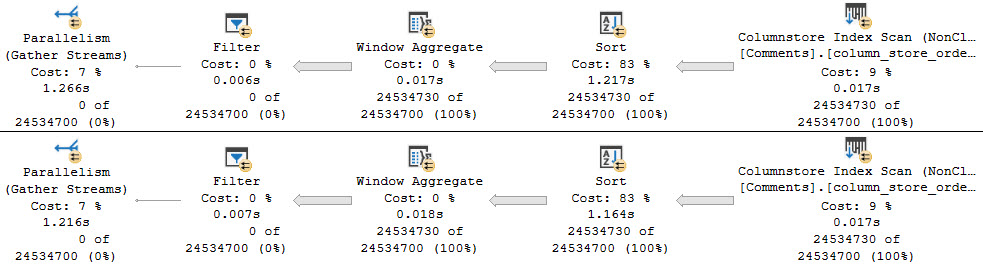
Both have to sort, but both are fast and parallel. Yes, Sorting is annoying. Unfortunately, we can’t do this Sort in the application.
But hey, look how fast those index scans are. Choo-choo, as a wise man once said.
And of course, since we have to sort anyway, we’d be better off creating a wide nonclustered column store index on the table, so it would be more generally useful to more queries. You only get one per table, so it’s important to choose wisely.
If you have queries using window functions where performance is suffering, it might be wise to considered nonclustered column store indexes as a data source for them. Beyond just tricking the optimizer into using Batch Mode, the data compression really helps.
Elsewise
But there’s something else to consider, here: the plans with Sorts in them require memory.
It’s not much here — about 570MB — but in situations where more columns are needed for the query, they could get much larger.
And you know what can happen then. We’ll look at that in tomorrow’s post.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.