Pantsuit
Most people see a lookup and think “add a covering index”, regardless of any further details. Then there they go, adding an index with 40 included columns to solve something that isn’t a problem.
You’ve got a bright future in government, kiddo.
In today’s post, we’re going to look at a few different things that might be going on with a lookup on the inside.
But first, we need to talk about how they’re possible.
Storage Wars
When you have a table with a clustered index, the key columns of it will be stored in all of your nonclustered indexes.
Where they get stored depends on if you define the nonclustered index as unique or not.
So you can play along at home:
DROP TABLE IF EXISTS #tabs, #spaces;
CREATE TABLE #tabs
(
id int NOT NULL PRIMARY KEY,
next_id int NOT NULL,
INDEX t (next_id)
);
CREATE TABLE #spaces
(
id int NOT NULL PRIMARY KEY,
next_id int NOT NULL,
INDEX s UNIQUE (next_id)
);
INSERT
#tabs (id, next_id)
VALUES (1, 2);
INSERT
#spaces (id, next_id)
VALUES (1, 2);
Here are two tables. Both definitions are identical, with the exception of the nonclustered index on #spaces. It is unique.
Like you.
You’re so special.
Findings
These queries are special, too.
SELECT
t.*
FROM #tabs AS t WITH(INDEX = t)
WHERE t.id = 1
AND t.next_id = 2;
SELECT
s.*
FROM #spaces AS s WITH(INDEX = s)
WHERE s.id = 1
AND s.next_id = 2;
The query plans for these queries have a slight difference, too.

The non-unique index supports two seek predicates. The unique index has one seek plus a residual predicate.
No lookup is necessary here, because in both cases the clustered index key columns are in the nonclustered index. But this is also how lookups are made possible.
We can locate matching rows between clustered and nonclustered indexes.
Unfortunately, we’re all out of columns in this table, so we’re gonna have to abandon our faithful friends to the wilds of tempdb.
Garbaggio
I’m sure I’ve talked about this point before, but lookups can be used to both to output columns and to evaluate predicates in the where clause. Output columns can be from any part of the query that asks for columns that aren’t in our nonclustered index.
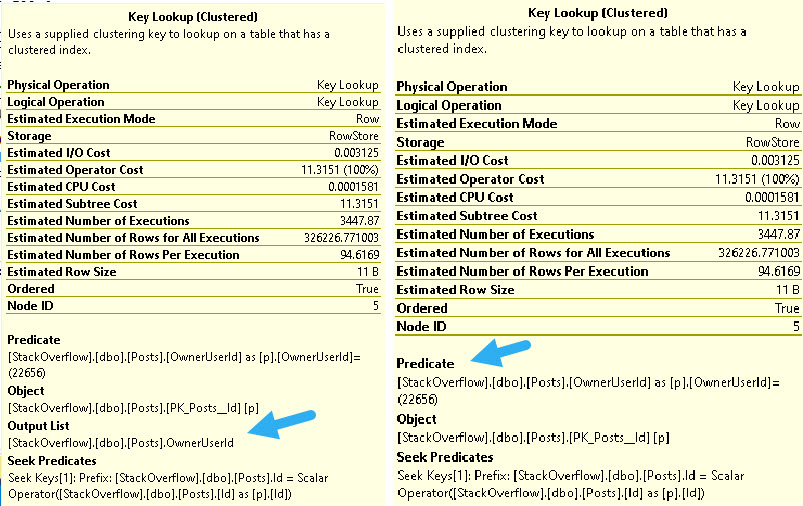
The Seek predicate you see at the bottom of both of these tool tips is the relationship between the two indexes, which will be the clustered index key columns.
Big More
We’re going to start and end with this index:
CREATE INDEX x ON dbo.Posts(CreationDate);
It’s just that good. Not only did it provide us with the screenshots up above, but it will also drive all the rest of the queries we’re going to look at.
Stupendous.
The clustered index on the Posts table is called Id. Since we have a non-unique index, that column will be stored and ordered in the key of the index.
The things we’re going to look at occurring in the context of lookups are:
- Explicit Sorts
- Implicit Sorts
- Ordered Prefetch
- Unordered Prefetch
You’ll have to wait until tomorrow for the prefetch stuff.
Banned In The USA
Let’s start with this query!
SELECT
AverageWhiteBand =
AVG(p.Score)
FROM dbo.Posts AS p
WHERE p.CreationDate >= '20190323';
Since we have an inequality predicate on CreationDate, the order of the Id column is no longer preserved on output.
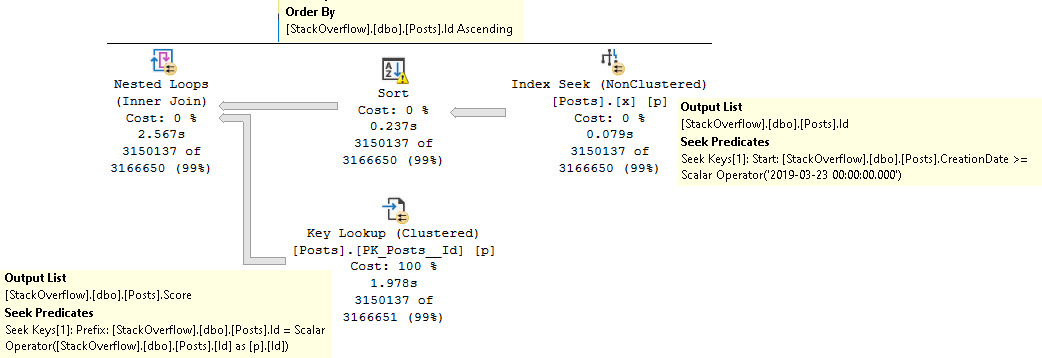
The query plan, from right to left:
- Seeks into our magnificent index
- Sorts the output Id column
- Seeks back into the clustered index to get the Score column
The sort is there to put the Id column in a friendlier order for the join back to the clustered index.
Implicit Lyrics
If we change the where clause slightly, we’ll get a slightly different execution plan, with a hidden sort.
SELECT
AverageWhiteBand =
AVG(p.Score)
FROM dbo.Posts AS p
WHERE p.CreationDate >= '20190923'
In the properties of the nested loops join, we’ll see that it has consumed a memory grant, and that the Optimized property is set to True.
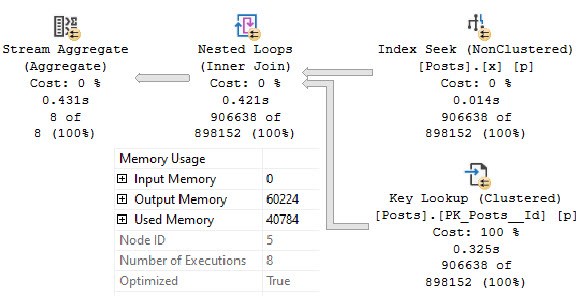
Much more common memory grants are for Sorts and Hashes. The details are available on Craig Freedman’s blog:
Notice that the nested loops join includes an extra keyword: OPTIMIZED. This keyword indicates that the nested loops join may try to reorder the input rows to improve I/O performance. This behavior is similar to the explicit sorts that we saw in my two previous posts, but unlike a full sort it is more of a best effort. That is, the results from an optimized nested loops join may not be (and in fact are highly unlikely to be) fully sorted.
SQL Server only uses an optimized nested loops join when the optimizer concludes based on its cardinality and cost estimates that a sort is most likely not required, but where there is still a possibility that a sort could be helpful in the event that the cardinality or cost estimates are incorrect. In other words, an optimized nested loops join may be thought of as a “safety net” for those cases where SQL Server chooses a nested loops join but would have done better to have chosen an alternative plan such as a full scan or a nested loops join with an explicit sort. For the above query which only joins a few rows, the optimization is unlikely to have any impact at all.
The reason I’m fully quoting it here rather than just linking is because when I went to go find this post, I realized that I have four bookmarks to Craig’s blog, and only one of them works currently. Microsoft’s constant moving and removing of content is a really frustrating, to say the least.
Looky Looky
Lookups have a lot of different aspects to them that make them interesting. This post has some additional interesting points to me because of the memory grant aspect. I spend a lot of time tinkering with query performance issues related to how SQL Server uses and balances memory.
In tomorrow’s post, we’ll take a high-level look at prefetching. I don’t want to get too technical on the 20th day of the 4th month of the calendar year.
It may not be the best time to require thinking.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
“You’ve got a bright future in government, kiddo.” – oh the lolz
?