The documentation on delta rowgroups says:
A delta rowgroup is a clustered index that’s used only with columnstore indexes. It improves columnstore compression and performance by storing rows until the number of rows reaches a threshold and are then moved into the columnstore.
This clustered index isn’t chosen by the person who creates the table. It’s a hidden internal column automatically added to delta rowgroups. Perhaps the implementation is similar to that of table spools:
The worktable is structured as if it was defined with a clustered index on zero columns. This means that a 4-byte uniqueifier is added to each row stored except the first.
You know how programmers are: they love reusing old code. If a similar implementation is used for delta rowgroups then it should be possible to see SQL Server errors with the right pattern of data loading. More investigation is required.
Defining the rules
It might be possible to find evidence of this clustered index by using DBCC PAGE. In the T-SQL code below, I create a table clustered columnstore index, insert 500 rows, delete 499 rows, insert 500 more rows, and delete 499 rows again:
CREATE TYPE dbo.SEAN_GALLARDY_INT FROM SMALLINT NOT NULL; DROP TABLE IF EXISTS dbo.view_hidden_clustered_index; CREATE TABLE dbo.view_hidden_clustered_index ( ID SEAN_GALLARDY_INT, INDEX CCI CLUSTERED COLUMNSTORE ); GO CREATE OR ALTER PROCEDURE #p AS BEGIN SET NOCOUNT ON; DECLARE @value_to_insert INT = 1; WHILE @value_to_insert <= 500 BEGIN INSERT INTO dbo.view_hidden_clustered_index VALUES (@value_to_insert); SET @value_to_insert = @value_to_insert + 1; END; DELETE FROM dbo.view_hidden_clustered_index WHERE ID < 500; WHILE @value_to_insert <= 1000 BEGIN INSERT INTO dbo.view_hidden_clustered_index VALUES (@value_to_insert); SET @value_to_insert = @value_to_insert + 1; END; DELETE FROM dbo.view_hidden_clustered_index WHERE ID > 500 AND ID < 1000; END; GO EXEC #p;
There’s only a single page that stores the 2 rows currently held by the table. This can be viewed with the undocumented DBCC PAGE, TF 3604, and the undocumented sys.dm_db_database_page_allocations:
DECLARE @file_id SEAN_GALLARDY_INT;
DECLARE @page_id INT;
SELECT @file_id = allocated_page_file_id, @page_id = allocated_page_page_id
FROM sys.dm_db_database_page_allocations
(DB_ID(), OBJECT_ID('dbo.view_hidden_clustered_index'),NULL, NULL, 'DETAILED')
WHERE is_allocated = 1 AND allocation_unit_type = 1 AND is_iam_page = 0 and page_type = 1;
DBCC TRACEON(3604);
DBCC PAGE('TEST',@file_id,@page_id,3) WITH TABLERESULTS;
DBCC TRACEOFF(3604);
The information that we’re looking for is near the bottom of the result set:
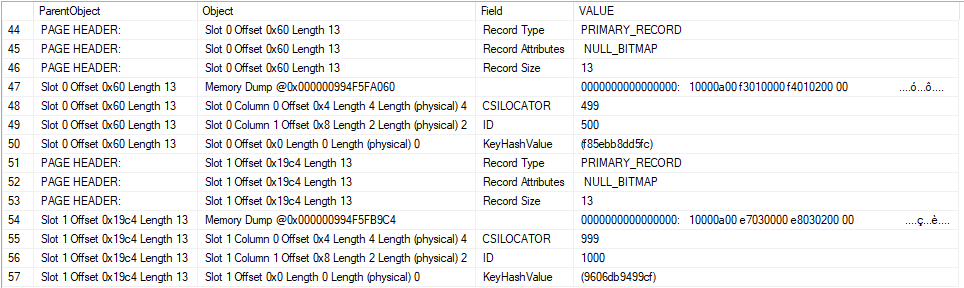
A few things are worth calling out. The 500th row that was inserted into the table has a value of 499 for the “CSILOCATOR” field. This value appears to be stored in little-endian format in the memory dump for Slot 0 Offset 0x60. You can decode the raw value to 499 in T-SQL if desired:
SELECT CAST(0x000001F3 AS INT);
The 1000th row that was inserted into the table into the table has a value of 999 for the CSILOCATOR field. Most importantly, this CSILOCATOR field has a length of four bytes. A typical four byte int in SQL Server has a maximum value of 2147483647. If it’s possible to load billions of rows into a single delta rowgroup then we may run out of values for the CSILOCATOR field.
Of course, a single delta rowgroup cannot hold more than 1048576 rows. As you can see in this example, SQL Server does not always reuse freed up values for the CSILOCATOR field. The table currently has two rows, yet the field has advanced to 999. The right pattern of deletes, inserts, and updates should allow the CSILOCATOR to continue to grow without running out of room for rows in the delta rowgroup.
As a final note, I cannot prove that the CSILOCATOR field corresponds to the clustered index, but it certainly seems to serve the function of a uniqueifier that would be needed for said clustered index.
Running up the score
I need to find a relatively efficient way to advance the CSILOCATOR because I need to do it over 2 billion times, if my theory is correct about the maximum allowed value. Both updating all of the rows in a delta rowgroup and deleting and reinserting advance the CSILOCATOR. I expected that small batch sizes would work best, and they did. For my table’s schema, the sweet spot for updates is about 275 rows and the sweet spot for delete/inserts is about 550 rows. Delete/inserts appeared to be faster than updates for the purpose of constantly reloading the same rows over and over.
Strategies that use multiple CPU cores are possible, but I wanted to do other work on this PC and didn’t want to listen to a loud fan all day. Here’s what the final testing code looked like:
DROP TABLE IF EXISTS dbo.delta_store_test; CREATE TABLE dbo.delta_store_test ( ID TINYINT NOT NULL, INDEX CCI CLUSTERED COLUMNSTORE ); DROP TABLE IF EXISTS dbo.LOG_TABLE; CREATE TABLE dbo.LOG_TABLE ( log_time DATETIME, loop_count INT, PRIMARY KEY (log_time) ); GO DROP TABLE IF EXISTS dbo.delta_store_source; CREATE TABLE dbo.delta_store_source ( ID TINYINT NOT NULL ); INSERT INTO dbo.delta_store_source SELECT TOP (550) 1 FROM master..spt_values t1 OPTION (MAXDOP 1); GO CREATE OR ALTER PROCEDURE #p AS BEGIN SET NOCOUNT ON; DECLARE @loops INT = 0; WHILE @loops <= 8000000 BEGIN DELETE FROM dbo.delta_store_test INSERT INTO dbo.delta_store_test SELECT 1 FROM dbo.delta_store_source WITH (TABLOCK); SET @loops = @loops + 1; IF @loops % 10000 = 0 BEGIN INSERT INTO dbo.LOG_TABLE VALUES (GETDATE(), @loops); END; END; END; GO EXEC #p;
If you’re wondering about the temporary stored procedure creation, it’s a habit that I’ve gotten into whenever I write a T-SQL while loop. While not applicable here, very fast loops can incur ASYNC_NETWORK_IO overhead due to the passing of DONE tokens to the client.
Winning the game
After about seven hours the code reaches its glorious end:
Msg 666, Level 16, State 2, Procedure #p, Line 11 [Batch Start Line 26]
The maximum system-generated unique value for a duplicate group was exceeded for index with partition ID 72057596406595584. Dropping and re-creating the index may resolve this; otherwise, use another clustering key.
I loaded a few more rows into the table until I was unable to insert even one row. Using DBCC PAGE and friends again, we can see that the CSILOCATOR has a very large value of 2147483646.
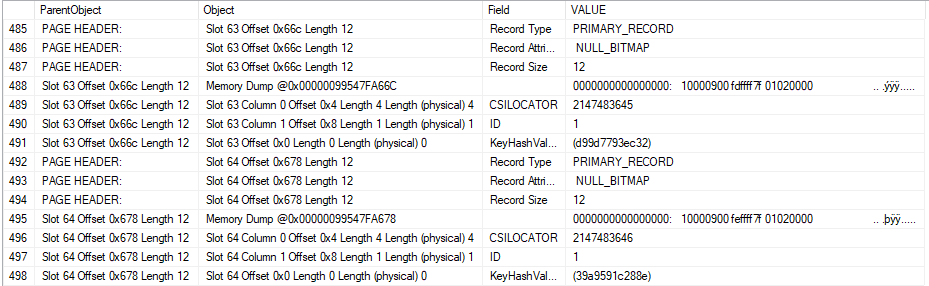
Issuing a REBUILD does resolve the issue because it wipes away our sins, as REBUILDs often do. Naturally using another clustering key is not an option.
Joe: 1
Microsoft: 0
The cost of playing
My desktop computer has an intel core i5-4670 processor. Intel claims a TDP of 84 watts. Using CPUID HWMonitor, it looks like my CPU uses about 15 W of additional power when running the workload. It’s a single core workload, so I feel that 15 W is reasonable. 15 watts is 0.015 kW, and when used over 7 hours it translates to 0.105 kWh. My last electric bill has a rate of $0.11663 per kWh, so the total cost of this test comes out to about 1.2 cents. I will be sending Erik an invoice.
Final thoughts
It is possible to hit error 666 when maliciously loading data into a columnstore index. It requires loading over 2 billion rows into the same delta rowgroup, so it’s difficult to think of a production scenario that would lead to this outcome. For those of you with eccentric workloads that give cause for concern, you can roughly check if you are running of IDs by running a query similar to the following for each columnstore table:
SELECT 2147483647 - 1 - MAX(CAST(SUBSTRING(%%physloc%%, 5, 4) AS INT)) REMAINING_CSILOCATORS FROM dbo.delta_store_test;
Thanks for reading!
One thought on “Breaking Columnstore Delta Rowgroups”
Comments are closed.