Insert Card
I’d like to start this post off by thanking my co-blogger Joe Obbish for being lazy and not blogging about this when he first ran into it three years ago.
Now that we’re through with pleasantries, let’s talk turkey.
Over in this post, by Arvind Shyamsundar, which I’m sure Microsoft doesn’t consider official documentation since it lacks a GUID in the URL, there’s a list of… things about parallel inserts.
- Just as it is with SQL Server 2016, in order to utilize the parallel insert in Azure SQL DB, do ensure that your compatibility level is set to 130. In addition, it is recommended to use a suitable SKU from the Premium service tier to ensure that the I/O and CPU requirements of parallel insert are satisfied.
- The usage of any scalar UDFs in the SELECT query will prevent the usage of parallelism. While usage of non-inlined UDFs are in general ‘considered harmful’ they end up actually ‘blocking’ usage of this new feature.
- Presence of triggers on the target table and / or indexed views which reference this table will prevent parallel insert.
- If the SET ROWCOUNT clause is enabled for the session, then we cannot use parallel insert.
- If the OUTPUT clause is specified in the INSERT…SELECT statement to return results to the client, then parallel plans are disabled in general, including INSERTs. If the OUTPUT…INTO clause is specified to insert into another table, then parallelism is used for the primary table, and not used for the target of the OUTPUT…INTO clause.
- Parallel INSERT is used only when inserting into a heap without any additional non-clustered indexes. It is also used when inserting into a Columnstore index.
- Watch out when IDENTITY or SEQUENCE is present!
In the actual post, some of these points are spread out a bit; I’ve editorially condensed them here. Some of them, like OUTPUT and UDFs, I’ve blogged about a bazillion times over here.
Others may come as a surprise, like well, the rest of them. Hm.
But there’s something missing from here, too!
Lonesome
Let’s create a #temp table, here.
DROP TABLE IF EXISTS
#parallel_insert;
CREATE TABLE
#parallel_insert
(
id int NOT NULL
)
Now let’s look at a parallel insert. I’m using an auxiliary Numbers table for this demo because whatever it’s my demo.
INSERT
#parallel_insert WITH (TABLOCK)
(
id
)
SELECT
n.Number
FROM dbo.Numbers AS n
JOIN dbo.Numbers AS n2
ON n2.Number = n.Number
OPTION
(
USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE')
);
The query plan does exactly what we want it to do, and stays parallel through the insert.
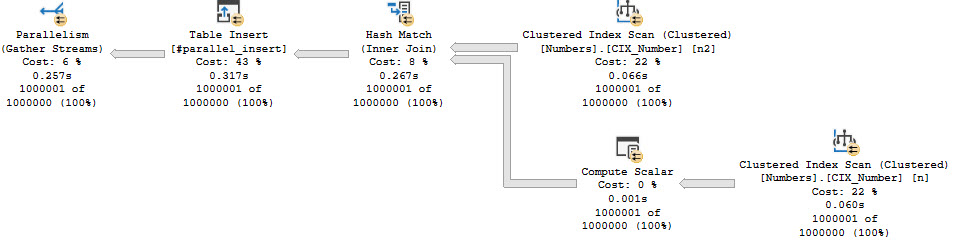
Referential
If we drop and re-create the #temp table, and then run this insert instead, that doesn’t happen:
INSERT
#parallel_insert WITH (TABLOCK)
(
id
)
SELECT
n.Number
FROM dbo.Numbers AS n
JOIN dbo.Numbers AS n2
ON n2.Number = n.Number
AND NOT EXISTS
(
SELECT
1/0
FROM #parallel_insert AS p
WHERE p.id = n.Number
)
OPTION
(
USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE')
);
Note that the not exists is against an empty table, and will not eliminate any rows. The optimizer estimates this correctly, and yet…
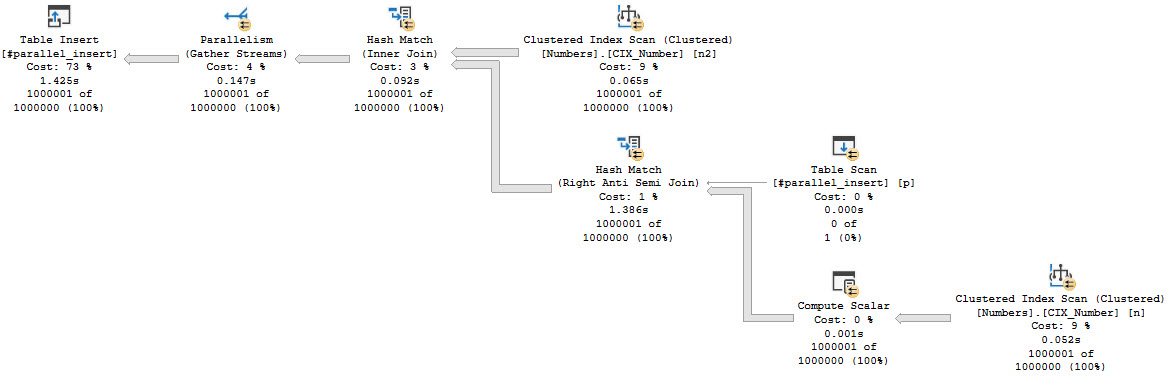
The insert is in a fully serial zone. This happens because we reference the table that we’re inserting into in the select portion of the query. It’s no longer just the target for the select to insert into.
Zone Out
If you’re tuning queries like this and hit situations where this limitation kicks in, you may need to use another #temp table to stage rows first.
I’m not complaining about this limitation. I can only imagine how difficult it would be to guarantee correct results in these situations.
I do want to point out that the fully parallel insert finishes in around 250ms, and the serial zone insert finishes in 1.4 seconds. This likely isn’t the most damning thing, but in larger examples the difference can be far more profound.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
You’re welcome!
I had to recreate the examples, and look hard at the execution plans to spot the difference.
If you are like me, you have failed to notice that “Table Insert” and “Parallelism” have swapped places.
and lost the “racing stripes” indeed.