If you don’t know about row goals I strongly recommend reading up on them here. Queries with plans similar to the following may sometimes take longer than expected to finish:
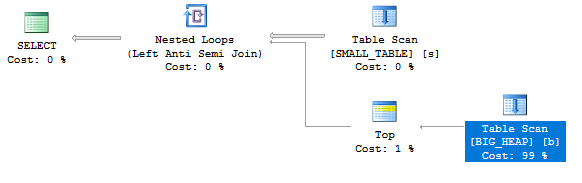
This can happen even in SQL Server 2017 with very representative statistics and perfect cardinality estimates. This post digs into why these performance degradations can happen and proposes a way to prevent them.
The Test Data
For test data I threw about a million rows into a heap. There are exactly 1000 unique values for the ID column. The table is about 1 GB in size.
DROP TABLE IF EXISTS dbo.BIG_HEAP;
CREATE TABLE dbo.BIG_HEAP (
ID BIGINT NOT NULL,
PAGE_FILLER VARCHAR(900) NOT NULL
);
-- table is about 1 GB in size
INSERT INTO dbo.BIG_HEAP WITH (TABLOCK)
SELECT
RN
, REPLICATE ('Z', 900)
FROM
(
SELECT TOP (1000000)
ROW_NUMBER()
OVER (ORDER BY (SELECT NULL)) % 1000 RN
FROM master..spt_values t1
CROSS JOIN master..spt_values t2
UNION ALL
SELECT TOP (1000) 0 RN
FROM master..spt_values t1
CROSS JOIN master..spt_values t2
) t
OPTION (MAXDOP 1);
CREATE STATISTICS S ON dbo.BIG_HEAP (ID)
WITH FULLSCAN, NORECOMPUTE;
The histogram isn’t as compact as it theoretically could be, but I would say that it represents the data very well:
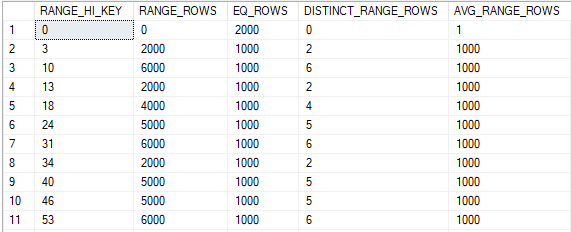
Through the histogram it’s easy to see that there are 1000 distinct values for the ID column. There are 2000 rows with an ID of 0 and 1000 rows for IDs between 1 and 999.
The data is evenly distributed on disk. This behavior isn’t guaranteed because we’re inserting into a heap, but what counts is that it remains true during the testing period. We can get the first row with any ID in the table by reading 1000 rows or fewer from the heap. Below are a few examples:
-- rows read from table = 1 SELECT TOP (1) ID FROM dbo.BIG_HEAP WHERE ID = 1; -- rows read from table = 500 SELECT TOP (1) ID FROM dbo.BIG_HEAP WHERE ID = 500; -- rows read from table = 999 SELECT TOP (1) ID FROM dbo.BIG_HEAP WHERE ID = 999; -- rows read from table = 1000 SELECT TOP (1) ID FROM dbo.BIG_HEAP WHERE ID = 0;
Approximate Formula for Scan Costing with a Row Goal
After some investigation I was able to come up with an approximate formula for the cost of a scan with a row goal applied to it. The formula has rounding and other issues but it illustrates the general behavior quite well. Here it is:
scan cost in optimizer units = 0.0031895 + LEAST(1, ROW_GOAL / CARDINALITY_ESTIMATE) * (FULL_SCAN_COST – 0.0031895)
I assume that the 0.0031895 constant is there to represent the minimum amount of work required to read a single row from a table. The ROW_GOAL parameter will just be the number of rows limited by TOP in our example queries. The CARDINALITY_ESTIMATE parameter is the number of rows estimated to be returned by SQL Server if there was no row goal. The FULL_SCAN_COST parameter is the cost in optimizer units of a single scan that reads all of the rows from the table. For BIG_HEAP this has a value of 93.7888.
SQL Server assumes that rows are evenly distributed in the table when reducing the cost of the scan. It’s certainly possible to take issue with that assumption, but this blog post does not go in that direction. In fact, I loaded the data into BIG_HEAP in such a way so that assumption would be largely true. The basic idea behind the formula is that if there are two matching rows in a table and a query needs to get just one of them, then on average the query optimizer thinks that half of the rows will need to be read from the table.
Let’s start with a few simple examples. If a row goal exceeds the total number of rows in a table then we shouldn’t expect it to change the cost of a scan. For this query:
SELECT TOP (7654321) ID FROM dbo.BIG_HEAP;
The formula simplifies to 0.0031895 + (1) * (93.7888 - 0.0031895) = 93.7888 units which is exactly the cost of the scan.
Consider a query that selects the first row without any filtering:
SELECT TOP (1) ID FROM dbo.BIG_HEAP;
The ROW_GOAL is 1 and the CARDINALITY_ESTIMATE is the number of rows in the table, 1001000. The formula gives a cost of 0.0031895 + (1 / 1001000) * (93.7888 - 0.0031895) = 0.00328319191 units which is fairly close to the actual cost of 0.0032831 units.
The formula also works for the classic SELECT TOP (0) query. The query below does not contain a scan of the heap so it could be said that the cost of the scan is 0 units.
SELECT TOP (0) ID FROM dbo.BIG_HEAP;
For a less trivial example consider the following query:
SELECT TOP (3) ID FROM dbo.BIG_HEAP WHERE ID = 1;
The ROW_GOAL is 3 and the CARDINALITY_ESTIMATE is 1000. The formula gives a cost of 0.0031895 + (3 / 1000) * (93.7888 - 0.0031895) = 0.2845463315 units. The scan cost reported by SQL Server is 0.284546 units.
Consider the following query:
SELECT TOP (1) ID FROM dbo.BIG_HEAP WHERE ID = 0;
The ROW_GOAL is 1 and the CARDINALITY_ESTIMATE is 2000. The formula gives a cost of 0.0031895 + (1 / 2000) * (93.7888 - 0.0031895) = 0.05008230525 units. The scan cost reported by SQL Server is 0.0500822 units.
An estimate based on density gives what you might expect. Consider the following query:
DECLARE @var BIGINT = 1; SELECT TOP (1) ID FROM dbo.BIG_HEAP WHERE ID = @var OPTION (MAXDOP 1);
Here the cardinality estimate will be 1001 rows. The formula gives a cost of 0.0031895 + (1 / 1001) * (93.7888 - 0.0031895) = 0.09688141858 units. The scan cost reported by SQL Server is 0.0968814 units.
Approximate Formula for Join Scan Costing with a Row Goal
The truly interesting part is how the scan cost changes due to a row goal when it’s on the inner side of a nested loop join. To model the cost we need to make a few changes to the above formula. First we need a way to approximate the cost of each successive scan. Let’s create a small, single column table:
CREATE TABLE dbo.SMALL_TABLE ( ID BIGINT NOT NULL ); CREATE STATISTICS S ON dbo.SMALL_TABLE (ID);
For cross joins, the cost increases at a linear rate of 46.382 optimizer units per execution of the scan. It’s not clear to me where this number comes from. I assume SQL Server discounts each scan after the first because some of the data will be in the buffer cache. I tested this by throwing a few rows into SMALL_TABLE and getting an estimated plan for the following query:
SELECT * FROM dbo.SMALL_TABLE s CROSS JOIN dbo.BIG_HEAP b OPTION (NO_PERFORMANCE_SPOOL, FORCE ORDER);
With 1 row the cost was 93.7888 units, with 2 rows the cost was 140.17 units, with 3 rows the cost was 186.552 units, and so on. We can use the formula from before to try to approximate the cost. The first scan has a cost according to the following (same as before):
0.0031895 + LEAST(1, ROW_GOAL / CARDINALITY_ESTIMATE) * (FULL_SCAN_COST – 0.0031895)
Each successive scan has a cost according to the following:
0.0031895 + LEAST(1, ROW_GOAL / CARDINALITY_ESTIMATE) * (REDUCED_FULL_SCAN_COST – 0.0031895)
This isn’t as accurate as it is for a single scan without a join. There’s a missing piece that I wasn’t able to find. However, it works well enough to later illustrate the problem with costing.
Let’s reset SMALL_TABLE and insert five rows:
TRUNCATE TABLE dbo.SMALL_TABLE; INSERT INTO dbo.SMALL_TABLE VALUES (500); INSERT INTO dbo.SMALL_TABLE VALUES (501); INSERT INTO dbo.SMALL_TABLE VALUES (502); INSERT INTO dbo.SMALL_TABLE VALUES (503); INSERT INTO dbo.SMALL_TABLE VALUES (504); UPDATE STATISTICS SMALL_TABLE S WITH FULLSCAN;
Here is the query that we’ll be testing with for the next few tests:
SELECT * FROM dbo.SMALL_TABLE s WHERE NOT EXISTS ( SELECT 1 FROM dbo.BIG_HEAP b WHERE s.ID = b.ID );
The plan has a final cardinality estimate of a single row and looks like this:
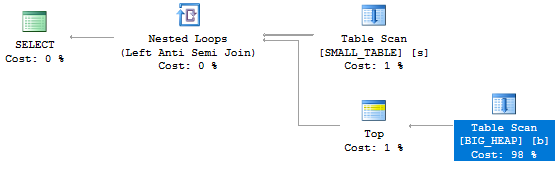
Using the previous formulas we could expect the cost of the scan to be 0.0031895 + (1 / 1000) * (93.7888 - 0.0031895) + 4 * (0.0031895 + (1 / 1000) * (46.382 - 0.0031895)) = 0.2952483525. The actual cost is 0.294842 units so it’s kind of close.
If we change one of the values to 0 we should expect a slight reduction in cost because SQL Server might think that it needs to scan fewer rows to find a row with an ID of 0.
TRUNCATE TABLE dbo.SMALL_TABLE; INSERT INTO dbo.SMALL_TABLE VALUES (0); INSERT INTO dbo.SMALL_TABLE VALUES (501); INSERT INTO dbo.SMALL_TABLE VALUES (502); INSERT INTO dbo.SMALL_TABLE VALUES (503); INSERT INTO dbo.SMALL_TABLE VALUES (504); UPDATE STATISTICS SMALL_TABLE S WITH FULLSCAN;
This does not happen. The cost remains the same as before: 0.294842 units. This is because the scan is costed according to density instead of by looking at the histogram of the outer table. The following query with a local variable repeated five times also has a cost of 0.294842 optimizer units:
DECLARE @var BIGINT = 1; SELECT * FROM ( VALUES (@var), (@var), (@var), (@var), (@var) ) s (ID) WHERE NOT EXISTS ( SELECT 1 FROM dbo.BIG_HEAP b WHERE s.ID = b.ID ) OPTION (NO_PERFORMANCE_SPOOL);
The problem with using density instead of looking at the data in the outer table is mostly apparent when the outer table contains rows without a match in the inner table. Consider the following data:
TRUNCATE TABLE dbo.SMALL_TABLE; INSERT INTO dbo.SMALL_TABLE VALUES (-1); INSERT INTO dbo.SMALL_TABLE VALUES (-2); INSERT INTO dbo.SMALL_TABLE VALUES (-3); INSERT INTO dbo.SMALL_TABLE VALUES (-4); INSERT INTO dbo.SMALL_TABLE VALUES (-5); UPDATE STATISTICS SMALL_TABLE S WITH FULLSCAN;
The query has a final cardinality estimate of five rows which is different than before. However, it still costs the scan as 0.294842 units. This is a problem. We know that SQL Server will need to read the entire table for each row that is returned to the client. For this query 5005000 rows are read from the heap.
The Request
The cost reduction for the row goal feels too aggressive with an anti join. If even a single row is output from the join that means that all of the rows were scanned from the table for that row. Is that really better than a hash join? The query optimizer is already doing the work of estimating how many rows will be output from the join. Even using the density of matched rows and assuming full scans for unmatched rows may be a significant improvement over the current model of always using density. This would also be more consistent with the costing of individual scans.
The Good
The optimizer is using density to calculate the cost of the scan, so it’s reasonable to think that we’ll get an efficient plan if SMALL_TABLE contains rows that mostly exist in BIG_HEAP. For integers between 1 and 1000 only one row will be returned to the client with an ID of 1000.
TRUNCATE TABLE dbo.SMALL_TABLE; INSERT INTO dbo.SMALL_TABLE WITH (TABLOCK) SELECT TOP (1000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM master..spt_values t1 CROSS JOIN master..spt_values t2 UPDATE STATISTICS SMALL_TABLE S WITH FULLSCAN;
We continue to test with this query:
SELECT * FROM dbo.SMALL_TABLE s WHERE NOT EXISTS ( SELECT 1 FROM dbo.BIG_HEAP b WHERE s.ID = b.ID ) OPTION (MAXDOP 1);
This query gets a nested loop anti join with a TOP operator:
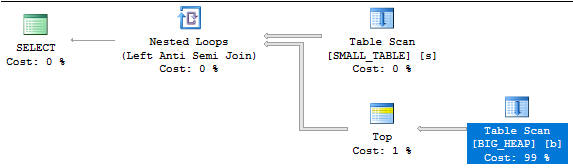
It finishes in less than a second on my machine. About 1.5 million rows in total are read from the heap which is no problem:
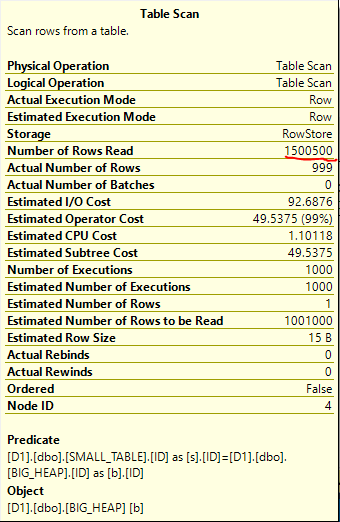
The Bad
Performance changes pretty drastically if we put rows into SMALL_TABLE that don’t have a match in BIG_HEAP. As explained earlier, each row returned to the client requires a full scan of the BIG_HEAP table. Consider the following data set for SMALL_TABLE:
TRUNCATE TABLE dbo.SMALL_TABLE; INSERT INTO dbo.SMALL_TABLE WITH (TABLOCK) SELECT TOP (1000) - 1 * ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM master..spt_values t1 CROSS JOIN master..spt_values t2 UPDATE STATISTICS SMALL_TABLE S WITH FULLSCAN;
Once again we’re using the same query:
SELECT * FROM dbo.SMALL_TABLE s WHERE NOT EXISTS ( SELECT 1 FROM dbo.BIG_HEAP b WHERE s.ID = b.ID ) OPTION (MAXDOP 1);
All 1000 rows will be returned to the client, so one billion rows will be read from the BIG_HEAP table. This is indeed what happens and the query takes around 2 minutes to complete on my machine. It’s important to note that SQL Server calculates the correct final cardinality estimate of 1000 rows:
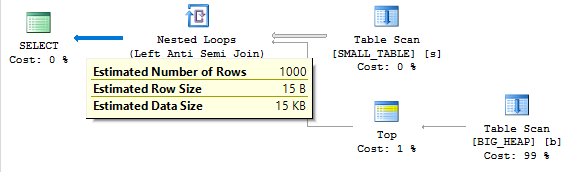
The query optimizer already does the work to figure out that there won’t be any rows returned from the BIG_HEAP table. It would be helpful if it used this knowledge to cost the scan of BIG_HEAP more accurately. The cost of the scan is 0.294842 optimizer units which obviously does not reflect reality.
If a cached scan that reads all of the rows from the table has a cost of around 46.382 units then it seems reasonable to expect that the cost of 1000 scans will be at least 46382 optimizer units, even with the row goal applied. That cost would result in a hash join or some other plan being naturally chosen by the optimizer. Forcing a hash join has an overall cost of 100.393 optimizer units but the query finishes in under one second.
Until we get better costing in this area, one workaround is to use trace flag 4138 or the DISABLE_OPTIMIZER_ROWGOAL use hint.
The Ugly
We can also see performance issues with CCIs. Below I insert 100 million rows into a CCI with roughly the same data distribution as the BIG_HEAP table. This took a few minutes on my machine.
DROP TABLE IF EXISTS dbo.CCI_ROW_GOAL; CREATE TABLE dbo.CCI_ROW_GOAL ( ID BIGINT NOT NULL, INDEX CCI CLUSTERED COLUMNSTORE ); INSERT INTO dbo.CCI_ROW_GOAL WITH (TABLOCK) SELECT TOP (100000000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) % 1000 RN FROM master..spt_values t1 CROSS JOIN master..spt_values t2 CROSS JOIN master..spt_values t3 OPTION (MAXDOP 1); CREATE STATISTICS S ON dbo.CCI_ROW_GOAL (ID) WITH FULLSCAN, NORECOMPUTE;
Once again I would say that the histogram represents the data well. You can take my word for it. Just to make sure that SMALL_TABLE has the right data we’ll reset it:
TRUNCATE TABLE dbo.SMALL_TABLE; INSERT INTO dbo.SMALL_TABLE WITH (TABLOCK) SELECT TOP (1000) - 1 * ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM master..spt_values t1 CROSS JOIN master..spt_values t2 UPDATE STATISTICS SMALL_TABLE S WITH FULLSCAN;
The query below is very familiar but we’ll start by forcing a hash join. The overall query cost is 0.126718 optimizer units and it finishes in less than a second.
SELECT * FROM dbo.SMALL_TABLE s WHERE NOT EXISTS ( SELECT 1 FROM dbo.CCI_ROW_GOAL b WHERE s.ID = b.ID ) OPTION (MAXDOP 1, HASH JOIN);
I wouldn’t describe the plan as interesting:
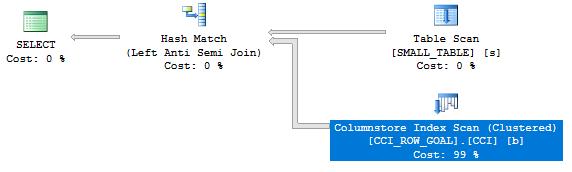
The plan changes if the HASH JOIN hint is removed:

This is a very alarming plan. It has an overall cost of 2.00464 optimizer units, but the scan is in row mode instead of batch mode. For the query to complete it will need to read about 100 billion rows from the CCI in row mode. On my machine I let it run for a little while and it looked like the query would take around 3.5 hours to complete.
Once again the optimizer expects that all 1000 rows from SMALL_TABLE will be returned to the client. The inefficient plan could be avoided with more sophisticated costing for the row goal applied to the CCI scan.
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.