Farce
The index and proc creation script for this are a bit on the long side, so I’m going to stick them in a GitHub gist to keep the post concise, since we have some other ground to cover here.
I want to lead with the statistics object that gets used for the query, which has a single equality predicate on the parameter value to search the VoteTypeId column.
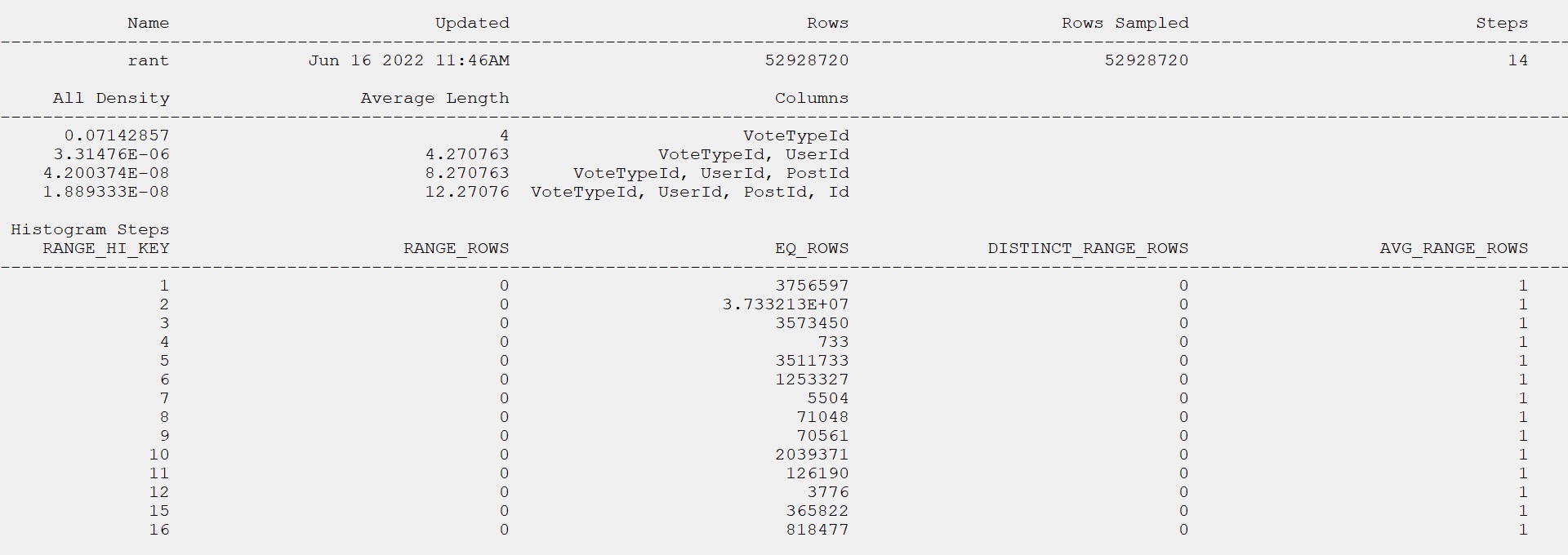
The relevant portion of the query is this:
FROM dbo.Votes AS v WHERE v.VoteTypeId = @VoteTypeId
The histogram matches the row counts from the table precisely. Thanks, full scan!
So, what’s the problem?
Autoproblematic
To my eye, there’s sufficient skewness here to present parameter sensitivity issues.
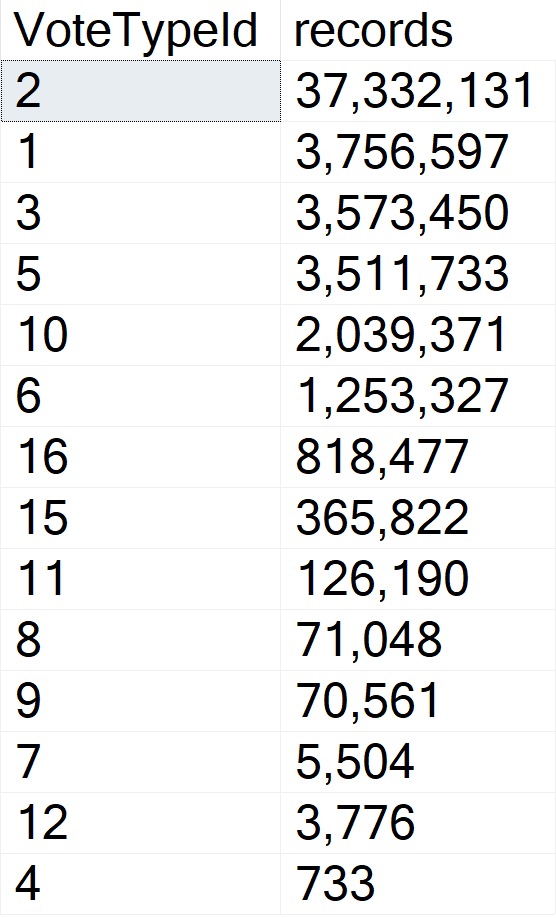
But SQL Server disagrees!

733 records vs. 37 million records seems appropriately skewed to me, but we get all of the typical parameter sensitivity symptoms.
Plansplosion
Let’s get ready to rumble, etc.
EXEC dbo.VoteSniffing
@VoteTypeId = 4;
EXEC dbo.VoteSniffing
@VoteTypeId = 2;
Here are the plans:
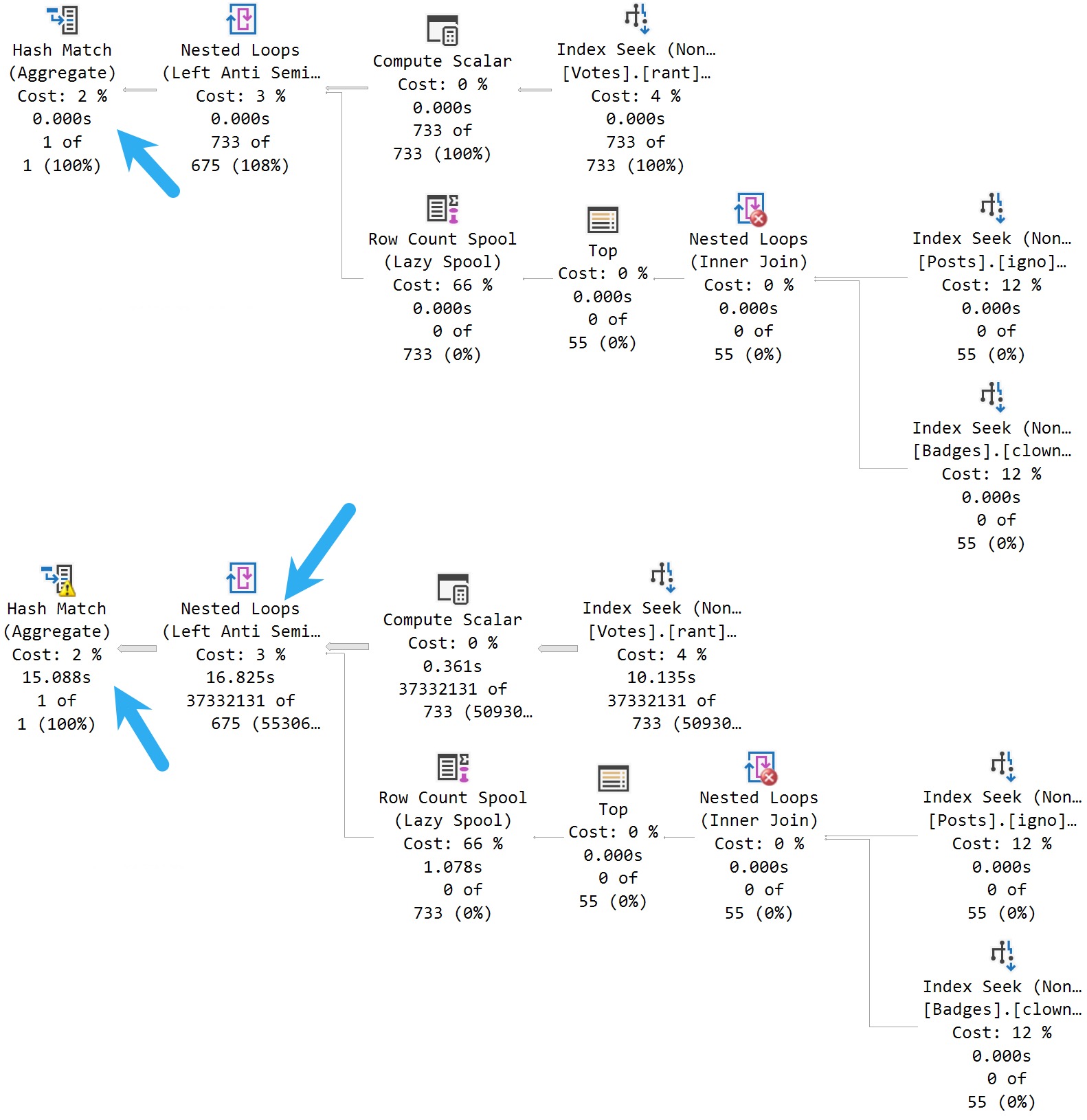
Take a moment here to admire the somewhat confusing plan timing that Batch Mode operations are presenting here: The bottom query runs for around 32 seconds.
Up to the Nested Loops join, we use ~17 seconds of wall clock time with our serial execution plan. The Hash Match operator runs for 15 seconds on its own, in Batch Mode.
Parameter sensitivity still happens in SQL Server 2022.
Reversi
If we run the procedure in reverse order, using 4 to cache the plan and then 2 to reuse, we get a similar regression:
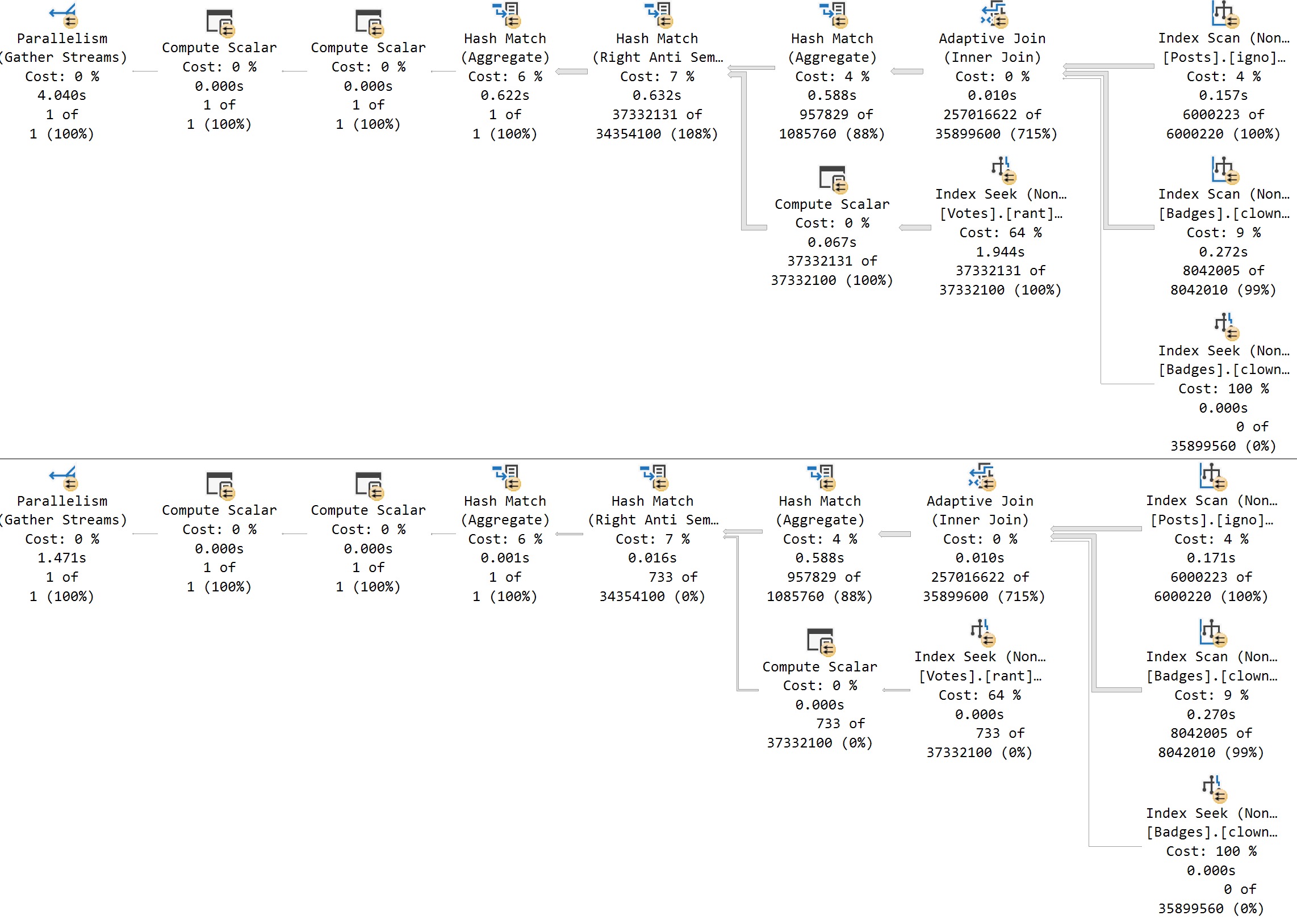
Now, okay, let’s pause for a minute here. I need to backtrack, but I don’t want to spend a ton of blogspace on it. I’m also going to put the information in a very snooty block quote.
If we re-run the procedure from the section up above to search for VoteTypeId 2 a second time, Memory Grant Feedback will fix the spill at the Hash Join, and bring the total execution time down to about 15 seconds.
That is an improvement, but… Look at the plan here. If VoteTypeId 2 uses a plan more suited to the number of rows it has to process, the overall time is around 4 seconds, with no need for a memory grant correction.
The second plan for this execution sequence, searching for VoteTypeId 4 second in order, the overall time goes from 0 seconds and 0 milliseconds to 1.4 seconds. The big plan does not make searching for infrequent values faster.
So you see, the big plan isn’t always better.
Missed Connections
Hey, look, this is the first CTP. Maybe stuff like this is still getting ironed out. Maybe this blog post will change the course of history.
I am only moderately influential in the eyes of Microsoft, though, so perhaps not.
Anyway, this seems like a situation with sufficient skew to produce the Dispatcher plan and then additional sub-plans to account for far different row counts present in the VoteTypeId column.
If this scenario (and other similar scenarios) is outside the scope of the feature, query tuning folks are still going to have a whole lot of parameter sensitivity issues to deal with.
And should that be the case, I’d like to speak to the manager.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Related Posts
- SQL Server 2022 CTP 2.1 Improvements To Parameter Sensitive Plan Optimization
- How SQL Server 2022’s Parameter Sensitive Plan Feature Can Make Query Store Confusing
- SQL Server 2022 Parameter Sensitive Plan Optimization: Does Not Care To Fix Your Local Variable Problems
- SQL Server 2022 Parameter Sensitive Plan Optimization: How PSP Can Help Some Queries With IF Branches
One thought on “SQL Server 2022 Parameter Sensitive Plan Optimization: A Missed Opportunity For PSP To Make A Query Go Faster”
Comments are closed.