Back In Time
Feeling quite old while remembering the first time I ever read this, and this note at the end:
This is the SQL language
IS DISTINCT FROMfeature —implemented in the query processor, but not yet available in the T-SQL language.
Groovy. Since at least 2011, this has been in the Query Processor, and here in 2022 we finally get the linguistic support.
The thing is, it’s pretty underwhelming, and I’m going to show you why I think so.
First, in the docs for SQL Server, all the examples use a single literal value, like so:
SELECT * FROM #SampleTempTable WHERE id IS DISTINCT FROM 17;
I went looking for other docs examples from vendors who have had the syntax around for 10+ years, and there wasn’t anything all that much more interesting.
Mostly case expressions and whatnot.
Big deal.
Alignment
First, if I try to run either of these queries, I’ll get an error after about 6 seconds.
SELECT
c = COUNT_BIG(*)
FROM dbo.Comments AS c
WHERE c.UserId IS DISTINCT FROM
(
SELECT
v.UserId
FROM dbo.Votes AS v
);
SELECT
c = COUNT_BIG(*)
FROM dbo.Comments AS c
WHERE c.UserId IS NOT DISTINCT FROM
(
SELECT
v.UserId
FROM dbo.Votes AS v
);
Why does it take 6 seconds to get an error? Because a few parts of the query plan have to do some work, and then finally:
Msg 512, Level 16, State 1, Line 1 Subquery returned more than 1 value. This is not permitted when the subquery follows =, !=, <, <= , >, >= or when the subquery is used as an expression.
Sort of like how sometimes you try to SUM a column and after a while you get an error about arithmetic overflow.
This is a bit annoying, because that means we need a way to return a single value to evaluate.
So Yeah…
We can’t even rewrite the queries like this to get around the error, but I do want to show you the plans.
This is why we have to wait several seconds to get an error (unless you change it to IS DISTINCT FROM ALL/ANY):
SELECT
c = COUNT_BIG(*)
FROM dbo.Comments AS c
WHERE c.UserId IS DISTINCT FROM
(
SELECT
v.UserId
FROM dbo.Votes AS v
WHERE v.UserId = c.UserId
);
SELECT
c = COUNT_BIG(*)
FROM dbo.Comments AS c
WHERE c.UserId IS NOT DISTINCT FROM
(
SELECT
v.UserId
FROM dbo.Votes AS v
WHERE v.UserId = c.UserId
);
Adding a where clause inside the subquery doesn’t help.
But these query plans are total motherchucking disasters, anyway. We’ll get into indexing later, but right now they both have the same shape and operators, though slightly different semantics to deal with is/is not distinct.

Both plans run single threaded, and using Nested Loops as the physical join type, which stinks because we’re putting together two pretty big tables.
Not to mention that Eager Index Spool. What a filth.
Adding Indexes
We need these indexes to make things go any faster. Before we do anything else, let’s create these so we’re not just sitting around thumb-twiddling.
CREATE INDEX
c
ON dbo.Comments
(UserId)
WITH
(
SORT_IN_TEMPDB = ON,
DATA_COMPRESSION = PAGE
);
CREATE INDEX
v
ON dbo.Votes
(UserId)
WITH
(
SORT_IN_TEMPDB = ON,
DATA_COMPRESSION = PAGE
);
Thinking About It
Okay, so writing the query like we did up there isn’t going to get us anything. Perhaps my expectations are a bit too exotic.
Let’s try something a bit more austere:
SELECT
c = COUNT_BIG(*)
FROM dbo.Comments AS c
JOIN dbo.Votes AS v
ON c.UserId IS DISTINCT FROM v.UserId;
SELECT
c = COUNT_BIG(*)
FROM dbo.Comments AS c
JOIN dbo.Votes AS v
ON c.UserId IS NOT DISTINCT FROM v.UserId;
The first thing to be aware of here is that the IS DISTINCT FROM is an inequality predicate, so you’re stuck with Nested Loops as the physical join type:

I ran out of care-juice waiting for this to finish, so all you’re getting is an estimated plan. The lack of an equality predicate here means you don’t have Hash or Merge join as an option.
Following up on bad ideas, the IS NOT DISTINCT FROM is an equality predicate, but the plan chosen is a serial Merge Join variety, which drags on 14 seconds too long:
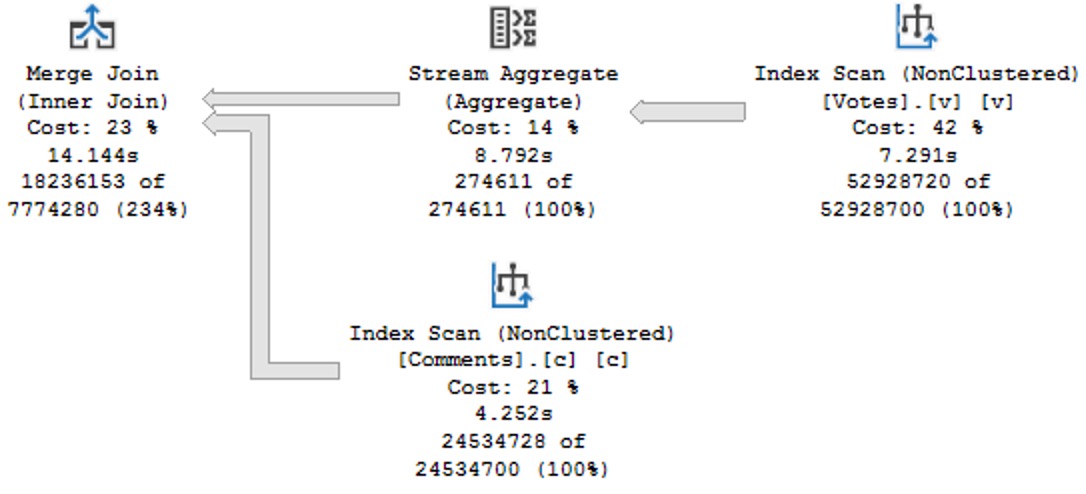
Drop An Index
If we simulate not having any useful indexes on one table or the other by hinting the clustered index, the performance outlook does not improve.
SELECT
c = COUNT_BIG(*)
FROM dbo.Comments AS c WITH(INDEX = 1)
JOIN dbo.Votes AS v
ON c.UserId IS NOT DISTINCT FROM v.UserId;
SELECT
c = COUNT_BIG(*)
FROM dbo.Comments AS c
JOIN dbo.Votes AS v WITH (INDEX = 1)
ON c.UserId IS NOT DISTINCT FROM v.UserId;
No useful parts of the first query happen in Batch Mode, but the second query is rescued by two hash aggregates happening in batch mode.
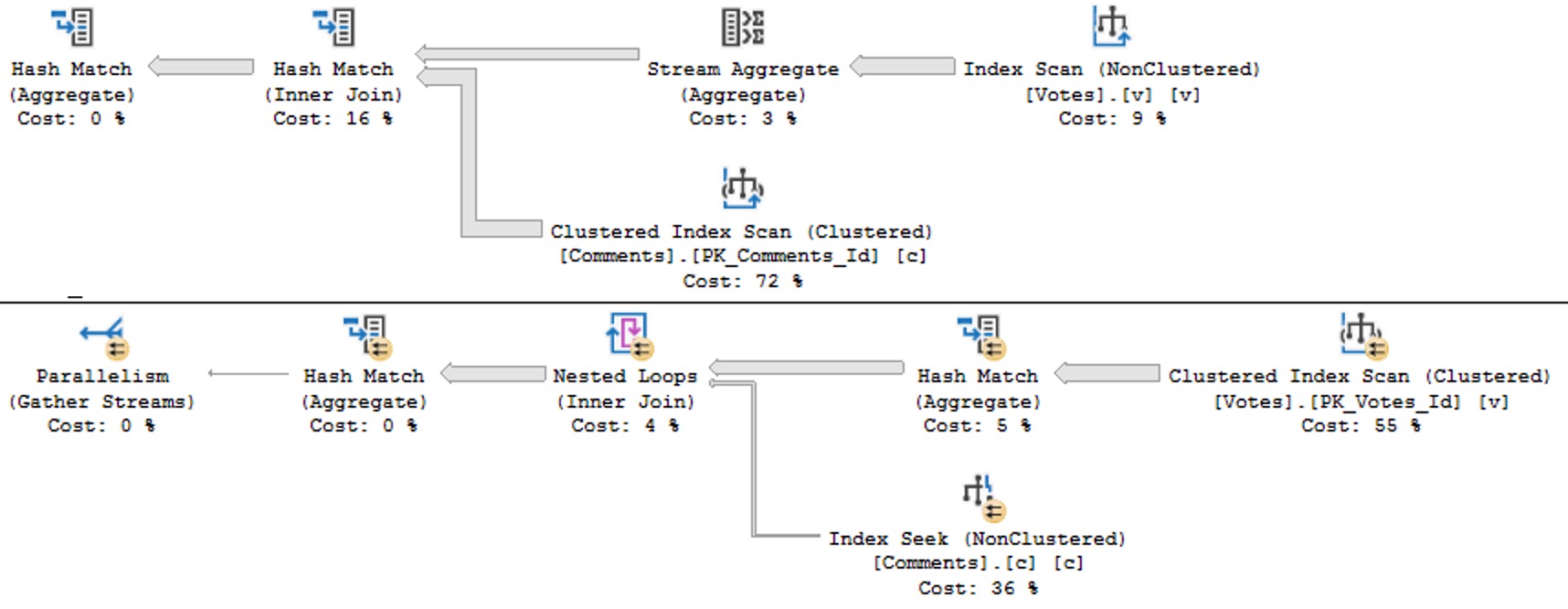
An odd point to make on a blog focused on SQL Server performance tuning is that sometimes not having a useful index gets you a better plan.
Anyway, I’m going back to my vacation.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
I think the key is that all IS DISTINCT FROM is, is shorthand for the following (copied from the documentation):
A IS DISTINCT FROM B will decode to: ((A B OR A IS NULL OR B IS NULL) AND NOT (A IS NULL AND B IS NULL))
A IS NOT DISTINCT FROM B will decode to: (NOT (A B OR A IS NULL OR B IS NULL) OR (A IS NULL AND B IS NULL))
Which is never going to perform well. IS DISTINCT FROM is just easier to write 😀
I’ve seen queries like this, so all I was looking to use the new predicate for was to make these queries simpler to read 😀
But it won’t be a performance boost or anything.
Yeah, it’s just really unfortunate performance-wise, even if it’s easier to write.
That’s really messed up, especially as I usually write it using the `EXISTS INTERSECT` syntax like Paul, which compiles right down to the IS operator in the query plan.
it’s funny you can’t do `WHERE c.UserId IS NOT DISTINCT FROM ANY (SELECT v.UserId…`
Yeah, I’m not too excited about this one. Perhaps there’s something I’m missing, though.