Stuffy Bear
The first time I heard the term “common subexpression spool” my brain went numb for a week.
It’s not a particularly mellifluous phrase, but it is helpful to understand what it is.
One easy way to think about it is a temporary cache for the result of a query, like a temp table inside your execution plan:
SELECT
*
INTO #a_temporary_table
FROM dbo.a_really_complicated_query AS a
WHERE a.thing = 'stuff';
If you were to do this, and then use that temp table to feed other queries later on, you’d be doing nearly the same thing.
Let’s look at some common-ish examples of when you might see one.
Modifications
This is the most common one, and you’ll see it in “wide” modification query plans. Or as they’re sometimes called “per index” plans.
This screenshot is highly abridged to focus in on the part I care about.
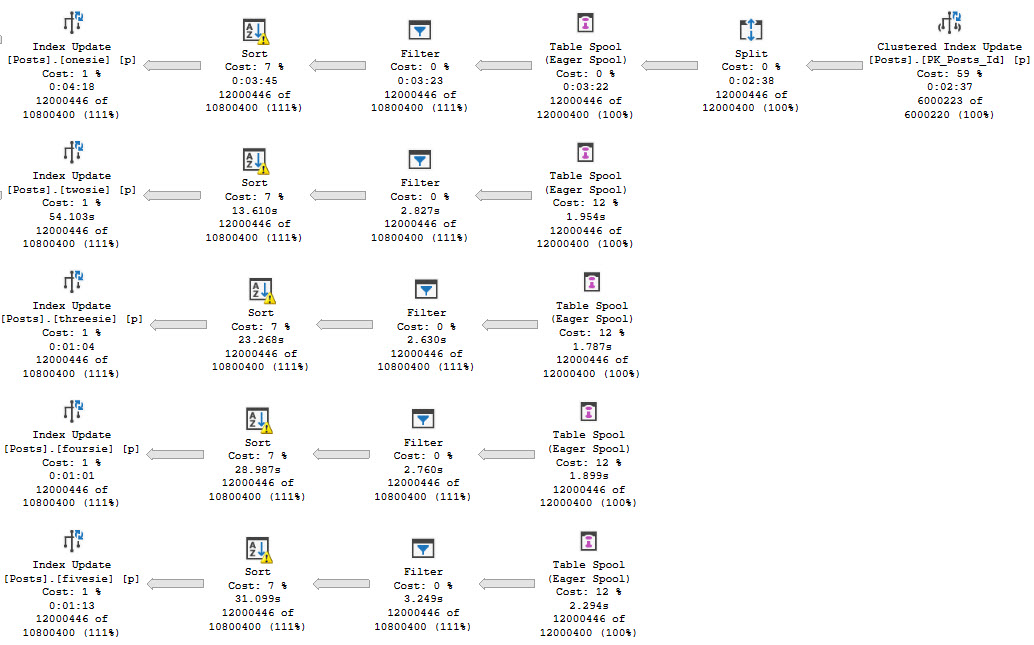
There’s a clustered index update, a Split operator, and then an Eager Table Spool. There’s also four more Eager Table Spools underneath it, but none of them have child (preceding) operators. Each one of those Spools is really the same Spool being read from over again.
Cascades
If you have foreign keys that enforce cascading actions, you’re likely to see a query plan that looks like this:
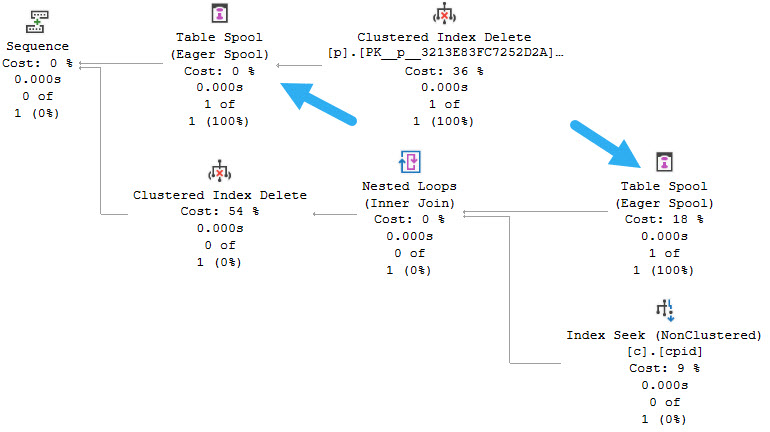
The clustered index delete feeds into an Eager Table Spool, and that Spool is read from in the child portion of the plan to track rows to be deleted from the child table.
Curses
A smiliar-ish scenario is when you use recursive CTEs.
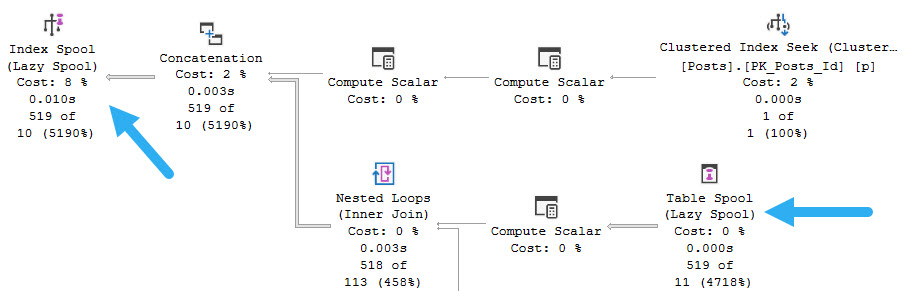
Though this time the Spool is Lazy rather than Eager, there’s something else interesting. They’re Stack Spools!
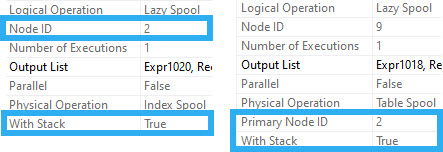
The Lazy Index Spool has a Node ID of 2, and With Stack set to True.
The Lazy Table Spool is linked to the Lazy Index Spool by its Primary Node ID.
The actual Node ID of the Lazy Table Spool is 9. It also has the With Stack property set to True.
The description of a Stack Spool from the linked post above:
Unlike ordinary common subexpression spools which eagerly load all rows into the worktable before returning any rows, a stack spool is a lazy spool which means that it begins returning rows immediately. The primary spool (the topmost operator in the plan) is fairly mundane. Like any other lazy spool, it reads each input row, inserts the row into the spool, and returns the row to the client. The secondary spool (below the nested loops join) is where all the interesting action is. Each time the nested loops join requests a row from the secondary spool, the spool reads the last row from the spool, returns it, and then deletes it to ensure that it is not returned more than once. Note that the term stack spool comes from this last in first out behavior. The primary spool pushes rows onto the stack and the secondary spool pops rows off of the stack.
Dones
There are other places where you might see this happen, like in row mode execution plans with multiple DISTINCT aggregates.
You might also see them for queries that use CUBE in them, like so:
SELECT
b.UserId,
b.Name,
COUNT_BIG(*) AS records
FROM dbo.Badges AS b
WHERE b.Date >= '20131201'
GROUP BY
b.UserId,
b.Name
WITH CUBE;
These Spools are often necessary to not get incorrect results or corrupt your database. You’d probably not enjoy that very much at all.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
One thought on “Common Query Plan Patterns: Spools From Nowhere”
Comments are closed.