Inorganic
Lots of people say these are rare — and perhaps they are becoming more so — but I still see them with some frequency. That’s not a terribly strong indictment of SQL Server, but that’s not the point of this blog or of my work.
Exchange spills are particularly interesting, and I’ve written about them a couple times:
For each query we run, we’re gonna execute the query, and then this query to look at session level wait stats.
SELECT
desws.*
FROM sys.dm_exec_session_wait_stats AS desws
WHERE desws.session_id = @@SPID
ORDER BY desws.wait_time_ms DESC;
Turns Out
The first thing to understand here is that the memory grant itself doesn’t matter. That’s why there’s no hint for it on this query, as there have been in the others.
WITH
precheck AS
(
SELECT
u.Id,
p.Id AS PostId,
p.AcceptedAnswerId,
n =
ROW_NUMBER() OVER
(
ORDER BY
u.Id
)
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON p.OwnerUserId = u.Id
WHERE u.CreationDate > '20110825'
AND u.Reputation > 100
AND p.PostTypeId = 1
)
SELECT
u.*,
p.*
FROM precheck p
JOIN dbo.Users AS u
ON p.Id = u.Id
WHERE ISNULL(p.n, u.Id) = 0
ORDER BY u.Id, u.Reputation
OPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'), MERGE JOIN);
We do need to ask for a parallel merge join, because parallel merge joins were a mistake and should not have optimizer support.
Thanks for watching.
Back Brain
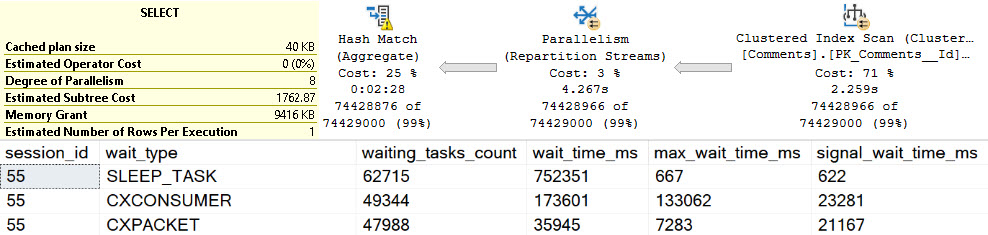
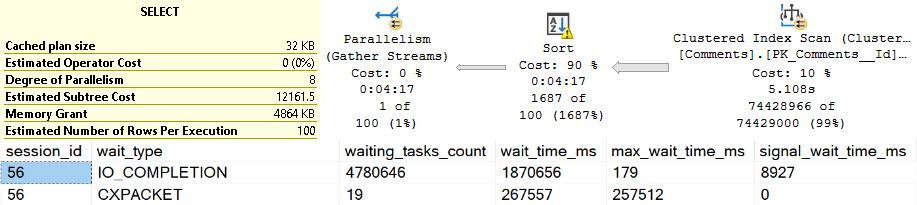
The waits here are interesting. At the top, we have perhaps high expected waits on parallelism, because the spills are encountered at parallel exchanges.
There are quite high waits on PAGEIOLATCH_EX, SLEEP_TASK, and SLEEP_BPOOL_STEAL rounding out the top five. This is quite interesting, because I’ve never explicitly thought of PAGEIOLATCH_EX waits in the context of exchange spills. Normally, I think of them when queries read pages from disk into memory for modification.
Going down the line, SLEEP_TASK is familiar from our time spent with hash spills, but SLEEP_BPOOL_STEAL is so far undocumented anywhere.
One can make some inferences based on the name about what it might be doing, but… It could also be a bit of a catch-all wait, like other waits that can be generated by spills.
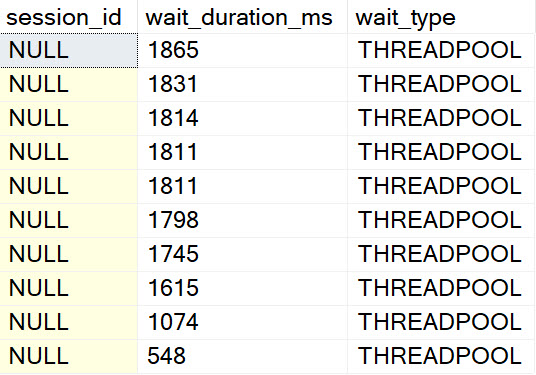
From Me
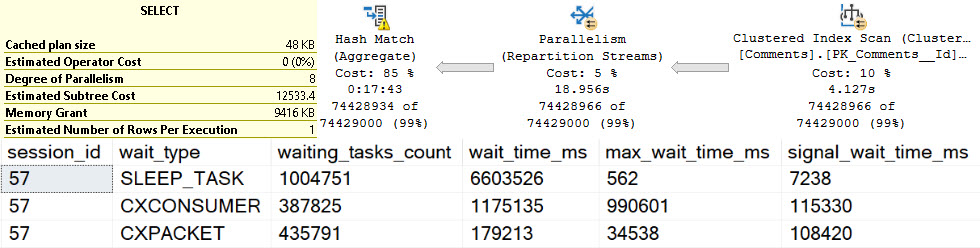
Going further, the other interesting waits encountered here look like so:
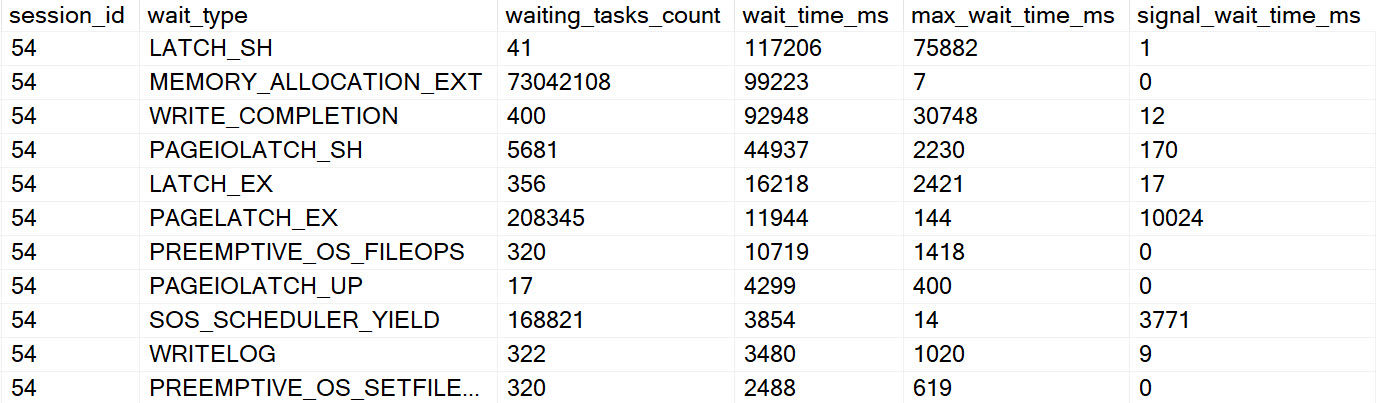
If I had a Magic Eight Ball out right now, it’d probably just go into convulsions. Perhaps SLEEP_TASK (shown one above) is another clear sign of a different kind of spill, but there’s so much else going on here it’s hard to tell for certain which waits this query generated were from the spill, and which were from other portions of the query executing regularly.
Points for hitting PREEMPTIVE waits, though.
To You
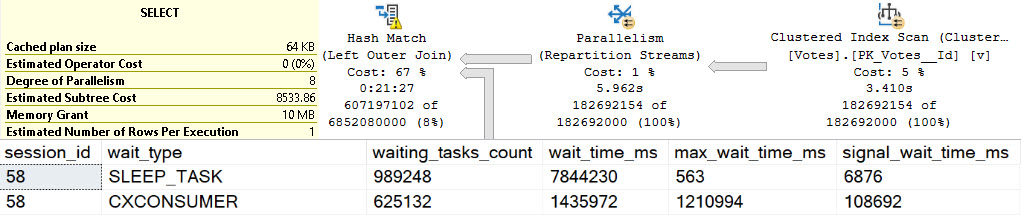
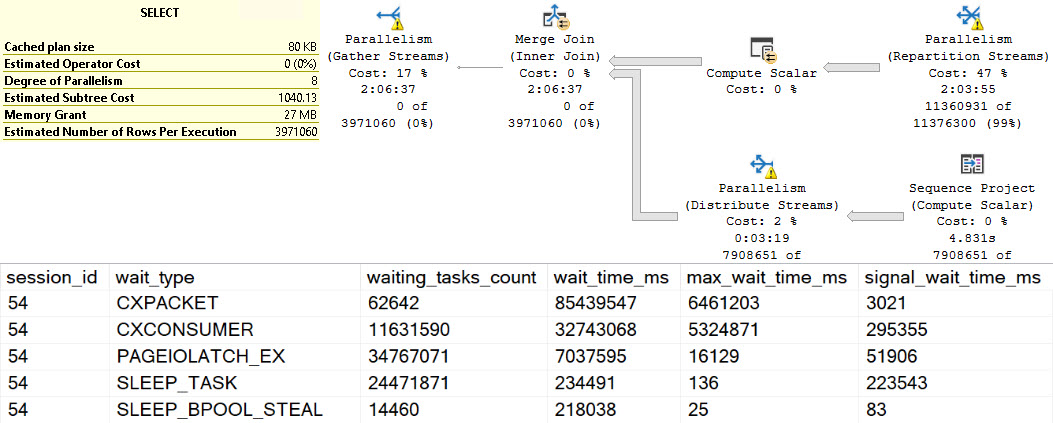
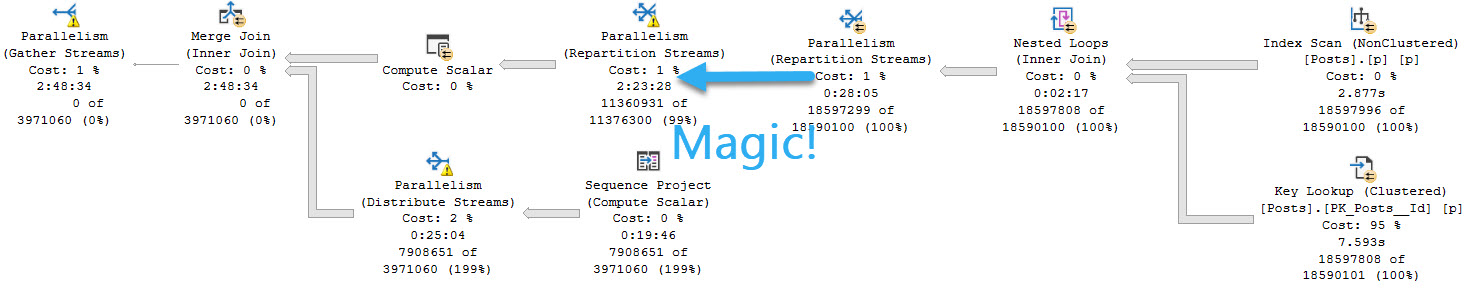
You weren’t mis-reading when you saw the query plan. This really did execute for over two hours. I tried to get another exchange spill into the mix by changing the query slightly, but all I got was a very cranky Repartition Streams.
WITH
precheck AS
(
SELECT
u.Id,
p.Id AS PostId,
p.AcceptedAnswerId,
p.Body, --New
n =
ROW_NUMBER() OVER
(
ORDER BY
u.Id
)
FROM dbo.Users AS u
JOIN dbo.Posts AS p WITH(INDEX = p)
ON p.OwnerUserId = u.Id
WHERE u.CreationDate > '20110825'
AND u.Reputation > 100
AND p.PostTypeId = 1
)
SELECT
u.*,
p.*
FROM precheck p
JOIN dbo.Users AS u
ON p.Id = u.Id
WHERE ISNULL(p.n, u.Id) = 0
ORDER BY u.Id, u.Reputation
OPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'), MERGE JOIN);
And it ran for an extra 45 or so minutes, too.
Ugly Baby
The results for this second query wait stats wise are just an amplified version of the original, of course.
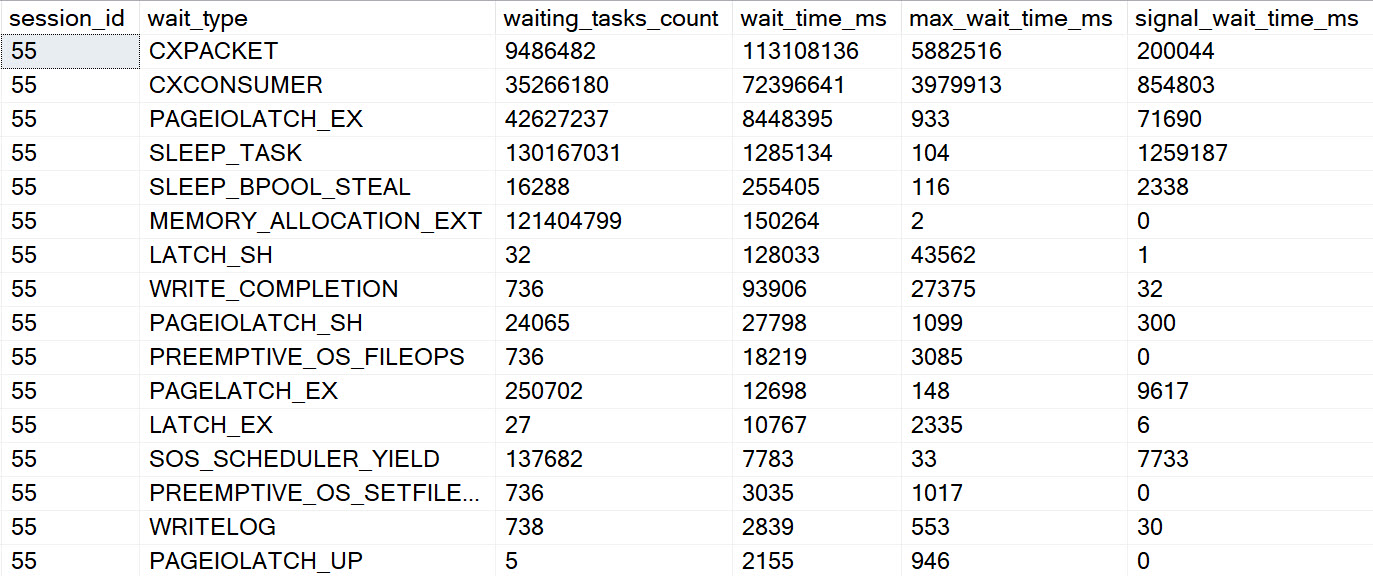
Obviously dragging the Body column around had a rather profound influence on things.
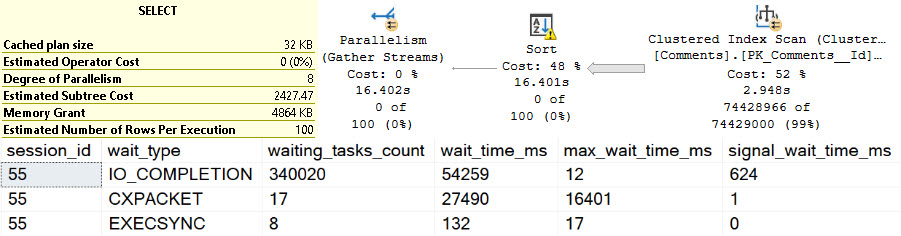
Whole And Wet
These waits are perhaps less obvious than other spills, though one could make reasonable assumptions about SLEEP_TASK waits here as well.
I’d be concerned about any query emitting high amounts of it, or any server with high amounts of it compared to uptime.
It seems unfortunate that there’s no wait directly tied to hash spills, but perhaps when we’re all living in some quantum batch mode reality in the cloud it won’t matter at all.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.