In case you missed it for some reason, check out this post of mine about local variables. Though it’s hard to imagine how you missed it, since it’s the single most important blog post ever written, even outside of SQL Server. It might even be more important than SQL Server. Time will tell.
While live streaming recently about paging queries, I thought that it might make an interesting post to see what happens when you use variables in places other than the where clause.
After several seconds of thinking about it, I decided that TOP would be a good enough place to muck around.
Unvariables
Let’s say you’ve got these two queries.
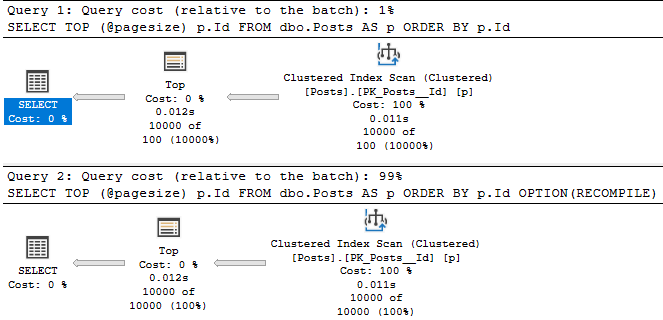
DECLARE @pagesize INT = 10000;
SELECT TOP (@pagesize) p.Id
FROM dbo.Posts AS p
ORDER BY p.Id;
GO
DECLARE @pagesize INT = 10000;
SELECT TOP (@pagesize) p.Id
FROM dbo.Posts AS p
ORDER BY p.Id
OPTION(RECOMPILE);
GO
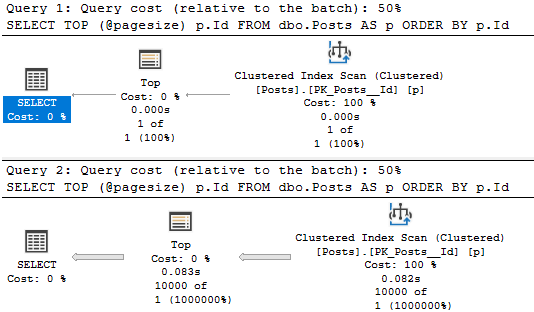
Without a RECOMPILE hint, you get a 100 row estimate for the local variable in a TOP.
You can manipulate what the optimizer thinks it’ll get with optimizer for hints:
DECLARE @pagesize INT = 10000;
SELECT TOP (@pagesize) p.Id
FROM dbo.Posts AS p
ORDER BY p.Id
OPTION(OPTIMIZE FOR(@pagesize = 1));
GO
the chump is here
And of course, when used as actual parameters, can be sniffed.
DECLARE @pagesize INT = 10000;
DECLARE @sql NVARCHAR(1000) =
N'
SELECT TOP (@pagesize) p.Id
FROM dbo.Posts AS p
ORDER BY p.Id;
'
EXEC sys.sp_executesql @sql, N'@pagesize INT', 1;
EXEC sys.sp_executesql @sql, N'@pagesize INT', 10000;
GO
boogers
Got More?
In tomorrow’s post, I’ll look at how local variables can be weird in ORDER BY. If you’ve got other ideas, feel free to leave them here.
There’s not much more to say about WHERE or JOIN, I’m looking for more creative applications ?
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Rather than just give you that one row estimate, it’ll wait until you’ve loaded data in, and then it will use table cardinality for things like joins to the table variable. Just be careful when you use them in stored procedures.
That can be a lot more helpful than what you currently get, but the guesses aren’t quite as helpful when you start using a where clause, because there still aren’t column-level statistics. You get the unknown guess for those.
How Can You Test It Out Before SQL Server 2019?
You can use #temp tables.
That’s right, regular old #temp tables.
They’ll give you nearly the same results as Table Variable Deferred Compilation in most cases, and you don’t need trace flags, hints, or or SQL Server 2019.
Heck, you might even fall in love with’em and live happily ever after.
The Fine Print
I know, some of you are out there getting all antsy-in-the-pantsy about all the SQL Jeopardy differences between temp tables and table variables.
I also realize that this may seem overly snarky, but hear me out:
Sure, there are some valid reasons to use table variables at times. But to most people, the choice about which one to use is either a coin flip or a copy/paste of what they saw someone else do in other parts of the code.
In other words, there’s not a lot of thought, and probably no adequate testing behind the choice. Sort of like me with tattoos.
Engine enhancements like this that benefit people who can’t change the code (or who refuse to change the code) are pretty good indicators of just how irresponsible developers have been with certain ✌features✌. I say this because I see it week after week after week. The numbers in Azure had to have been profound enough to get this worked on, finally.
I can’t imagine how many Microsoft support tickets have been RCA’d as someone jamming many-many rows in a table variable, with the only reasonable solution being to use a temp table instead.
I wish I could say that people learned the differences a lot faster when they experienced some pain, but time keeps proving that’s not the case. And really, it’s hardly ever the software developers who feel it with these choices: it’s the end users.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Normally, I link people to this post by Kendra and this post by Paul when I need to point them to information about what goes wrong with local variables. They’re both quite good, but I wanted something a little more specific to the situation I normally see with people locally, along with some fixes.
First, some background:
In a stored procedure (and even in ad hoc queries or within dynamic SQL, like in the examples linked above), if you declare a variable within that code block and use it as a predicate later, you will get either a fixed guess for cardinality, or a less-confidence-inspiring estimate than when the histogram is used.
The local variable effect discussed in the rest of this post produces the same behavior as the OPTIMIZE FOR UNKNOWN hint, or executing queries with sp_prepare. I have that emphasized here because I don’t want to keep qualifying it throughout the post.
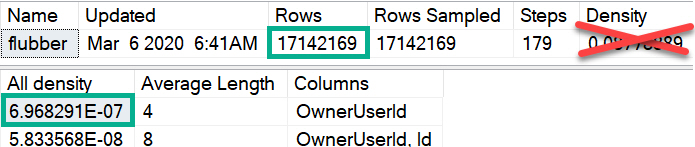
That estimate will be based on the number of rows in the table, and the “All Density” of the column multiplied together, for single equality predicates. The process for multiple predicates depends on which cardinality estimation model you’re using.
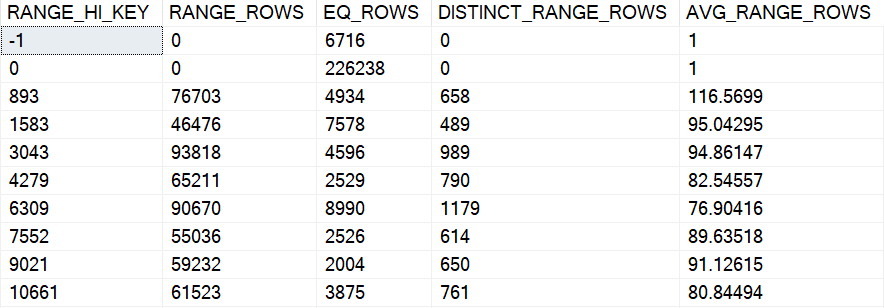
CREATE INDEX flubber
ON dbo.Posts(OwnerUserId);
DBCC SHOW_STATISTICS(Posts, flubber);
Injury
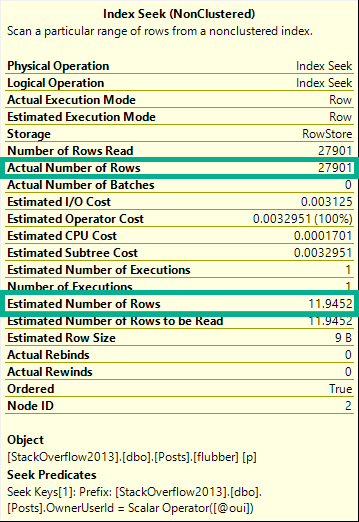
For example, this query using a single local variable with a single equality:
DECLARE @oui INT = 22656;
SELECT COUNT(*) FROM dbo.Posts AS p WHERE p.OwnerUserId = @oui;
Will get an estimate of 11.9-ish, despite 27,901 rows matching over here in reality.
Poo
Which can be replicated like so, using the numbers from the screenshot up yonder.
SELECT (6.968291E-07 * 17142169) AS [?]
Several Different Levels
You can replicate the “All Density” calculation by doing this:
SELECT (1 /
CONVERT(FLOAT, COUNT(DISTINCT p.OwnerUserId))
) AS [All Density]
FROM Posts AS p
GO
Notice I didn’t call the estimate “bad”. Even though it often is quite bad, there are some columns where the distribution of values will be close enough to this estimate for it not to matter terribly for plan shape, index choice, and overall performance.
Don’t take this as carte blanche to use this technique; quite the opposite. If you’re going to use it, it needs careful testing across a variety of inputs.
Why? Because confidence in estimates decreases as they become based on less precise information.
In these estimates we can see a couple optimizer rules in action:
Inclusion: We assume the value is there — the alternative is ghastly
Uniformity: The data will have an even distribution of unique values
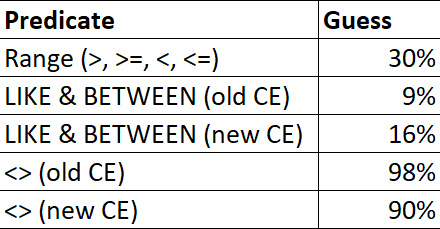
For ranges (>, >=, <, <=), LIKE, BETWEEN, and <>, there are different fixed guesses.
Destined for Lateness
These numbers may change in the future, but up through 2019 this is what my testing resulted in.
Heck, maybe this behavior will be alterable in the future :^)
No Vector, No Estimate
A lot of people (myself included) will freely interchange “estimate” and “guess” when talking about this process. To the optimizer, there’s a big difference.
An estimate represents a process where math formulas with strange fonts that I don’t understand are used to calculate cardinality.
A guess represents a breakdown in that process, where the optimizer gives up, and a fixed number is used.
Say there’s no “density vector” available for the column used in an equality predicate. Maybe you have auto-create stats turned off, or stats created asynchronously is on for the first compilation.
You get a guess, not an estimate.
ALTER DATABASE StackOverflow2013 SET AUTO_CREATE_STATISTICS OFF;
GO
DECLARE @oui INT = 22656;
SELECT COUNT(*) FROM dbo.Posts AS p WHERE p.OwnerUserId = @oui;
SELECT COUNT(*) FROM dbo.Posts AS p WHERE p.OwnerUserId = @oui OPTION(USE HINT('FORCE_LEGACY_CARDINALITY_ESTIMATION'));
GO
ALTER DATABASE StackOverflow2013 SET AUTO_CREATE_STATISTICS ON;
GO
Using the new cardinality estimator (CE), which Microsoft has quite presumptuously started calling the Default CE, I get a guess of 4,140.
Using the legacy CE, which maybe I’ll start referring to as the Best CE, to match the presumptuousness of Microsoft, I get a guess of 266,409.
Though neither one is particularly close to the reality of 27,901 rows, we can’t expect a good guess because we’re effectively poking the optimizer in the eyeball by not allowing it to create statistics, and by using a local variable in our where clause.
These things would be our fault, regardless of the default-ness, or best-ness, of the estimation model.
If you’re keen on calculating these things yourself, you can do the following:
SELECT POWER(CONVERT(FLOAT, 17142169), 0.75) AS BEST_CE;
SELECT SQRT(CONVERT(FLOAT, 17142169)) AS default_ce_blah_whatever;
SELECT COUNT_BIG(*)
FROM dbo.Posts AS p
WHERE p.CreationDate = p.CommunityOwnedDate;
SELECT COUNT_BIG(*)
FROM dbo.Posts AS p
WHERE p.CreationDate = p.CommunityOwnedDate
OPTION(USE HINT('FORCE_LEGACY_CARDINALITY_ESTIMATION'));
The so-called “default” CE thinks 1,714,220 rows will match for a column-equals-column comparison, and the “legacy” CE thinks 6.44248 rows will match, assuming that histograms are available for both of these queries.
How many actually match? 59,216.
I never said this was easy, HOWEVER!
Ahem.
The “legacy” CE estimate comes from advanced maths that only people who vape understand, while the so-called “default” CE just guesses ten percent, in true lazybones fashion. “You treat your stepmother with respect, Pantera!“, as a wise man once said.
Second, what we want to happen:
Code that uses literals, parameters, and other sniff-able forms of predicates use the statistics histogram, which typically has far more valuable information about data distribution for a column. No, they’re not always perfect, and sure, estimates can still be off if we use this, but that’s a chance I’m willing to take.
Even if they’re out of date. Maybe. Maybe not.
Look, just update those statistics.
American Histogram X
Like I mentioned before, these estimates typically have higher confidence levels because they’re often based on more precise details about the data.
If I had to rank them:
Direct histogram step hits for an equality
Intra-step hits for an equality
Direct histogram step hits for a range
Intra-step hits for a range
Inequalities (not equals to)
Joins
1000 other things
All the goofy stuff you people do to make this more difficult, like wrapping columns in functions, mismatching data types, using local variables, etc.
Of course, parameterized code does open us up to parameter sniffing issues, which I’m not addressing in this post. My only goal here is to teach people how to get out of performance jams caused by local variables giving you bad-enough estimates. Ha ha ha.
Plus, there’s a lot of negativity out there already about parameter sniffing. A lot of the time it does pretty well, and we want it to happen.
Over-Under
The main issues with the local variable/density vector estimates is that they most often don’t align well with reality, and they’re almost certainly a knee-jerk reaction to a parameter sniffing problem, or done out of ignorance to the repercussions. It would be tedious to walk through all of the potential plan quality issues that could arise from doing this, though I did record a video about one of them here.
Instead of doing all that stuff, I’d rather walk through what works and what doesn’t when it comes to fixing the problem.
But first, what doesn’t work!
Temporary Objects Don’t Usually Work
If you put the value of the local variable in a #temp table, you can fall victim to statistics caching. If you use a @table variable, you don’t get any column-level statistics on what values go in there (even with a recompile hint or trace flag 2453, you only get table cardinality).
There may be some circumstances where a #temp table can help, or can get you a better plan, but they’re probably not my first stop on the list of fixes.
The #temp table will require a uniqueness constraint to work
This becomes more and more difficult if we have multiple local variables to account for
And if they have different data types, we need multiple #temp tables, or wide tables with a column and constraint per parameter
From there, we end up with difficulties linking those values in our query. Extra joins, subqueries, etc. all have potential consequences.
Inline Table Valued Functions Don’t Work
They’re a little too inline here, and they use the density vector estimate. See this gist for a demo.
Recompile Can Work, But Only Do It For Problem Statements
It has to be a statement-level recompile, using OPTION(RECOMPILE). Putting recompile as a stored procedure creation option will not allow for parameter embedding optimizations, i.e. WITH RECOMPILE.
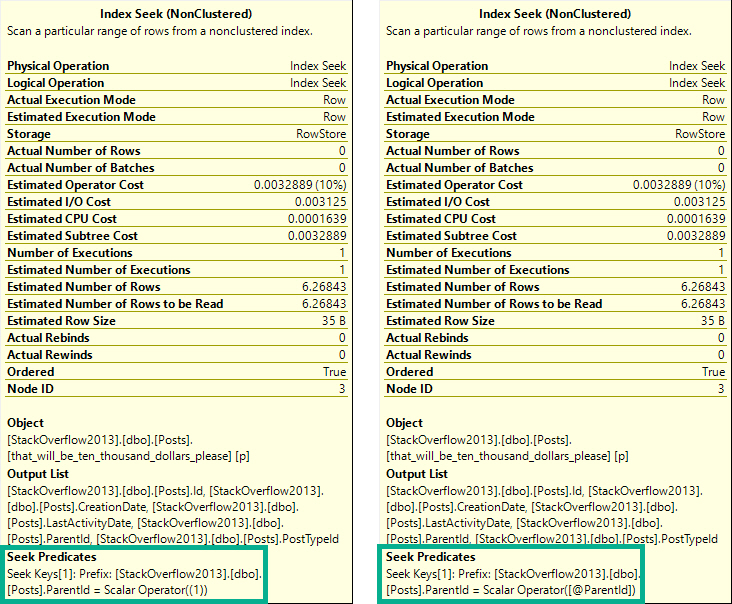
One of these things is not like the other.
The tool tip on the left is from a plan with a statement-level recompile. On the right is from a plan with a procedure-level recompile. In the statement-level recompile plan, we can see the scalar operator is a literal value. In the procedure-level recompile, we still see @ParentId passed in.
The difference is subtle, but exists. I prefer statement-level recompiles, because it’s unlikely that every statement in a procedure should or needs to be recompiled, unless it’s a monitoring proc or something else with no value to the plan cache.
Targeting specific statements is smarterer.
Erer.
A more detailed examination of this behavior is at Paul’s post, linked above.
Dynamic SQL Can Work
Depending on complexity, it may be more straight forward to use dynamic SQL as a receptacle for your variables-turned-parameters.
CREATE PROCEDURE dbo.game_time(@id INT)
AS BEGIN
DECLARE @id_fix INT;
SET @id_fix = CASE WHEN @id < 0 THEN 1 ELSE @id END;
DECLARE @sql NVARCHAR(MAX) = N'';
SET @sql += N'SELECT COUNT(*) FROM dbo.Posts AS p WHERE p.OwnerUserId = @id;';
EXEC sys.sp_executesql @sql, N'@id INT', @id_fix
END;
Separate Stored Procedures Can Work
If you need to declare variables internally and perform some queries to assign values to them, passing them on to separate stored procedures can avoid the density estimates. The stored procedure occurs in a separate context, so all it sees are the values passed in as parameters, not their origins as variables.
In other words, parameters can be sniffed; variables can’t.
CREATE PROCEDURE dbo.game_time(@id INT)
AS
BEGIN
DECLARE @id_fix INT;
SET @id_fix = CASE WHEN @id < 0 THEN 1 ELSE @id END;
EXEC dbo.some_new_proc @id_fix;
END;
Just pretend the dynamic SQL from above occupies the stored procedure dbo.some_new_proc here.
Optimizing For A Value Can Work
But choosing that value is hard. If one is feeling ambitious, one could take the local parameter value, compare it to the histogram on one’s own, then choose a value on one’s own that, one, on their own, could use to determine if a specific, common, or nearby value would be best to optimize for, using dynamic SQL that one has written on one’s own.
Ahem.
CREATE PROCEDURE dbo.game_time(@id INT)
AS BEGIN
DECLARE @id_fix INT;
SET @id_fix = CASE WHEN @id < 0 THEN 1 ELSE @id END;
DECLARE @a_really_good_choice INT;
SET @a_really_good_choice = 2147483647; --The result of some v. professional code IRL.
DECLARE @sql NVARCHAR(MAX) = N'';
SET @sql += N'SELECT COUNT(*) FROM dbo.Posts AS p WHERE p.OwnerUserId = @id OPTION(OPTIMIZE FOR(@id = [a_really_good_choice]));';
SET @sql = REPLACE(@sql, N'[a_really_good_choice]', @a_really_good_choice);
EXEC sys.sp_executesql @sql, N'@id INT', @id_fix;
END;
GO
Wrapping Up
This post aimed to give you some ways to avoid getting bad density vector estimates with local variables. If you’re getting good guesses, well, sorry you had to read all this.
When I see this pattern in client code, it’s often accompanied by comments about fixing parameter sniffing. While technically accurate, it’s more like plugging SQL Server’s nose with cotton balls and Lego heads.
Sometimes there will be several predicate filters that diminish the impact of estimates not using the histogram. Often a fairly selective predicate evaluated first is enough to make this not suck too badly. However, it’s worth learning about, and learning how to fix correctly.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
It’s been a while since SQL Server has had a real RECOMPILE problem. And if you put it up against the performance problems that you can hit with parameter sniffing, I’d have a hard time telling someone strapped for time and knowledge that it’s the worst idea for them.
Obviously, you can run into problems if you (“you” includes Entity Framework, AKA the Database Demolisher) author the kind of queries that take a very long time to compile. But as I list them out, I’m kinda shrugging.
Here are some problems you can hit with recompile. Not necessarily caused by recompile, but by not re-using plans.
Long compile times: Admittedly pretty rare, and plan guides or forced plans are likely a better option.
No plan history in the cache (only the most recent plan): Sucks if you’re looking at the plan cache. Sucks less if you have a monitoring tool or Query Store.
CPU spikes for high-frequency execution queries: Maybe time for caching some stuff, or getting away from the kind of code that executes like this (scalar functions, cursors, etc.)
But for everything in the middle: a little RECOMPILE probably won’t hurt that bad.
Thinking of the problems it can solve:
Parameter sniffing
Parameter embedding (lack of)
Local variable estimates
Catch all queries
Those are very real problems that I see on client systems pretty frequently. And yeah, sometimes there’s a good tuning option for these, like changing or adding an index, moving parts of the query around, sticking part of the query in a temp table, etc.
But all that assumes that those options are immediately available. For third party vendors who have somehow developed software that uses SQL Server for decades without running into a single best practice even by accident, it’s often harder to get those changes through.
There’s More Than One Way To Recompile
Sure, you might be able to sneak a recompile hint somewhere in the mix even if it’d make the vendor upset. You can always yoink it out later.
But you have alternatives, too.
DBCC FREEPROCCACHE: No, not the whole cache. You can single out troublesome queries to remove specific plans.
Plan Guides: An often overlooked detail of plan guides is that you can attach hints to them, including recompile.
Using a plan guide doesn’t interfere with that precious vendor IP that makes SQL Server unresponsive every 15 minutes. Or whatever. I’m not mad.
And yeah, there’s advances in SQL Server 2017 and 2019 that start to address some issues here, but they’re still imperfect.
I like’em, but you know. They’re not quite there yet.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I see this pattern quite a bit in stored procedures, where the front end accepts an integer which gets passed to a query.
That integer is used to specify some time period — days, months, whatever — and the procedure then has to search some date column for the relevant values.
Here’s a simplified example using plain ol’ queries.
Still Alive
Here are my queries. The recompile hints are there to edify people who are hip to local variable problems.
DECLARE @months_back INT = 1;
SELECT COUNT(*) AS records
FROM dbo.Posts AS p
WHERE DATEADD(MONTH, @months_back * -1, p.CreationDate) <= '20100101' --Usually GETDATE() is here
OPTION(RECOMPILE);
GO
DECLARE @months_back INT = 1;
SELECT COUNT(*) AS records
FROM dbo.Posts AS p
WHERE p.CreationDate <= DATEADD(MONTH, @months_back, '20100101') --Usually GETDATE() is here
OPTION(RECOMPILE);
GO
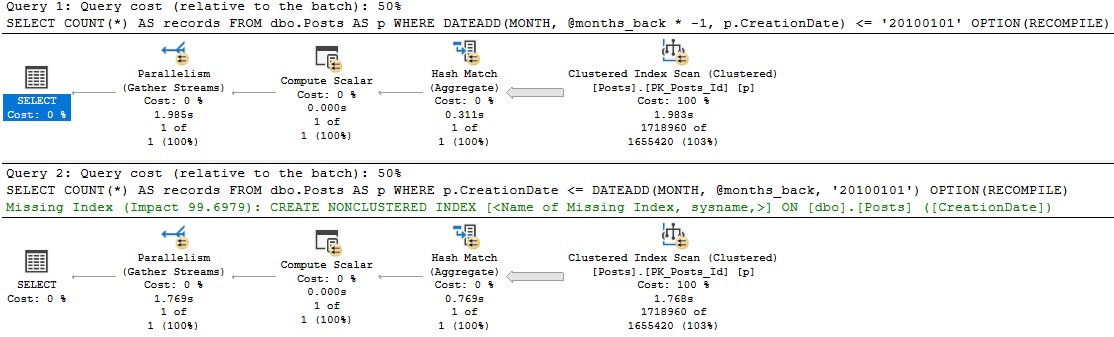
The problem with the first query is that the function is applied to the column, rather than to the variable.
If we look at the plans for these, the optimizer only thinks one of them is special enough for an index request.
please respond
Sure, there’s also a ~200ms difference between the two, which is pretty repeatable.
But that’s not the point — where things change quite a bit more is when we have a useful index. Those two queries above are just using the clustered index, which is on a column unrelated to our where clause.
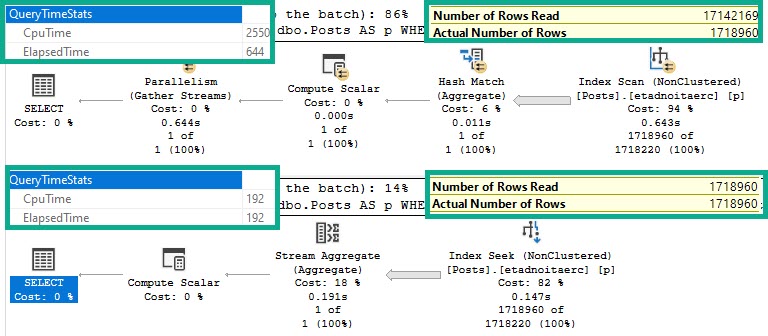
CREATE INDEX etadnoitaerc ON dbo.Posts(CreationDate);
Oops.
Side by side:
The bad query uses >10x more CPU
Still runs for >3x as long
Scans the entire index
Reads 10x more rows
Has to go parallel to remain competitive
At MAXDOP 1, it runs for just about 2.2 seconds on a single thread. Bad news.
Qual
This is one example of misplacing logic, and why it can be bad for performance.
All these demos were run on SQL Server 2019, which unfortunately didn’t save us any trouble.
In the next post, I’m going to look at another way I see people make their own doom.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Parameter sniffing gets blamed for a lot of things, and, well, sometimes it is parameter sniffing.
It’s probably not parameter sniffing if:
You use local variables
You use optimize for unknown
You’re recompiling anyway
ButWhatAbout
While working with a client recently, they were absolutely sure they had a parameter sniffing issue.
The general proof given was that as the day went on, queries got slower and slower.
The next day, they’d magically be fast again, and then the same slowdown would happen.
When we looked at the stored procedures in question, it looked like they might be right.
So I set up a test.
Pile and Recompile
We stuck a recompile hint on a stored procedure that people are always complaining about, and watched the runtime throughout the day.
Sure enough, it got slower and slower, but not because it got a bad plan. The server just got busier and busier.
6am: 2 seconds
7am: 6 seconds
8am: 15 seconds
9am: 20 seconds
10am: 30 seconds
I left out some details, and I’m sorry about that. You probably want the last 2 minutes of your life back.
Get in line.
Missing Persons
This poor server had hundreds of database totaling almost 4TB.
With 96 GB of RAM, and 4 cores, there was no good way for it to support many user requests.
When things got slow, two wait stats would tick up: PAGEIOLATCH_SH, and SOS_SCHEDULER_YIELD.
SQL Server had a hard time keeping the data people needed in memory, and it got really busy trying to make sure every query got a fair amount of CPU time.
In this case, it wasn’t parameter sniffing, it was server exhaustion.
Last Farewell
Wait stats aren’t always helpful, but they can help you with investigations.
This kind of resource contention won’t always be the issue, of course.
But when you’re investigating performance issues, it’s important to know what things look like when the server is running well, and what things look like when the’re not.
That includes
Wait stats
Query plans
Overall workload
Blocking
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.