Not Another Upgrade
When dm_db_missing_index_group_stats_query got documented, I was really happy. After all, this has been a peeve of mine for ages.
“Wow look at all these missing index requests. Where’d they come from?”
So this is neat! And it’s better than nothing, but there are some quirks.
And what’s a quirk, after all, but a twerk that no one enjoys.
Columnar
The first thing to note about this DMV is that there are two columns purporting to have sql_handles in them. No, not that sql_handle.
One of them can’t be used in the traditional way to retrieve query text. If you try to use last_statement_sql_handle, you’ll get an error.
SELECT
ddmigsq.group_handle,
ddmigsq.query_hash,
ddmigsq.query_plan_hash,
ddmigsq.avg_total_user_cost,
ddmigsq.avg_user_impact,
query_text =
SUBSTRING
(
dest.text,
(ddmigsq.last_statement_start_offset / 2) + 1,
(
(
CASE ddmigsq.last_statement_end_offset
WHEN -1
THEN DATALENGTH(dest.text)
ELSE ddmigsq.last_statement_end_offset
END
- ddmigsq.last_statement_start_offset
) / 2
) + 1
)
FROM sys.dm_db_missing_index_group_stats_query AS ddmigsq
CROSS APPLY sys.dm_exec_sql_text(ddmigsq.last_statement_sql_handle) AS dest;
Msg 12413, Level 16, State 1, Line 27
Cannot process statement SQL handle. Try querying the sys.query_store_query_text view instead.
Is Vic There?
One other “issue” with the view is that entries are evicted from it if they’re evicted from the plan cache. That means that queries with recompile hints may never produce an entry in the table.
Is this the end of the world? No, and it’s not the only index-related DMV that behaves this way: dm_db_index_usage_stats does something similar with regard to cached plans.
As a quick example, if I execute these two nearly-identical queries, the DMV only records one potential use of the index:
SELECT
COUNT_BIG(*)
FROM dbo.Posts AS p
WHERE p.OwnerUserId = 22656
AND p.Score < 0;
GO
SELECT
COUNT_BIG(*)
FROM dbo.Posts AS p
WHERE p.OwnerUserId = 22656
AND p.Score < 0
OPTION(RECOMPILE);
GO

Italic Stallion
You may have noticed that may was italicized in when talking about whether or not plans with recompile hints would end up in here.
Some of them may, if they’re part of a larger batch. Here’s an example:
SELECT
COUNT_BIG(*)
FROM dbo.Posts AS p
WHERE p.OwnerUserId = 22656
AND p.Score < 0
OPTION(RECOMPILE);
SELECT
COUNT_BIG(*)
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON p.OwnerUserId = u.Id
JOIN dbo.Comments AS c
ON c.PostId = p.Id
WHERE u.Reputation = 1
AND p.PostTypeId = 3
AND c.Score = 0;
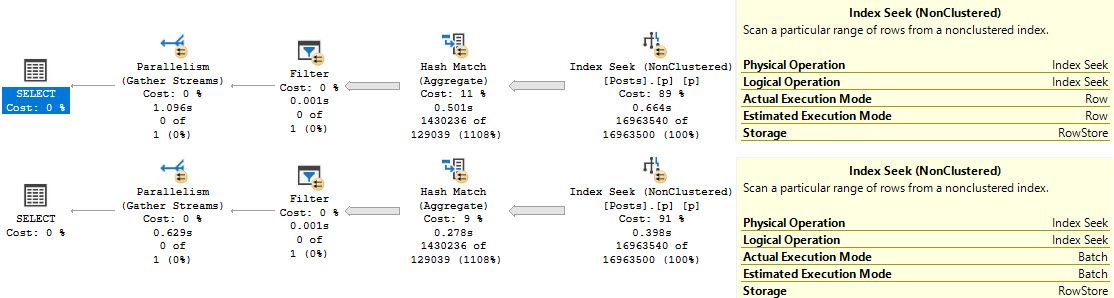
Most curiously, if I run that batch twice, the missing index request for the recompile plan shows two uses.

Multiplicity
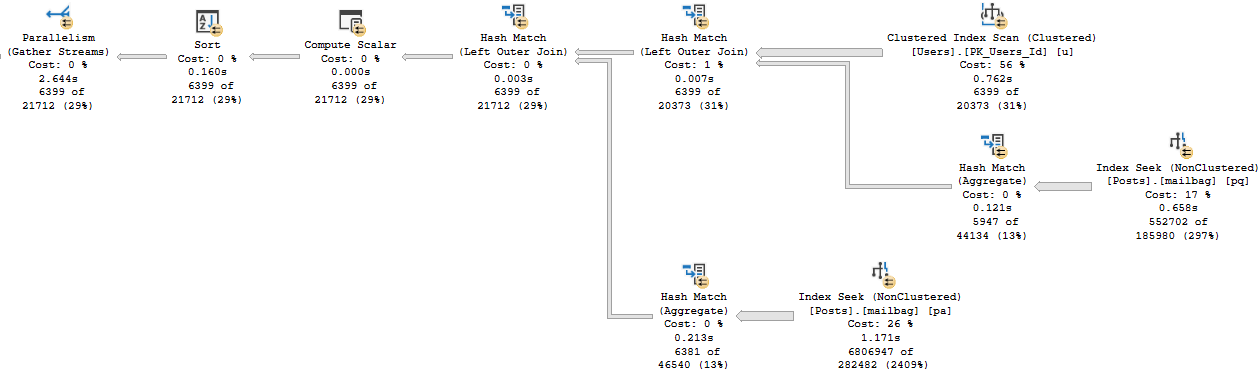
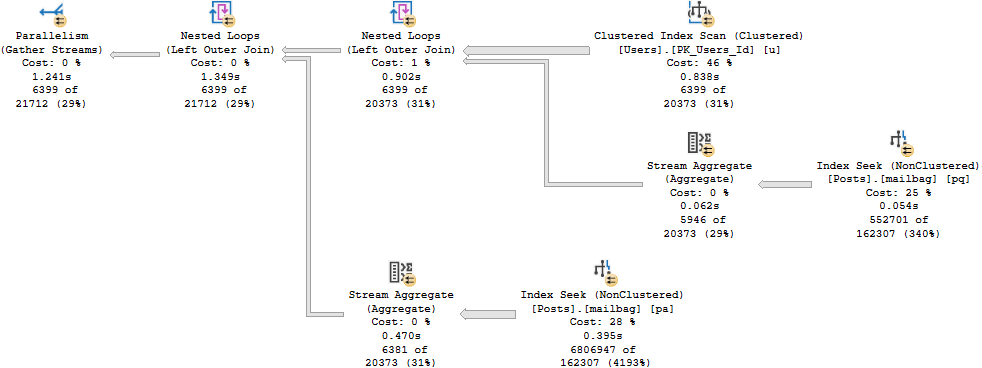
You may have also noticed something odd in the above screenshot, too. One query has produced three entries. That’s because…
The query has three missing index requests. Go ahead and click on that.

Another longstanding gripe with SSMS is that it only shows you the first missing index request in green text, and that it might not even be the “most impactful” one.
That’s the case here, just in case you were wondering. Neither the XML, nor the SSMS presentation of it, attempt to order the missing indexes by potential value.
You can use the properties of the execution plan to view all missing index requests, like I blogged about here, but you can’t script them out easily like you can for the green text request at the top of the query plan.

At least this way, it’s a whole heck of a lot easier for you to order them in a way that may be more beneficial.
EZPZ
Of course, I don’t expect you to write your own queries to handle this. If you’re the type of person who enjoys Blitzing things, you can find the new 2019 goodness in sp_BlitzIndex, and you can find all the missing index requests for a single query in sp_BlitzCache in a handy-dandy clickable column that scripts out the create statements for you.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.