We All Have It
You know those tables, right? The ones where developers went and got lazy or didn’t know any better and decided every string column was going to be gigantic.
They may have read, of course, that SQL Server’s super-smart variable length data types only consume necessary space.
It’s free real estate.
Except it isn’t, especially not when it comes to query memory grants.
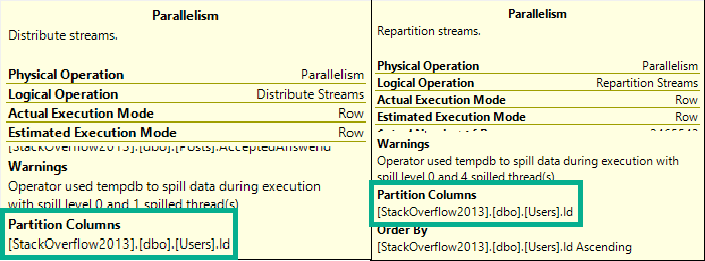
The bigger a string column’s defined byte length is, the bigger the optimizer’s memory grant for it will be.
Memory Grant Primer
In case you need some background, the short story version is:
- All queries ask for some memory for general execution needs
- Sorts, Hashes, and Optimized Nested Loops ask for additional memory grants
- Memory grants are decided based on things like number of rows, width of rows, and concurrently executing operators
- Memory grants are divided by DOP, not multiplied by DOP
- By default, any query can ask for up to 25% of max server memory for a memory grant
- Approximately 75% of max server memory is available for memory grants at one
Needless to say, memory grants are very sensitive to misestimates by the optimizer. Going over can be especially painful, because that memory will most often get pulled from the buffer pool, and queries will end up going to disk more.
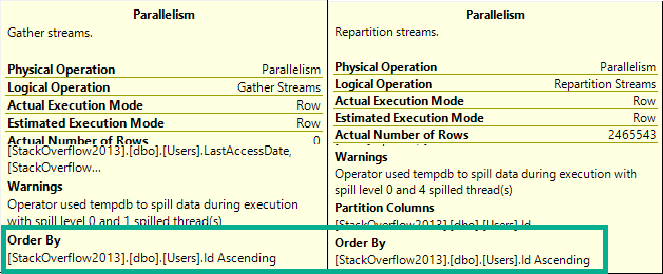
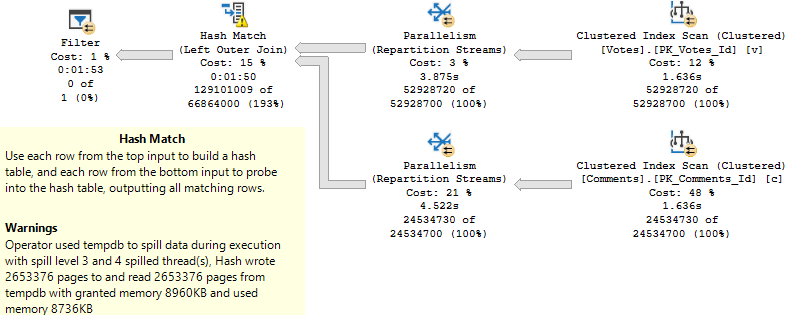
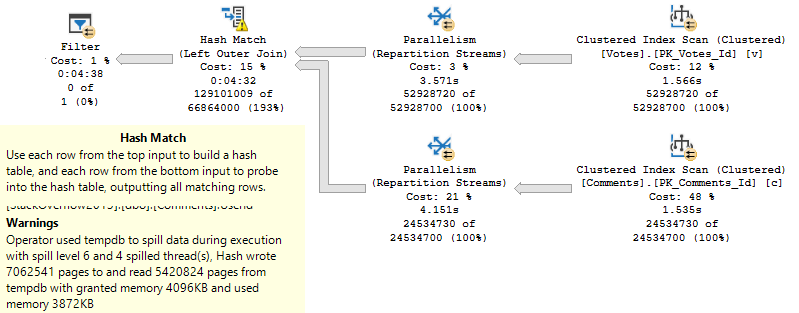
Underestimates often mean spills to disk, of course. Those are usually less painful, but can of course be a problem when they’re large enough. In particular, hash spills are worth paying extra attention to.
Memory grant feedback does supply some relief under modern query execution models. That’s a nice way of saying probably not what you have going on.
Query Noogies
Getting back to the point: It’s a real pain in the captain’s quarters to modify columns on big tables, even if it’s reducing the size.
SQL Server’s storage engine has to check page values to make sure you’re not gonna lose any data fidelity in the process. That’ a nice way of saying you’re not gonna truncate any strings.
But if you do something cute like run a MAX(LEN(StringCol) and see what you’re up against, you can use a view on top of your table to assuage SQL Server’s concerns about such things.
After all, functions are temporary. Data types are forever (usually).
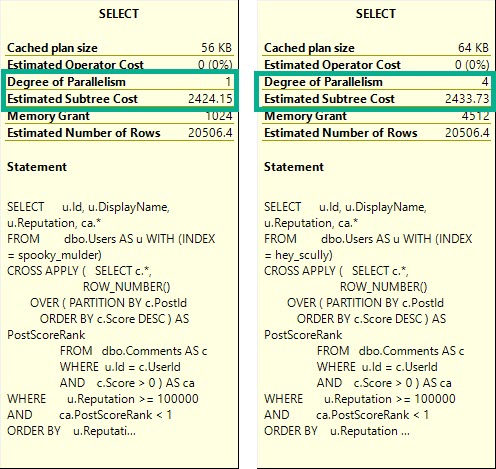
An easy way to illustrate what I mean is to look at the details of these two queries:
SELECT TOP (1000)
p.Body
FROM dbo.Posts AS p
ORDER BY p.Score DESC
OPTION(RECOMPILE);
SELECT TOP (1000)
Body =
CONVERT
(
nvarchar(100),
p.Body
)
FROM dbo.Posts AS p
ORDER BY p.Score DESC
OPTION(RECOMPILE);
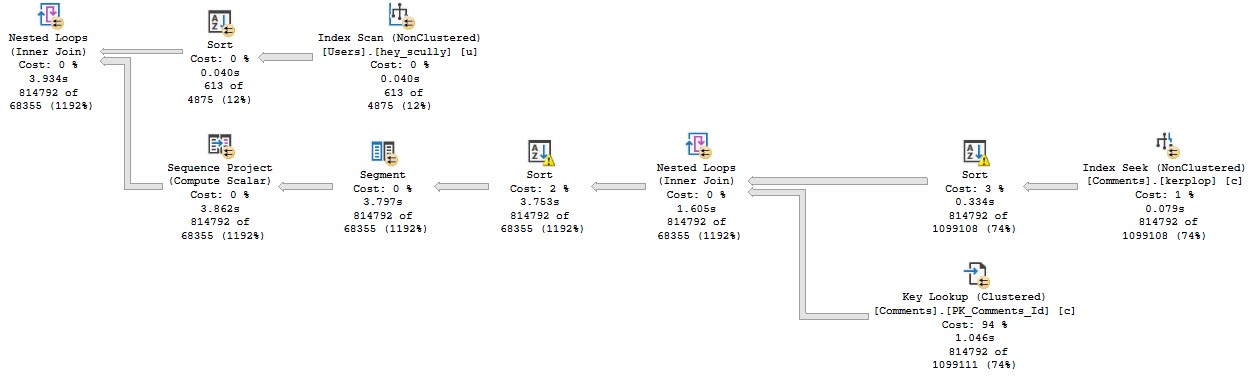
Some of this working is dependent on the query plan, so let’s look at those.
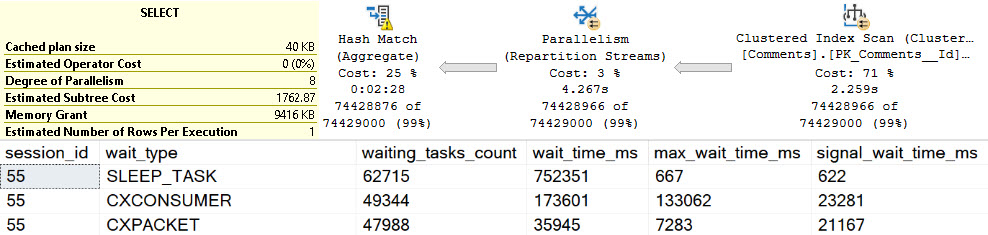
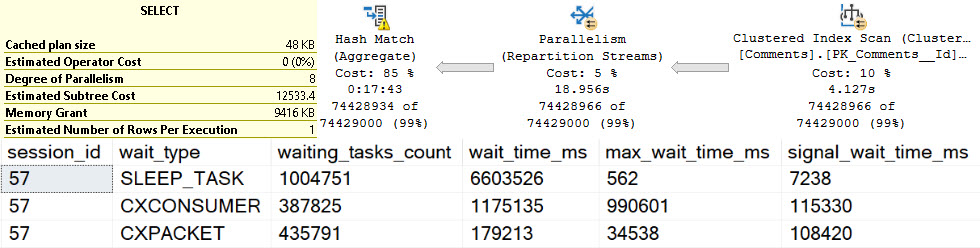
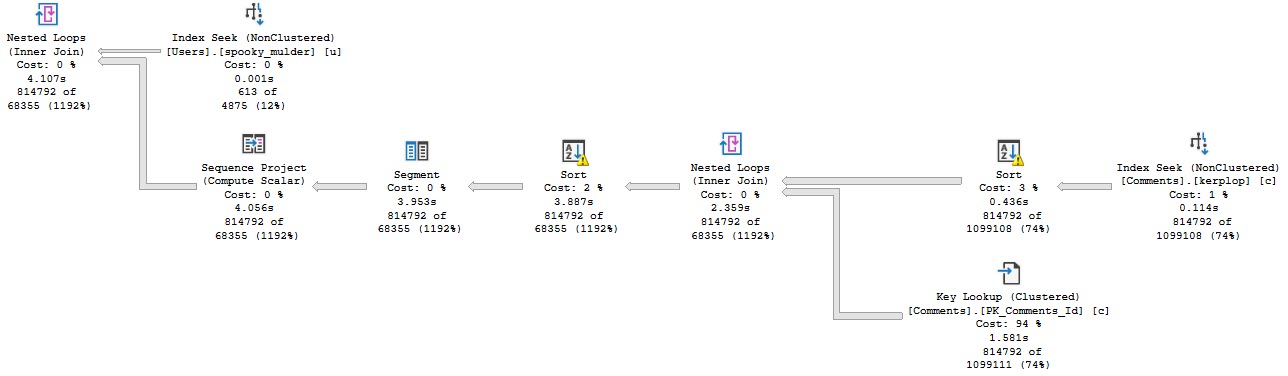
Pink Belly Plans
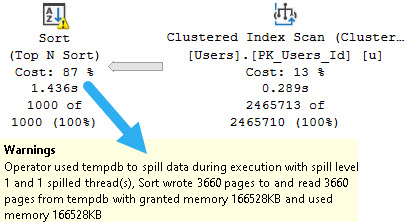
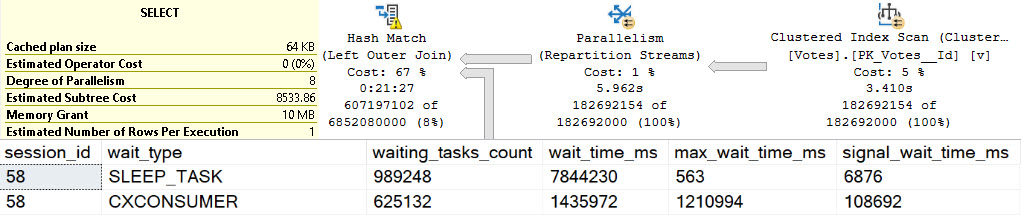
You can ignore the execution times here. The Body column is not a good representation of an oversized column.
It’s defined as nvarchar(max), but (if I’m remembering my Stack lore correctly) is internally limited to 30k characters. Many questions and answers are longer than 100 characters anyway, but on to the plans!
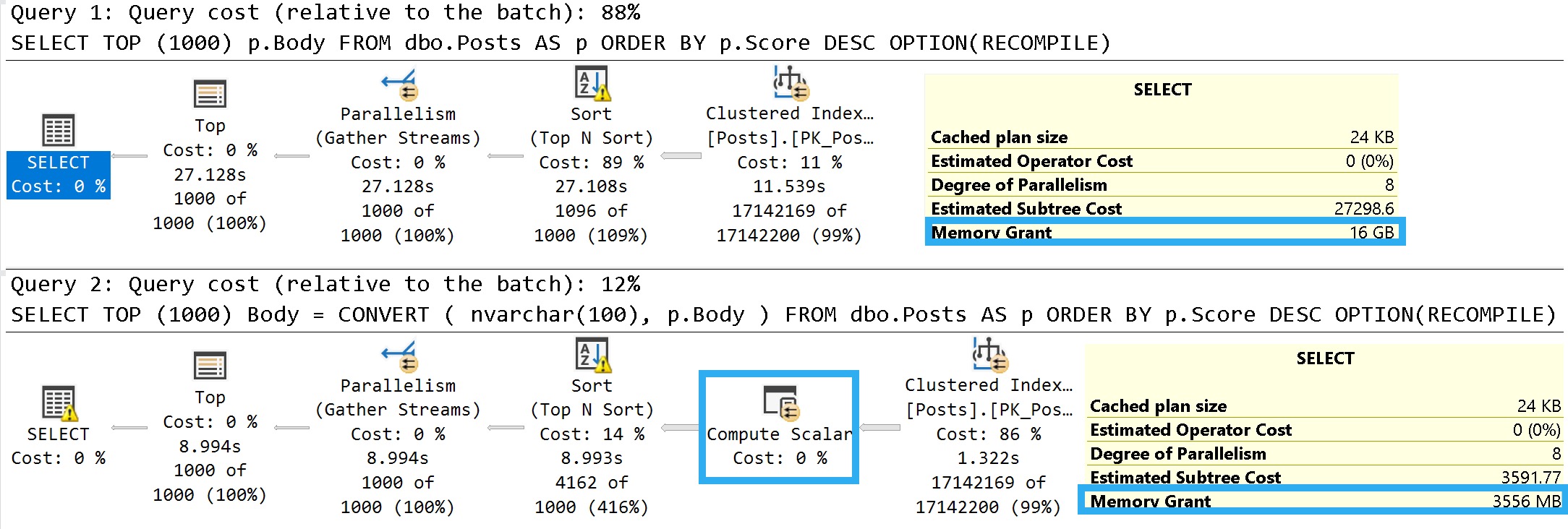
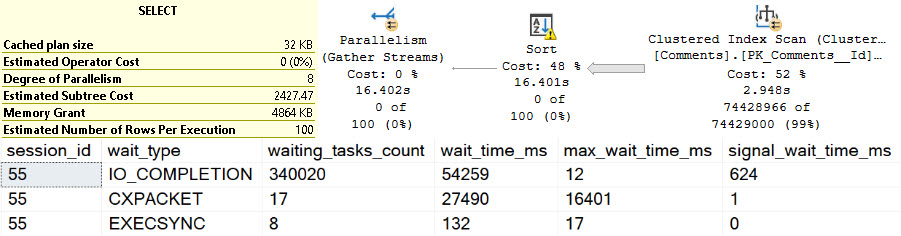
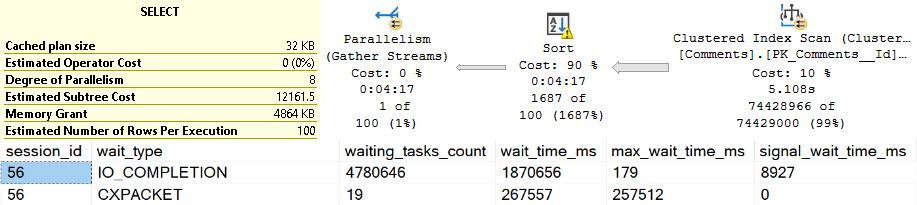
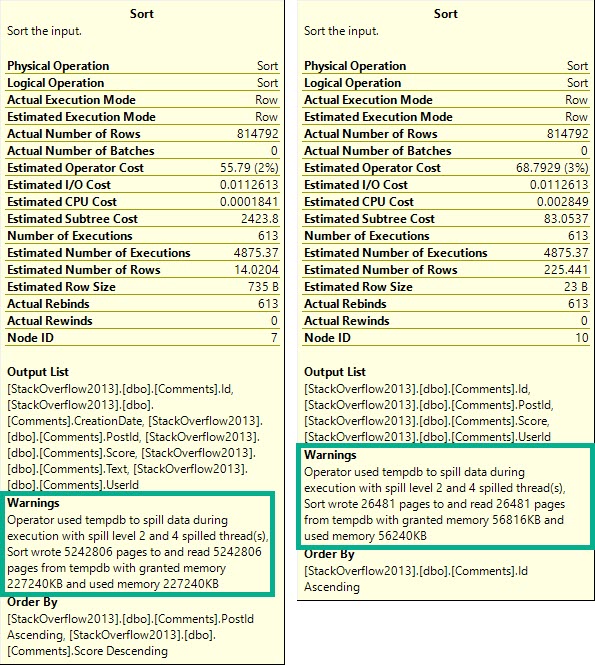
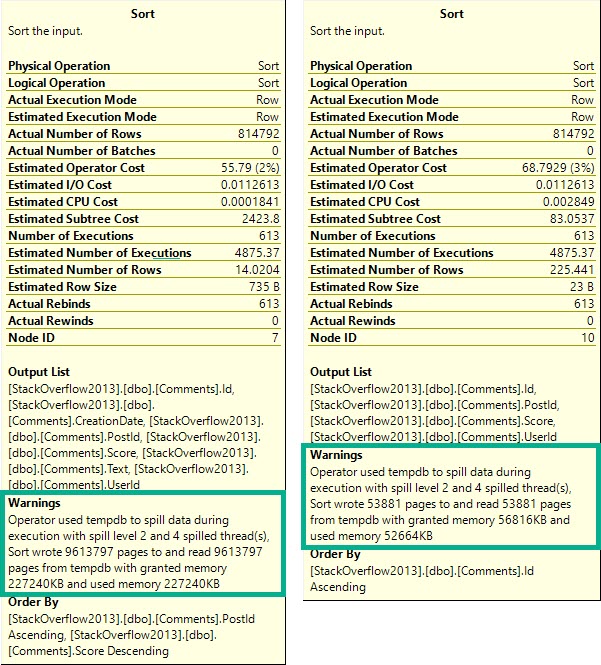
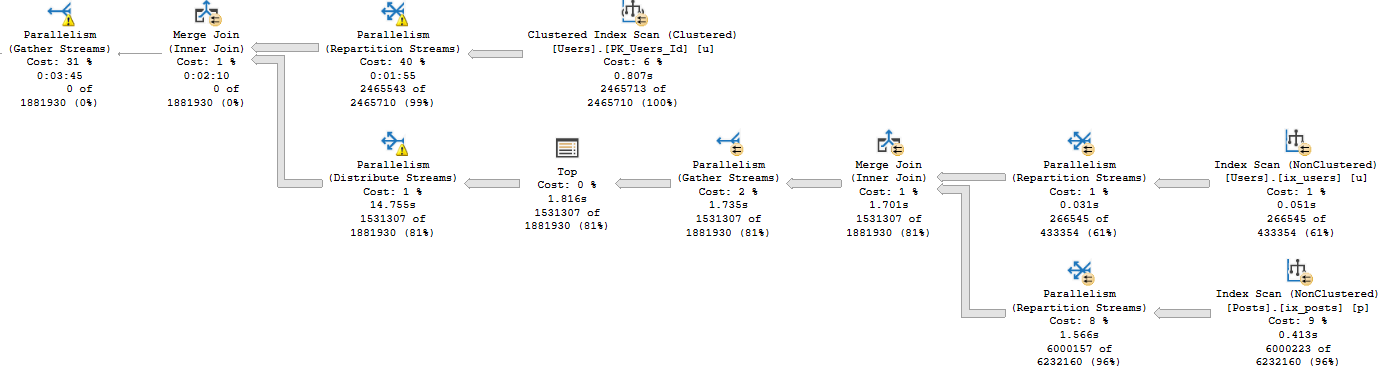
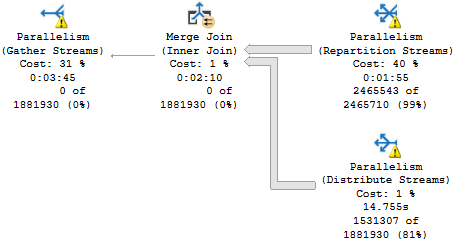
In the plan where the Body column isn’t converted to a smaller string length, the optimizer asks for a 16GB memory grant, and in the second plan the grant is reduced to ~3.5GB.
This is dependent on the compute scalar occurring prior to the Top N Sort operator, of course. This is where the convert function is applied to the Body column, and why the grant is reduced
If you were to build a view on top of the Posts table with this conversion, you could point queries to the view instead. That would get you the memory grant reduction without the pain of altering the column, or moving the data into a new table with the correct definition.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.