In this post, I’m gonna show you how stringing together a bunch of CTEs can cause performance problems with one of my paid training videos. If you like it, hit the link below to get 75% off the entire bundle.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
But some points should be made together, so I’m going to combine them a bit, and expand on a few points too.
I know that it’s probably an overly-lofty goal to expect people who don’t seem to have the hang of indexing regular tables down to not repeat those errors with #temp tables.
But hey, hope burns eternal. Like American Spirits (the cigarettes, not some weird metaphorical thing that Americans possess, or ghosts).
Nonclustered Index Follies: Creating Them Before You Insert Data
I’m not saying that you should never add a nonclustered index to a #temp table, but I am saying that they shouldn’t be your first choice. Make sure you have a good clustered index on there first, if you find one useful. Test it. Test it again. Wait a day and test it again.
But more importantly, don’t do this:
CREATE TABLE #bad_idea
(
a_number int,
a_date datetime,
a_string varchar(10),
a_bit bit
);
CREATE INDEX anu ON #bad_idea(a_number);
CREATE INDEX ada ON #bad_idea(a_date);
CREATE INDEX ast ON #bad_idea(a_string);
CREATE INDEX abi ON #bad_idea(a_bit);
Forget for a minute that these are a bunch of single-column indexes, which I’m naturally and correctly opposed to.
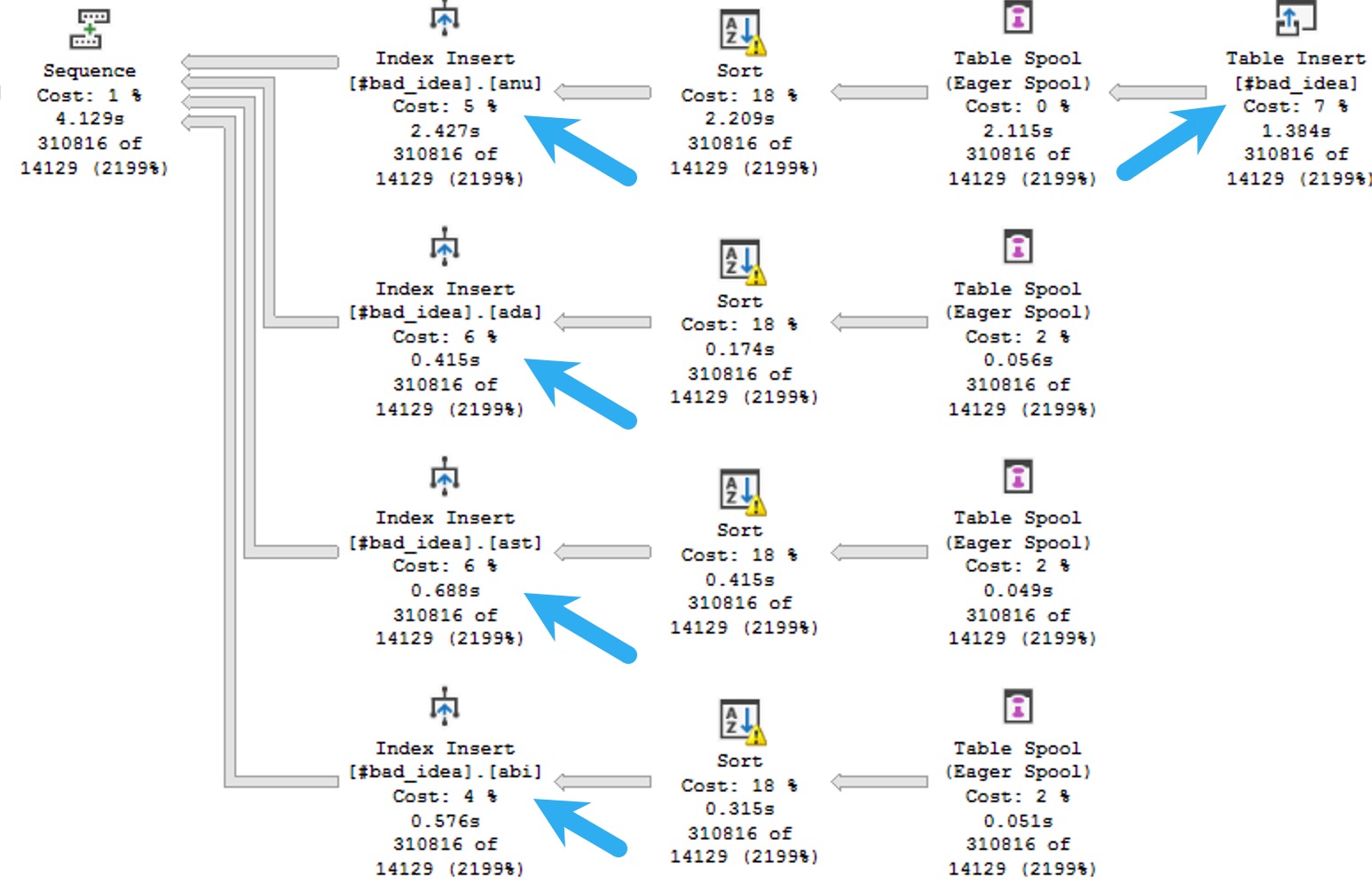
Look what happens when we try to insert data into that #temp table:
the bucket
You have to insert into the heap (that’s the base table here, since we don’t have a clustered index), and then each of the nonclustered indexes. In general, if you want nonclustered indexes on your #temp tables, you should create them after you insert data, to not mess with parallel inserts and to establish statistics with a full scan of the data.
Nonclustered Index Follies: If You Need Them, Create Them Inline
If for some insane reason you decide that you need indexes on your #temp table up front, you should create everything in a single statement to avoid recompilations.
CREATE TABLE #bad_idea
(
a_number int,
INDEX anu (a_number),
a_date datetime,
INDEX ada (a_date),
a_string varchar(10),
INDEX ast (a_string),
a_bit bit,
INDEX abi (a_bit)
);
Do not explicitly drop temp tables at the end of a stored procedure, they will get cleaned up when the session that created them ends.
Do not alter temp tables after they have been created.
Do not truncate temp tables
Move index creation statements on temp tables to the new inline index creation syntax that was introduced in SQL Server 2014.
There are some other good points there, too. Pay attention to those as well.
Of course, there is one interesting reason for dropping #temp tables: running out of space in tempdb. I tend to work with clients who need help tuning code and processes that hit many millions of rows or more.
If you’re constantly creating large #temp tables, you may want to clean them up when you’re done with them rather than letting self-cleanup happen at the end of a procedure.
This applies to portions of workloads that have almost nothing in common with OLTP, so you’re unlikely to experience the type of contention that the performance features which apply there also apply here. Reporting queries rarely do.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Serial zones in parallel plans can leave a lot of performance on the table. One of the best ways to see that is with insert queries that do a lot of work. A big contrast between @table variables and #temp tables is that the former fully disallows parallelism in modification queries, and the latter do not.
Let’s look at some scenarios where a fully parallel insert is allowed, and then not allowed.
The thing to keep an eye out for is the insert operator being in the serial zone. For the purposes of this thread:
attention, please
Works: SELECT INTO
As long as you don’t do anything too goofy here, a fully parallel insert will “always” be allowed, here.
Goofy things will be explained later in the post.
--This will "always" work, as long as you don't do
--anything listed below in the "broken" select
SELECT
C.UserId,
SumScore =
SUM(C.Score)
INTO
#AvgComments_SelectInto
FROM
dbo.Comments AS C
GROUP BY
C.UserId
HAVING
SUM(C.Score) > 200;
DROP TABLE #AvgComments_SelectInto;
Works: INSERT, with TABLOCK
Rather than selecting directly into a table, here we’re gonna create the table and issue an insert statement with the tablock hint.
--This *will* get you a fully parallel insert, unless goofiness is involved.
CREATE TABLE
#AvgComments_Tablock
(
UserId int,
SumScore int
);
INSERT
#AvgComments_Tablock WITH (TABLOCK)
(
UserId,
SumScore
)
SELECT
C.UserId,
AvgScore =
SUM(C.Score)
FROM
dbo.Comments AS C
GROUP BY
C.UserId
HAVING
SUM(C.Score) > 200
DROP TABLE #AvgComments_Tablock
Doesn’t Work: INSERT, without TABLOCK
Without the tablock hint, this will get you the plan we don’t want, where the insert operator is outside the parallel zone.
--This will not get you a fully parallel insert
CREATE TABLE
#AvgComments_NoTablock
(
UserId int,
SumScore int
);
INSERT
#AvgComments_NoTablock
(
UserId,
SumScore
)
SELECT
C.UserId,
SumScore =
SUM(C.Score)
FROM
dbo.Comments AS C
GROUP BY
C.UserId
HAVING
SUM(C.Score) > 200;
DROP TABLE #AvgComments_NoTablock;
Doesn’t Work: A Whole Laundry List Of Stuff
Basically any one thing quoted out has the ability to deny the parallel insert that we’re after.
If you’re doing any of this stuff, like, bye.
--SET ROWCOUNT Any_Number;
--ALTER DATABASE StackOverflow2013
-- SET COMPATIBILITY_LEVEL = Anything_Less_Than_130;
CREATE TABLE
#AvgComments_BrokenTablock
(
--Id int IDENTITY,
UserId int,
SumScore int,
--INDEX c CLUSTERED(UserId)
--INDEX n NONCLUSTERED(UserId)
);
--Also, if there's a trigger or indexed view on the target table
--But that's not gonna be the case with #temp tables
INSERT
#AvgComments_BrokenTablock WITH (TABLOCK)
(
UserId,
SumScore
)
--The rules here are a little weird, so
--be prepared to see weird things if you use OUTPUT
--OUTPUT Inserted.*
--To the client or
--INTO dbo.some_table
--INTO @table_varible
SELECT
--Id = IDENTITY(bigint, 1, 1),
--dbo.A_Scalar_UDF_Not_Inlined_By_Froid
C.UserId,
SumScore =
SUM(C.Score)
FROM
dbo.Comments AS C
--Any reference to the table you're inserting into
--Not exists is just an easy example of that
--WHERE NOT EXISTS
--(
-- SELECT
-- 1/0
-- FROM #AvgComments_BrokenTablock AS A
-- WHERE A.UserId = C.UserId
--)
GROUP BY
C.UserId
HAVING
SUM(C.Score) > 200;
DROP TABLE #AvgComments_BrokenTablock;
Explainer
There are many good reasons to want a fully parallel insert, but you need to make sure that the bottleneck isn’t earlier in the plan.
If it is, you may not see the full performance gains from getting it.
In general, it’s a good strategy when building larger #temp tables, but at this point I add a tablock hint to every #temp table insert at first to test things out.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
After yesterday’s post about when to use or not use @table variables in SQL Server, you can probably make choices more confidently.
Most of the time, you want to be using #temp tables, when plan choices and statistics matter to overall performance, and @table variables when code executes at a high frequency over a small-ish number of rows, where plan choices and statistics don’t matter to overall performance.
In case you didn’t pick that up, or something.
Let’s move on.
Use Cases For #Temp Tables
The best use cases for #temp tables are for materializing things like:
Just to name a few-plus-one things that can generally be improved.
There are many more, of course. But getting overly-encyclopedic in blog posts tends to be over-productive. Plus, no one reads them, anyway.
What I think the real value of breaking queries up into more atomic pieces is, though, is that it’s a bit easier to isolate exactly which parts are the slowest, and work on them independently.
When you’ve got one gigantic query, it can be difficult to tune or figure out how all the different pieces interact. What’s slow for one execution might be fast for another, and vice-versa.
Chomper
Of course, temporary objects aren’t always strictly necessary. Sometimes it’s enough to break disjunctive predicates up into UNION-ed clauses. Sometimes having the right index or using batch mode can get you where you need to go.
Choosing to use a temporary object comes with choices:
Can I afford to take up this much space in tempdb?
Can I afford to execute this under high concurrency?
Have I exhausted other options for tuning this query?
You don’t necessarily need to answer all of those things immediately, but you should exercise some domain knowledge during tuning efforts.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Temporary objects are one of those tricky things. You probably know you should be using them for certain things, but which one to use is a constant source of trial, error, and coin-tosses.
In these videos from my training, I’m going to go through the downsides of table variables. There’s one free video from YouTube at the end about when you should use them, too.
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
This post is rather short, because it’s more of a link round-up than anything.
I think that index compression is so generally useful that I’d start off any new system with it enabled, just to avoid issues with needing to apply it later. Where it’s particularly useful is on systems where data is plenty, and memory is scarce.
Having index structures that are much smaller both on disk and in memory is quite useful. It’s also nice when you’re on Standard Edition, and you need to make the most of out the 128GB cap on the buffer pool.
For some great information and detail on index compression, check out My Friend Andy™ who has very helpful blog posts about it.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
It’s hard to believe that this is still a lively debate, given how far technology has come since the original conversations around if and when fragmentation is a problem were a thing, but here we are in 2020 for the third year straight.
I will give people some credit where it’s due, I’ve seen index maintenance habits change a bit over the years:
Reducing frequency to once a week or once a month from every night
Bumping the thresholds that they reorg and rebuild way higher than 5% and 30%, like 50% and 80%
Abandoning it all together when using AGs or other data synchronization technologies
It’s a good start, but people still ascribe far too many benefits to doing it. Rather than rehash everything I’ve ever said about it, I’m gonna post a video of Erin Stellato (b|t) and I discussing the pros, cons, whens, wheres, whys, and hows in this video:
Thanks for reading (and watching)!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I can’t remember the last time I saw someone lower fill factor for a good reason. Perhaps those just aren’t the type of folks who need my help, or perhaps no one has done it for a good reason since Windows 2003 dropped and part of Any Good Consultation™ was checking to make sure disks were aligned properly.
What a bad time for disks, that was. Thank the Magnetic Fields that SSD and Flash came along to sit at the other end of a SAN with a shoestring and some Dixie cups between them.
But anyway, the story used to go something like this:
We have a lot of page splits
Are they good or bad?
Aren’t they all bad?
No, but we should look more closely at page density to figure out…
FIXED IT!
What?
I set Fill Factor to 70 for everything. We’re cool.
This is, of course, wrong-headed in the same way that applying anything that works to fix a specific thing across the board is.
What Fill Factor Does
When you change Fill Factor, whether it’s at the database level, or index level, is leave your chosen percent as free space. on each data page at the leaf level of an index. But only when you rebuild or reorganize them. At no point in-between does SQL Server care about that percentage.
At the very best, you’re only buying yourself some time until you have “page splits” again. Depending on how busy a bottom your table is, you might need to do index maintenance quite frequently in order to get that fill factor back.
I can’t imagine how anyone would track bad page splits in a meaningful way, and apply fill factor in a way that would permanently keep them at bay.
The worst part about Fill Factor is that it gets applied to all pages — even ones that are in no danger of facing a split — and every time you apply it, your indexes get bigger as you add free space back to new pages.
Since people always seem to want to shrink the ever lovin’ beet juice out of their databases, I assume they hate big databases that take up a lot of disk space. One way to get a big database really fast is to add a bunch of empty space to all of your tables and indexes.
What Fill Factor Doesn’t Do
Fill Factor doesn’t make read queries faster, especially if you’ve designed them mostly to accommodate Seeks in an OLTP environment. Seeks do not fall victim to these things the way scans do, because they navigate to individual rows.
They do just about the same amount of work no matter what, unless you add more levels to your indexes, but that tends to happen as they get larger, anyway.
And, good news, lowering Fill Factor will make Big Scans way slower. Why? They have to read more pages, because you decided to add a bunch of empty space to them. You’re really racking up the wins here, boss.
Not only is your database artificially huge, but all those reporting queries you’re worried about bringing your transactional queries to a halt take longer and do the dreaded “more reads” 😱 😱 😱
I often call Fill Factor “silent fragmentation”, because it reduces the density of your data pages dramatically, depending on what you lower it to. And it’s the actual bad kind of fragmentation — physical fragmentation — not the stuff your index maintenance scripts look at.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
In yesterday’s post, we covered some of the basics of designing nonslustered indexes to make queries go faster, but sometimes those aren’t quite enough.
In today’s post, I’m going to give you more of my paid training about filtered indexes and indexed views.
What I cover here is how to use them correctly, and some of the things they just don’t work well with. Again, if you like what you see, hit the link at the end of the post for 75% off.
Filtered Indexes
Here’s the intro to filtered indexes
Here are the demos:
Indexed Views
Here’s the intro to indexed views:
Here are the demos for indexed views:
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
There’s a bit of magic to index tuning, once you move beyond the basics. But we do have to start with the basics. In order to do that quickly, I’m putting a couple videos from my paid training in this post. If you like what you see, hit the link at the end of the post to get 75% off everything.
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.