Just In Case
There are some circumstances where you can use this approach in a non-harmful way. In general it’s something you should avoid, though, especially if you’re not sure how to tell if it’s harmful or not.
This is one of those unfortunate query patterns that leads to you getting called nights and weekends because the server blew up. I’ve seen it do everything from generate a reliably bad query plan, to adding just enough of an element of cardinality uncertainty that slight plan variations felt like parameter sniffing — even with no parameters involved!
Uncertainty is something we’ve covered quite a bit in this series, because if you don’t know what you want, SQL Server’s optimizer won’t either.
Up The Bomb
Let’s start with a reasonable index on the Posts table:
CREATE INDEX p ON
dbo.Posts
(
PostTypeId,
OwnerUserId
);
We don’t need a very complicated query to make things bad, even with that stunningly perfect index in place.
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON 1 = CASE
WHEN p.PostTypeId = 1
AND p.OwnerUserId = u.Id
THEN 1
WHEN p.PostTypeId = 2
AND p.OwnerUserId = u.AccountId
THEN 1
ELSE -1
END
WHERE u.Reputation > 500000;
This returns a count of 3,374, and runs for about a minute total.
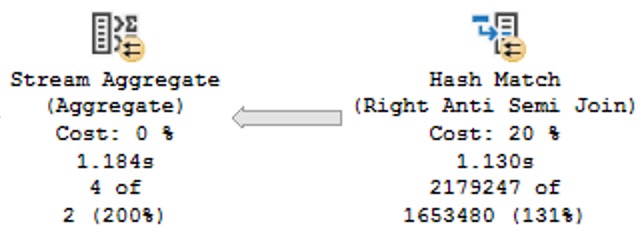
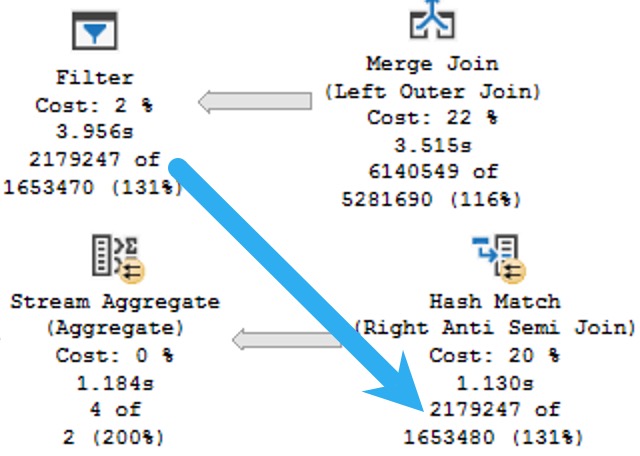
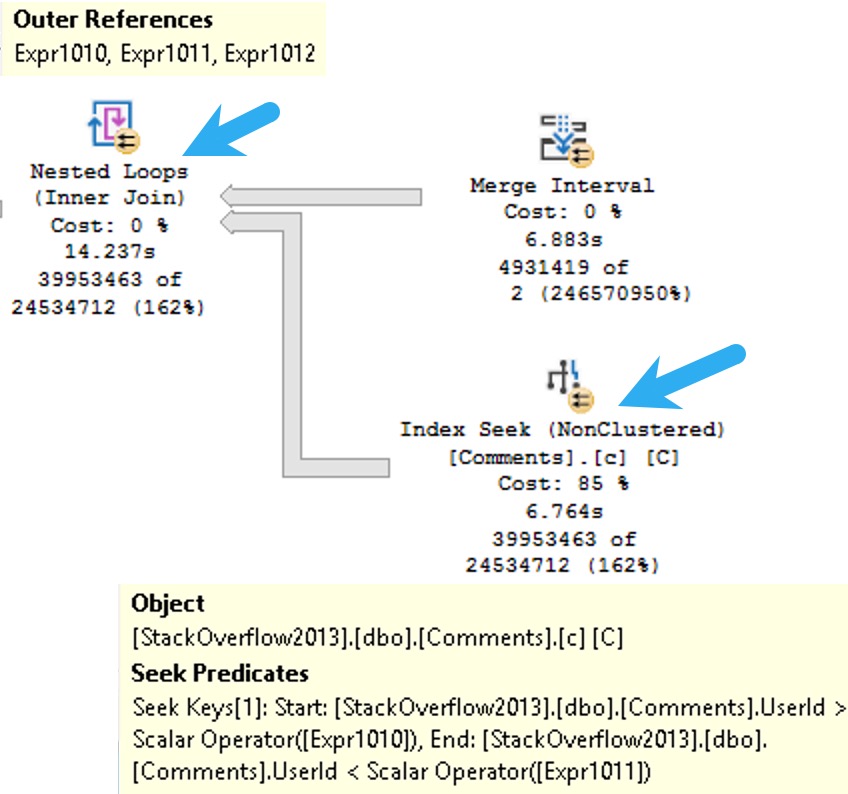
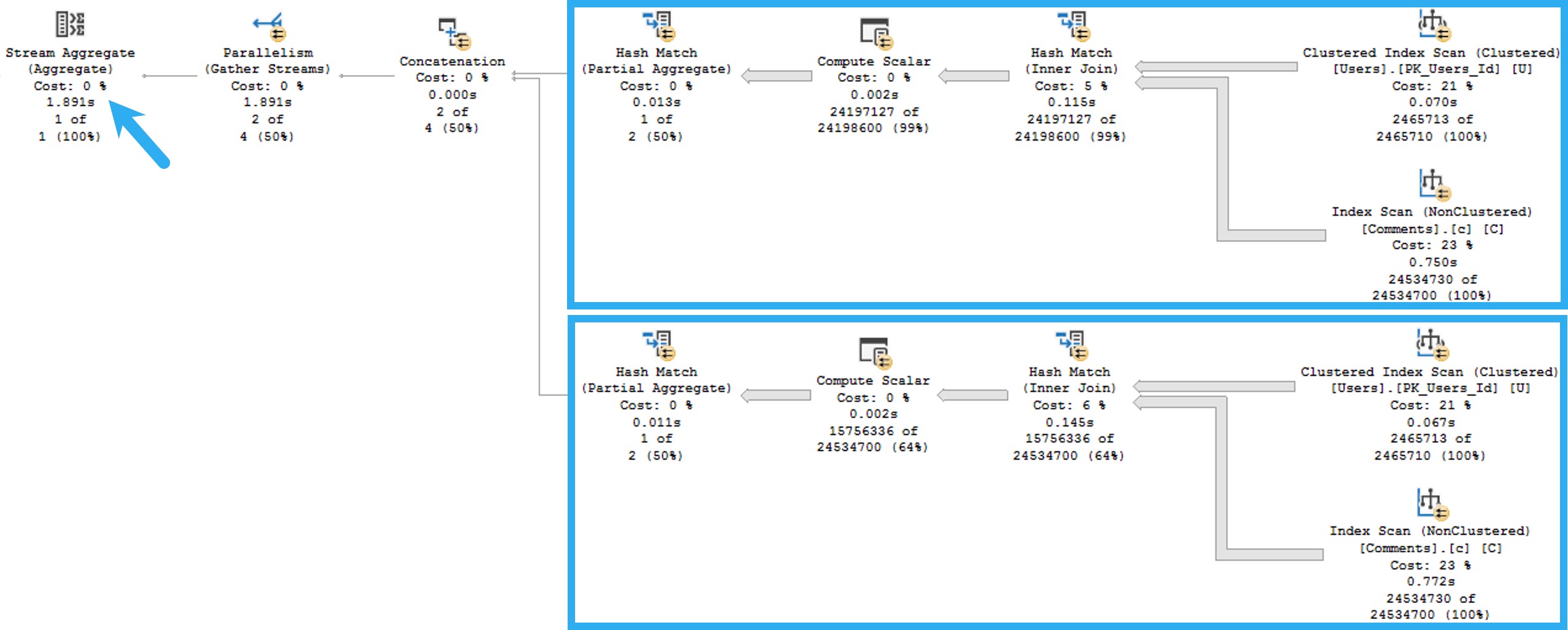
Naughty Query Plan
The plan for this may look innocent enough, but it’s one of those cases where a Lazy Table Spool is a warning sign.

Operator times in query plans are generally a blessing, because they show you where execution time ratchets up. Unfortunately, it’s not always clear what you have to do to fix the problems they show you.
I suppose that’s what posts like this are for, eh?
Oh, what a feeling.
Rewriting The Query
A Useful Rewrite© of this query looks something like this, at least if you’re a fancy-pants blogger who cares a lot about formatting.
SELECT
c = COUNT_BIG(*)
FROM
(
SELECT
u.Id,
u.AccountId
FROM dbo.Users AS u
WHERE u.Reputation > 500000
) AS u
CROSS APPLY
(
SELECT
p.*
FROM dbo.Posts AS p
WHERE p.PostTypeId = 1
AND p.OwnerUserId = u.Id
UNION ALL
SELECT
p.*
FROM dbo.Posts AS p
WHERE p.PostTypeId = 2
AND p.OwnerUserId = u.AccountId
) AS c;
I’m using a derived table here because if I used a Common Table Expression, you’d think they have some ridiculous magic powers that they really don’t, and one wouldn’t make the query any more readable.
Caring about formatting makes queries more readable.
Good game.
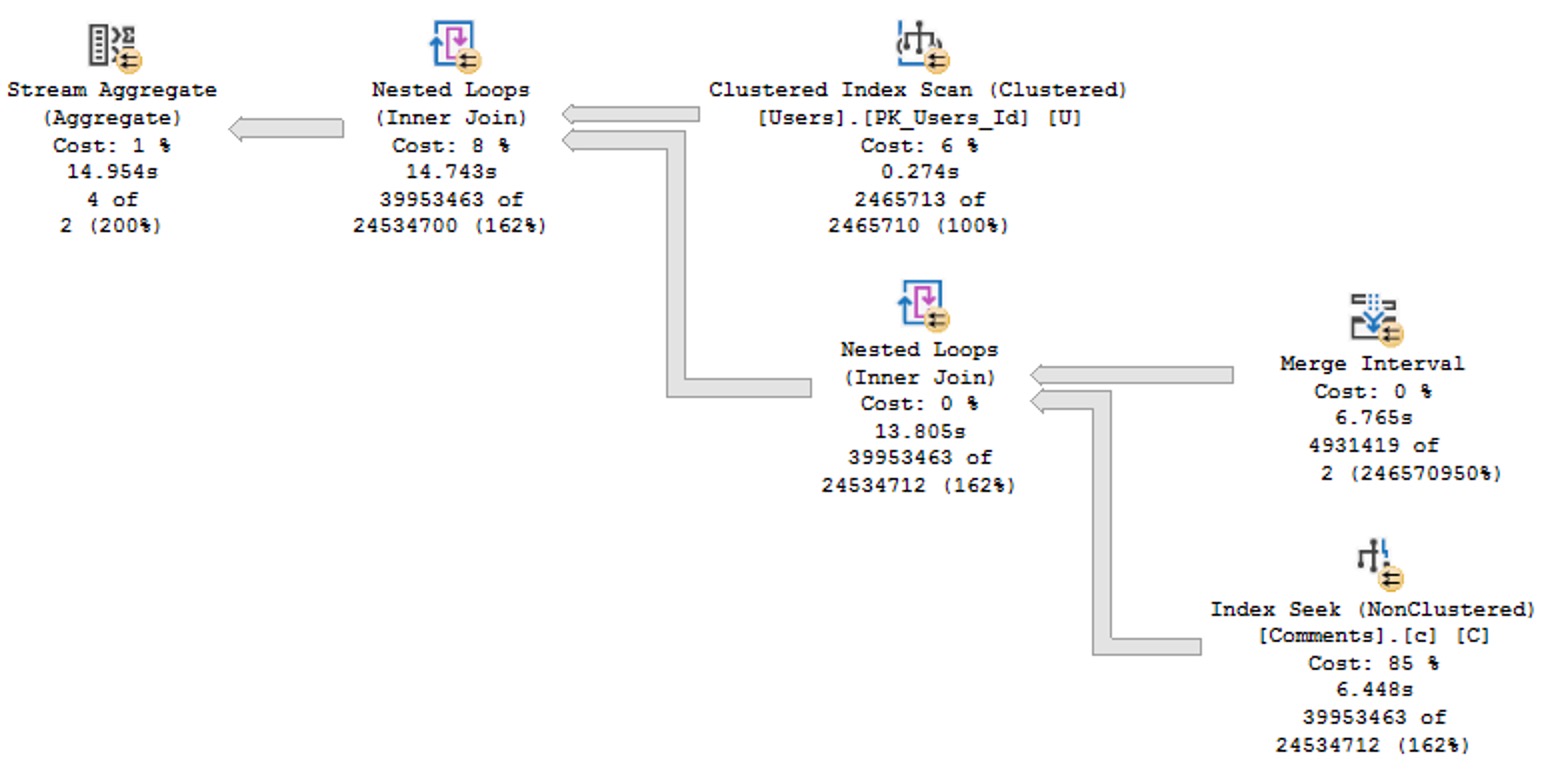
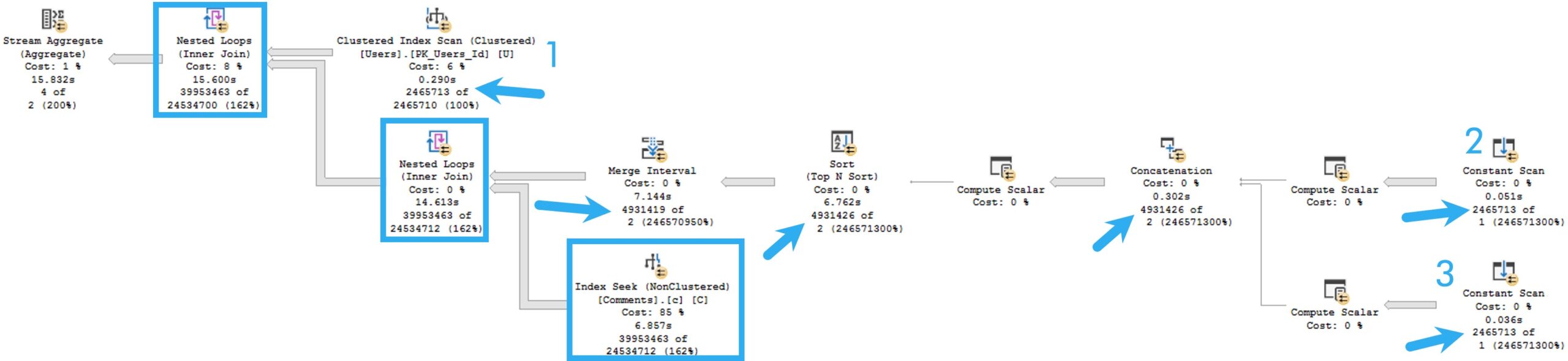
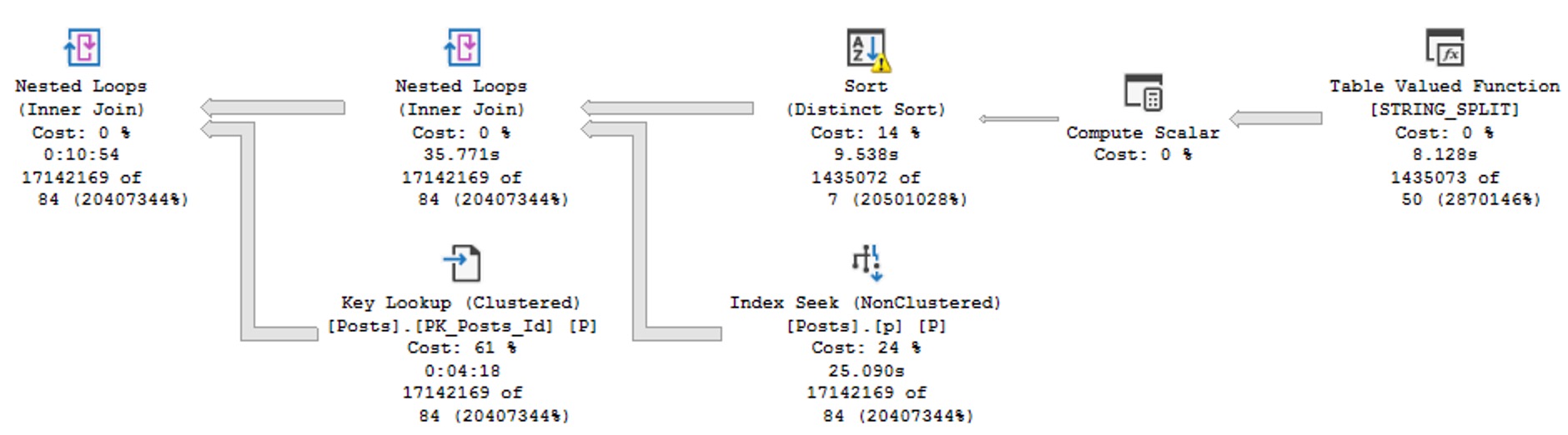
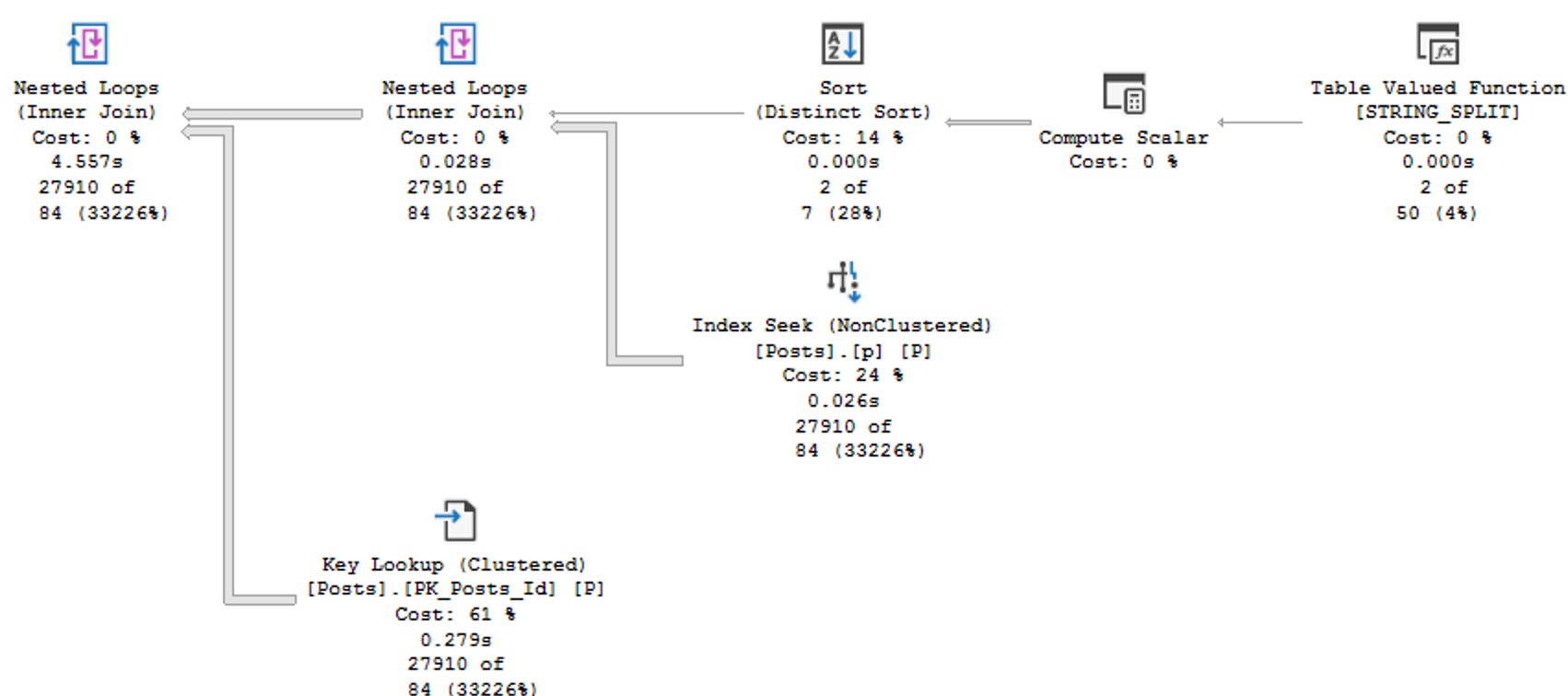
Nice Query Plan
You’ll notice that this plan no longer features a Table Spool, no longer runs for over a minute, and makes me happy.
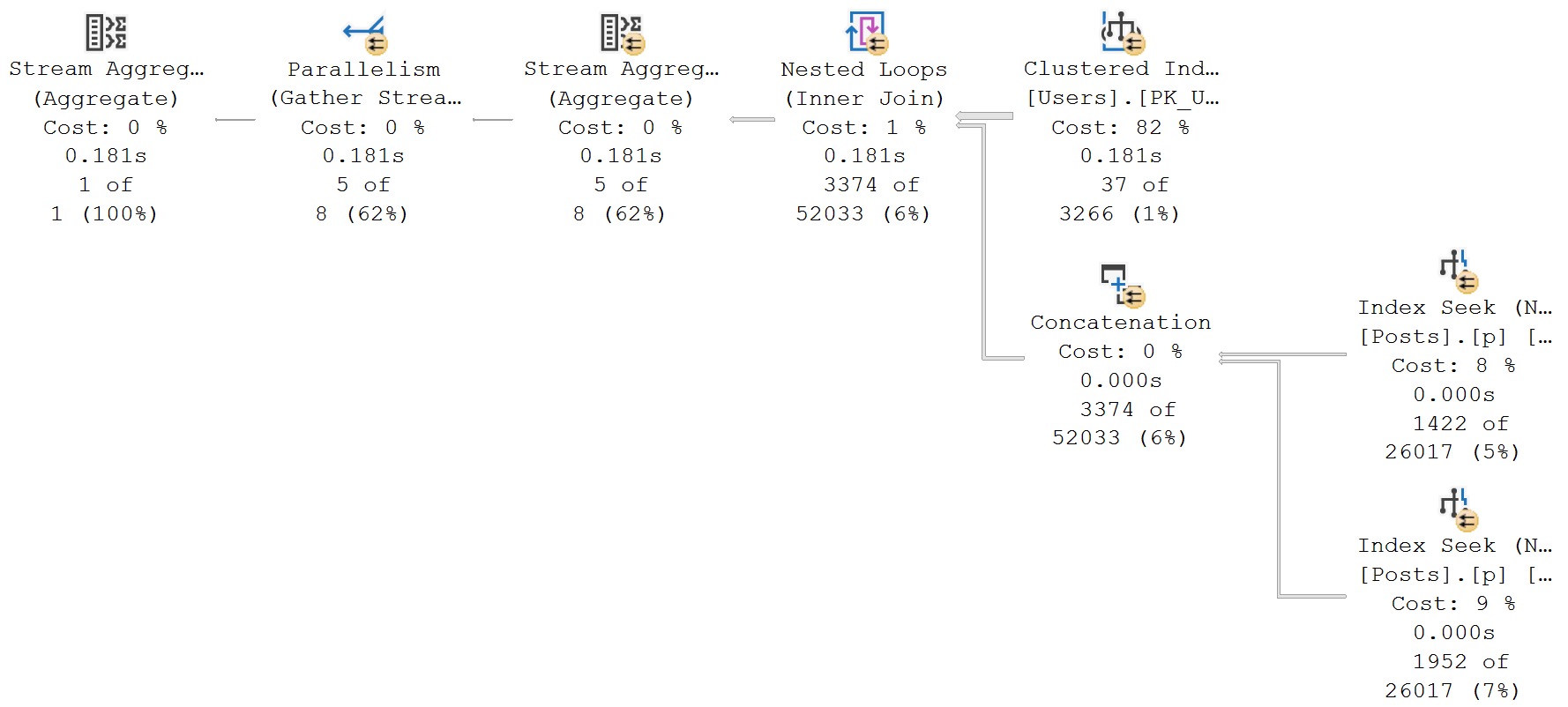
I’m not a math major, but 181 milliseconds seems like a great improvement over 60 seconds.
Suede Shoes
This is another case of more typing for us results in a faster query. Perhaps there’s some wisdom to learning how to clearly express oneself before starting a career talking to databases.
Database Communications Major, or something. Just don’t buy it from Sally Struthers.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.