Get Around
The more people want to avoid fixing what’s really wrong with their server, the more they go out and find all the weird stuff that they can blame on something else (usually the product), or keep doing the same things that aren’t fixing the problem.
Spinlocks are one of those things. People will measure them, stare at them, Google them, and have no idea what to make of them, all while being sure there’s something going on with them.
I don’t want to discount when spinlocks can actually cause a problem, but you shouldn’t treat every performance problem like it’s a bridge too far from what you can solve.
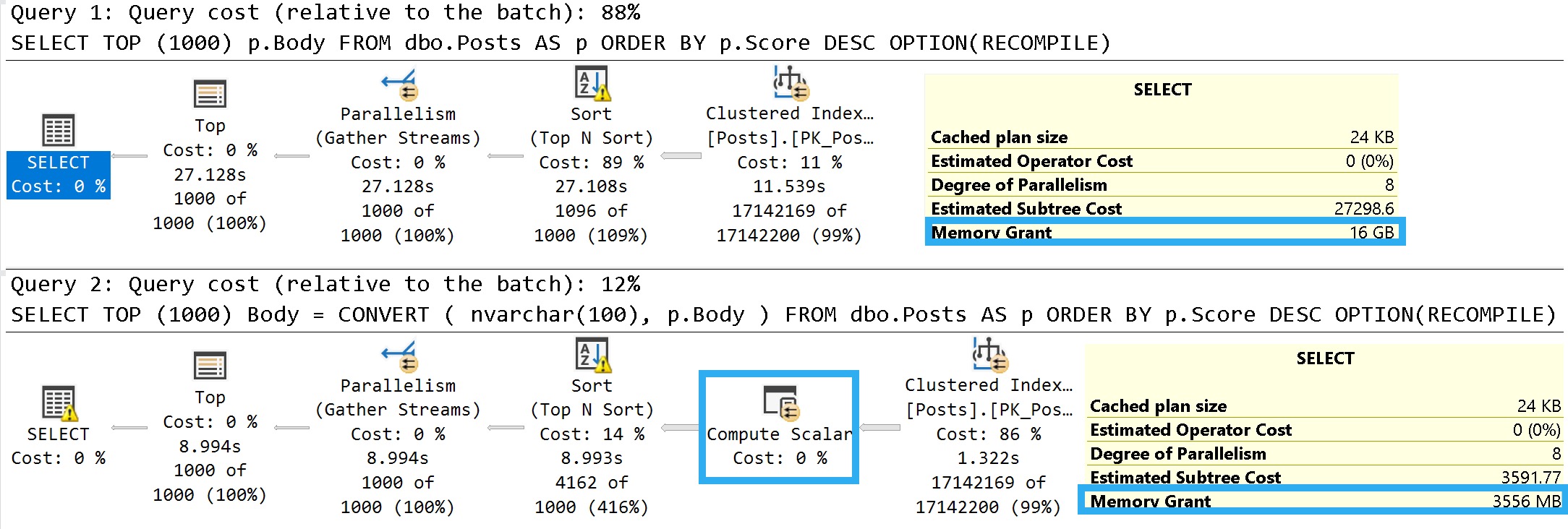
Before you go ignoring all the other things that are going wrong, here’s a simple script to give you some idea if you need to follow the spinlock trail any further. Note that it might also be worth replacing the s.spins sort order with s.spins_per_collision, too.
Which sort order you choose long-term will depend on which yields numbers of interest on your system, which I can’t predict. Sorry about that.
SELECT TOP (20)
days_uptime =
CONVERT(decimal(38,2), d.seconds_uptime / 86400.),
rundate =
SYSDATETIME(),
s.name,
s.collisions,
collisions_per_second =
CONVERT(bigint, s.collisions / d.seconds_uptime),
s.spins,
spins_per_second =
CONVERT(bigint, s.spins / d.seconds_uptime),
s.spins_per_collision,
spins_per_collision_per_second =
CONVERT(decimal(38,6), s.spins_per_collision / d.seconds_uptime),
s.sleep_time,
sleep_time_per_second =
CONVERT(bigint, s.sleep_time / d.seconds_uptime),
s.backoffs,
backoffs_per_second =
CONVERT(bigint, s.backoffs / d.seconds_uptime)
FROM sys.dm_os_spinlock_stats AS s
CROSS JOIN
(
SELECT
seconds_uptime =
DATEDIFF
(
SECOND,
d.sqlserver_start_time,
SYSDATETIME()
)
FROM sys.dm_os_sys_info AS d
) AS d
ORDER BY s.spins DESC;
Telltale
I understand that some spinlocks tend to happen in storms, and that this isn’t going to help to illuminate many situations when run in isolation. Bursty workloads, or workloads that only hit some crazy amount of spinlocks during shorter periods of high activity might escape it.
It can help you put the number of spinlocks you’re hitting in perspective compared to uptime, though.
If you see any numbers in the results that still make you say the big wow at your screen, you can easily log the output to a table every X minutes to gather more detail on when it’s happening.
Once you figure out when any potentially large spikes in spinlocks are occurring, you can match that up with:
- Any independent query logging you’re doing
- The plan cache, if it’s reliable
- Query Store, if you’re smart enough to turn it on
- Your monitoring tool data
Which should tell you which queries were executing at the time. I’d probably look for any high CPU effort queries, since those tend to be the spinlockiest in my experience.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.