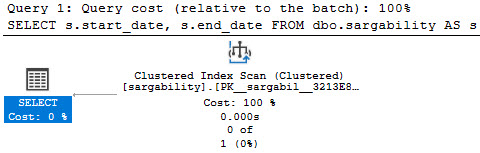
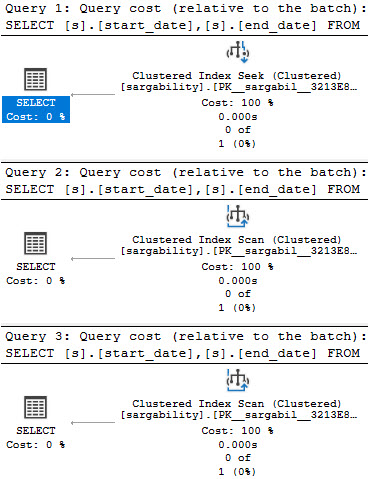
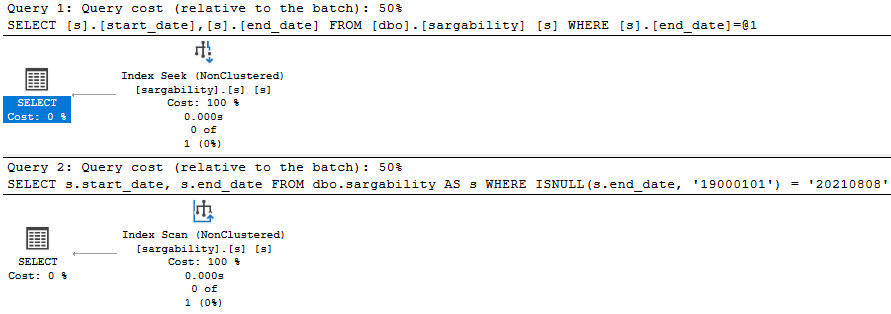
Specific
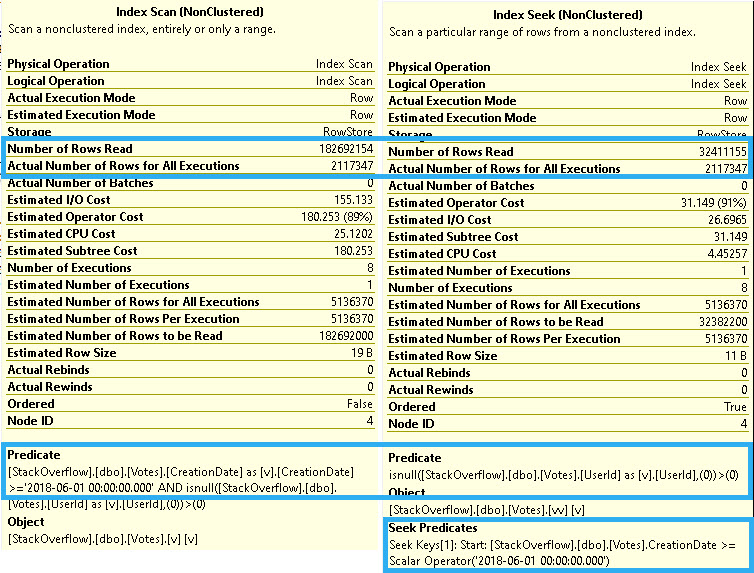
The non-SARGABLE pattern that dynamic SQL helps you deal with is the the catch all query pattern, which can look like:
- col = @parameter or @parameter is null
- col = isnull(@parameter, col)
- col = coalesce(@parameter, col)
Or any similar variation of null/not null checking of a parameter (or variable) in the where/join clause at runtime.
Dynamic SQL allows you to build up the specific where clause that you need for the non-NULL set of search filters.
But First
Let’s look at one of my favorite demos, because it very simply shows the goofy kind of things that can go wrong when you don’t practice basic query hygiene.
I’m going to create these two indexes:
CREATE INDEX osc ON dbo.Posts
(OwnerUserId, Score, CreationDate);
CREATE INDEX po ON dbo.Posts
(ParentId, OwnerUserId);
They are fundamentally and obviously different indexes.
The query has a where clause on OwnerUserId and CreationDate, and an order by on Score.
The select list is, of course, everything.
DECLARE
@OwnerUserId int = 22656,
@CreationDate datetime = '20190101',
@SQLString nvarchar(MAX) = N'
SELECT
p.*
FROM dbo.Posts AS p
WHERE (p.OwnerUserId = @OwnerUserId OR @OwnerUserId IS NULL)
AND (p.CreationDate >= @CreationDate OR @CreationDate IS NULL)
ORDER BY p.Score DESC;
';
EXEC sys.sp_executesql
@SQLString,
N'@OwnerUserId INT,
@CreationDate DATETIME',
@OwnerUserId,
@CreationDate;
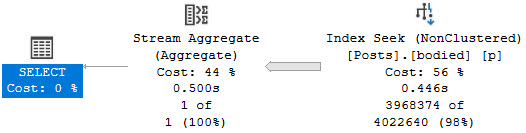
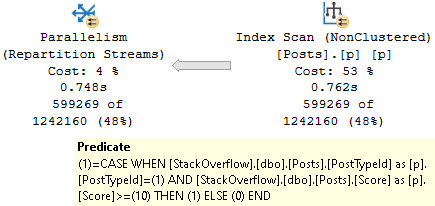
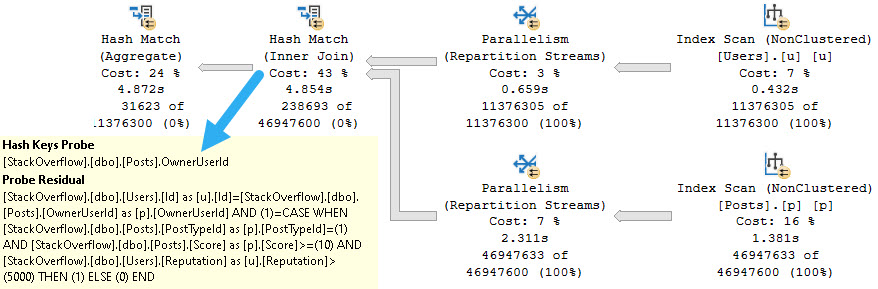
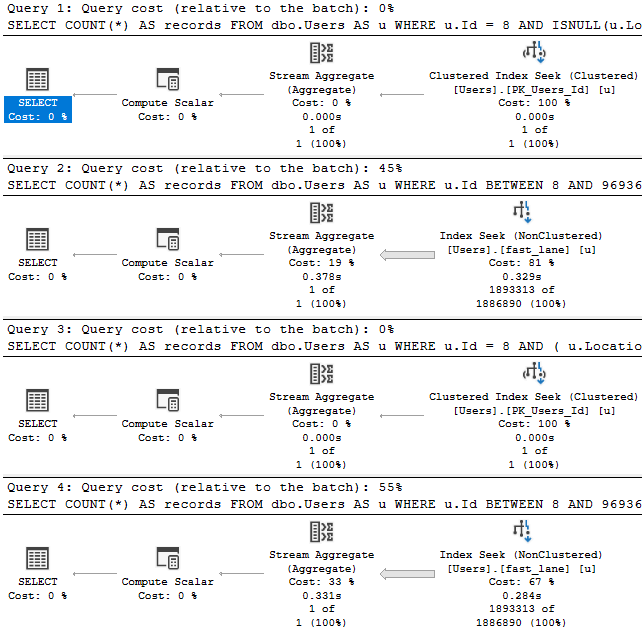
But when we execute it, it uses the index on ParentId and OwnerUserId.
This is completely bizarre given the requirements of the query.
Now Second
Yes yes, I know, Captain Recompile. A hint will fix this problem. But then you might have another problem. Or a whole bunch of other problems.
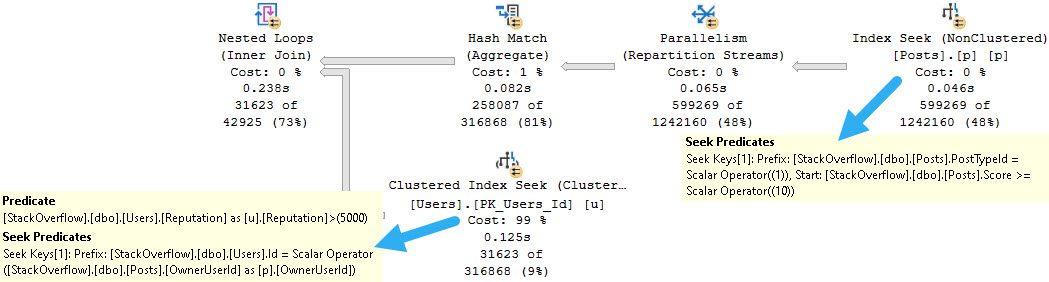
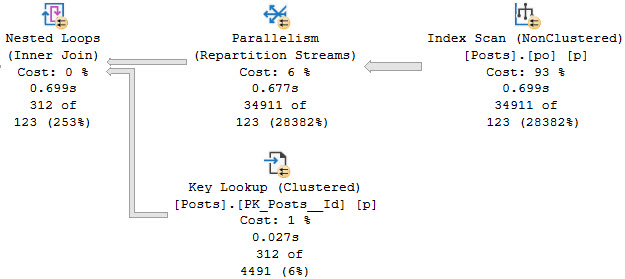
Here’s an example of nice, safe dynamic SQL that gets the correct index used and a much more efficient query overall.
DECLARE
@OwnerUserId int = 22656,
@CreationDate datetime = '20190101',
@SQLString nvarchar(MAX) = N'
SELECT
p.*
FROM dbo.Posts AS p
WHERE 1 = 1' + NCHAR(10)
IF @OwnerUserId IS NOT NULL
BEGIN
SET @SQLString += N'AND p.OwnerUserId = @OwnerUserId' + NCHAR(10)
END
IF @CreationDate IS NOT NULL
BEGIN
SET @SQLString += N'AND p.CreationDate >= @CreationDate' + NCHAR(10)
END
SET @SQLString += N'ORDER BY p.Score DESC;'
PRINT @SQLString;
EXEC sys.sp_executesql
@SQLString,
N'@OwnerUserId INT,
@CreationDate DATETIME',
@OwnerUserId,
@CreationDate;
And On The Seventh Day
The title of this series is SARGability week, and at first I had five posts set to go on this. As I was writing, I realized there were a few other things that I wanted to cover.
Next week I’m going to talk about max data types, user defined functions, and implicit conversions, then wrap things up.
Unless I think of something else. After all, I’m writing this on the 9th. Time travel, baby!
Thanks for reading
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.