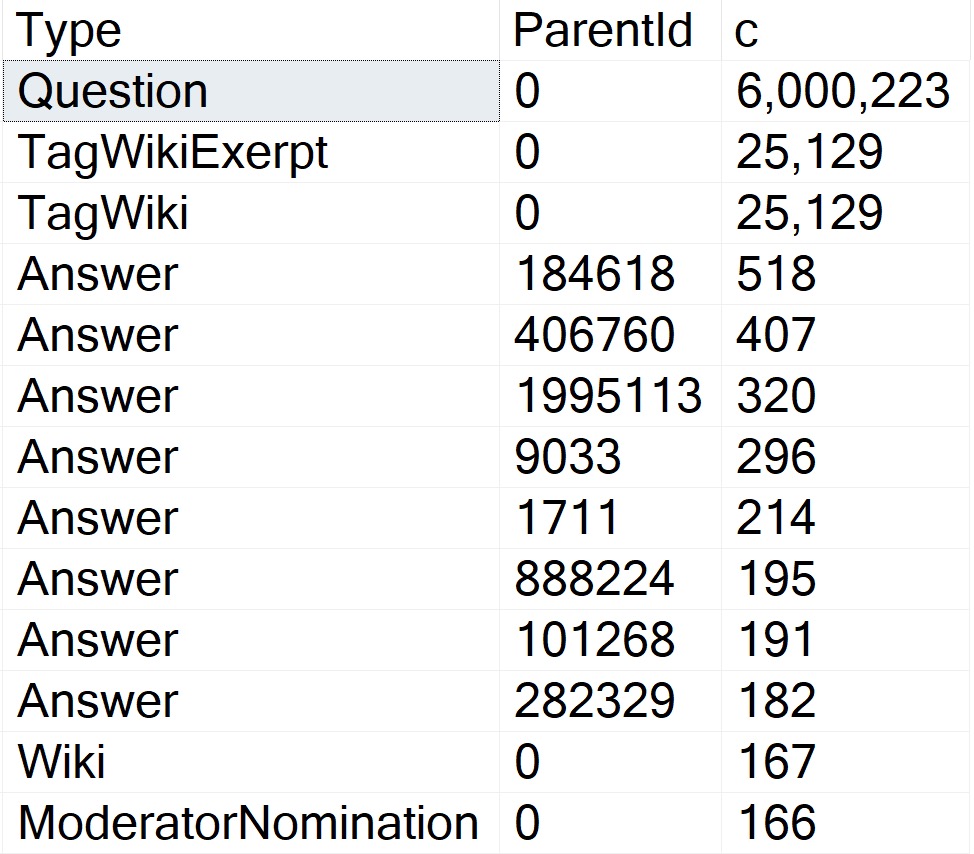
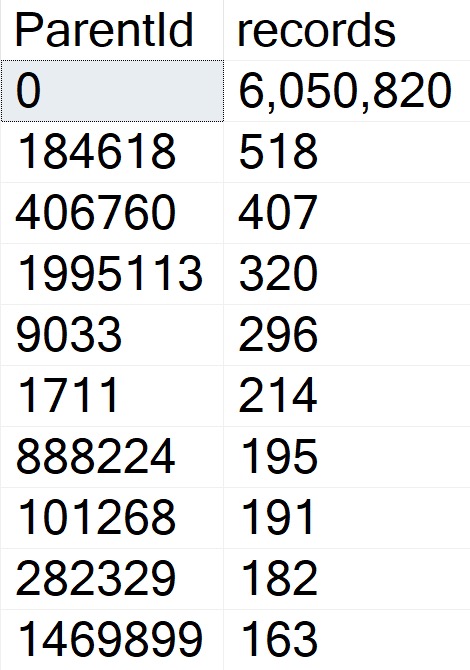
OldBad
I admit that sp_prepare is an odd bird, and thankfully one that isn’t used a ton. I still run into applications that are unfortunate enough to have been written by people who hate bloggers and continue to use it, though, so here goes.
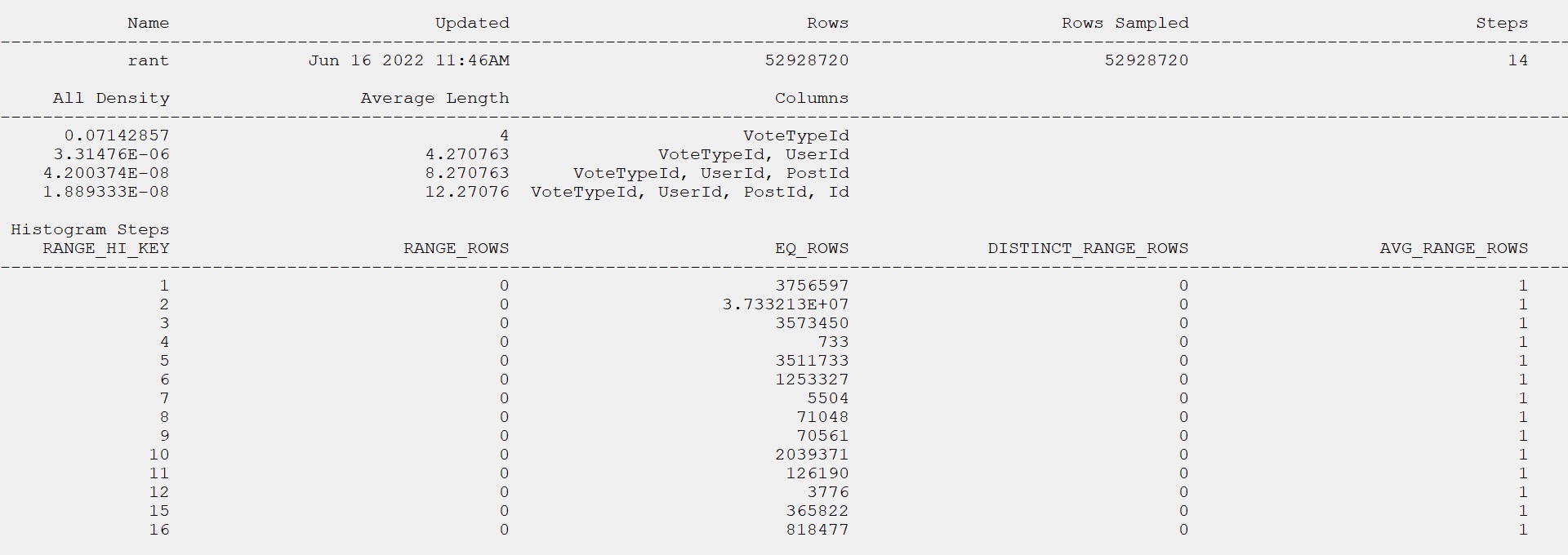
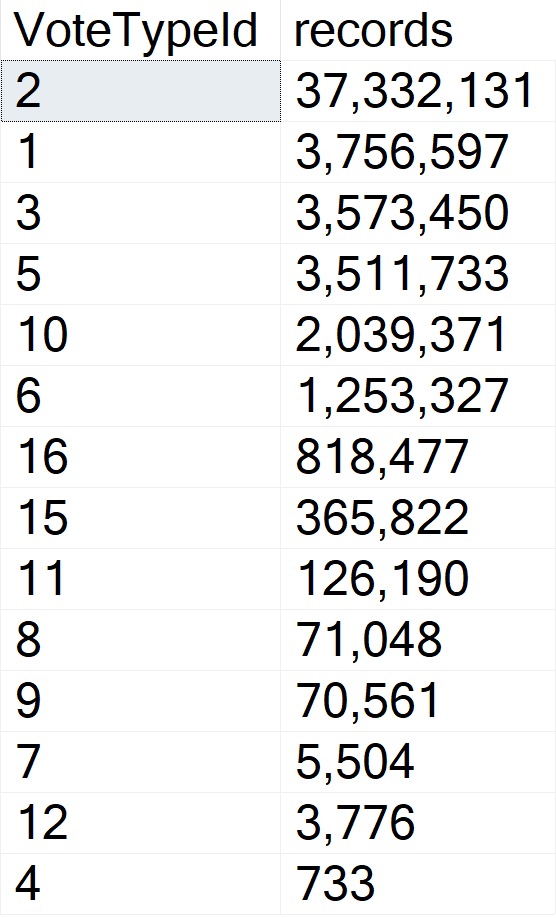
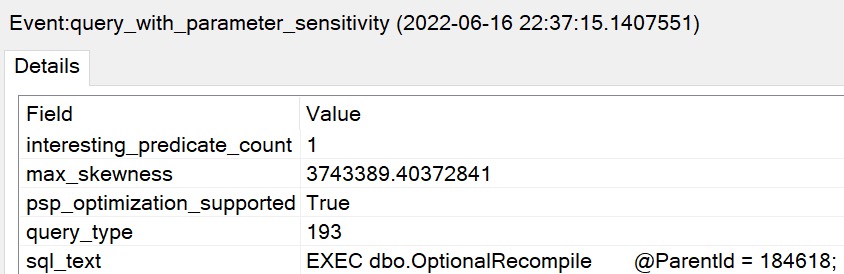
When you use sp_prepare, parameterized queries behave differently from normal: the parameters don’t get histogram cardinality estimates, they get density vector cardinality estimates.
Here’s a quick demo to show you that in action:
CREATE INDEX
p
ON dbo.Posts
(ParentId)
WITH
(
SORT_IN_TEMPDB = ON,
DATA_COMPRESSION = PAGE
);
DECLARE
@handle int =
NULL,
@parameters nvarchar(MAX) =
N'@ParentId int',
@sql nvarchar(MAX) =
N'
SELECT
c = COUNT_BIG(*)
FROM dbo.Posts AS p
WHERE p.ParentId = @ParentId;
';
EXEC sys.sp_prepare
@handle OUTPUT,
@parameters,
@sql;
EXEC sys.sp_execute
@handle,
184618;
EXEC sys.sp_execute
@handle,
0;
EXEC sys.sp_unprepare
@handle;
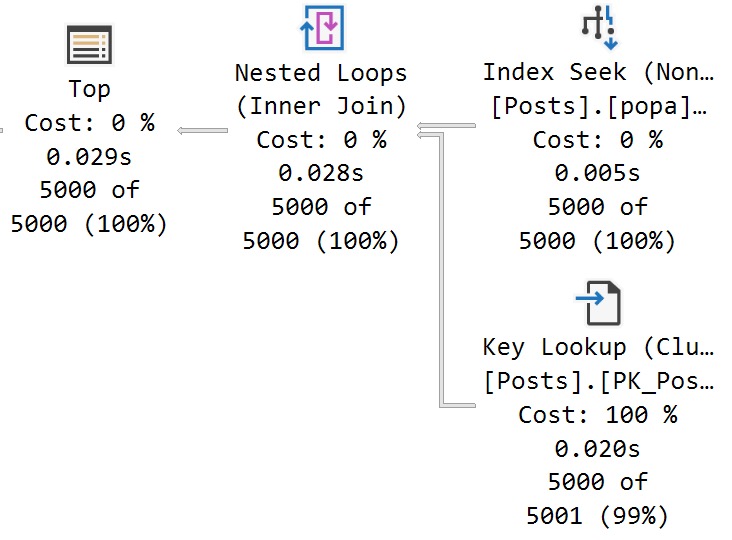
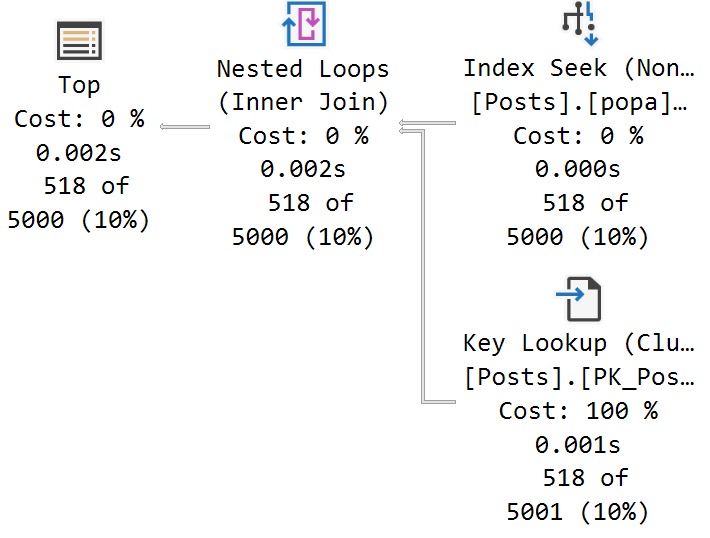
OldPlan
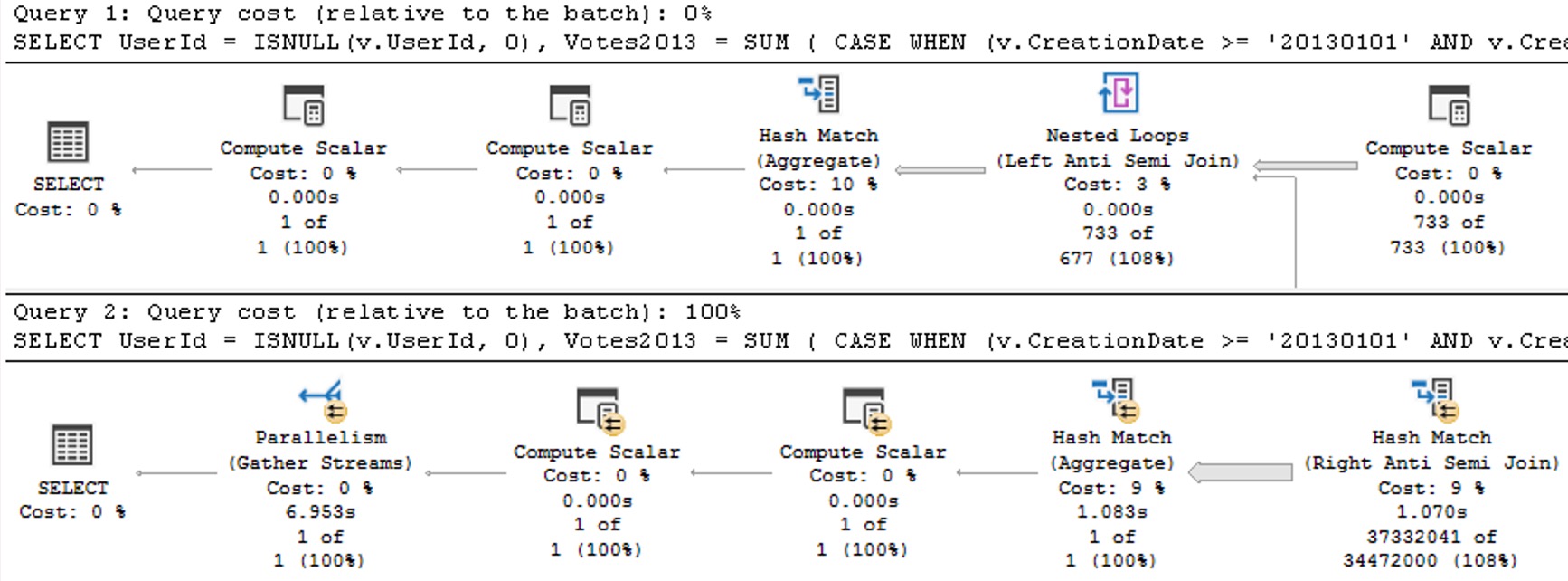
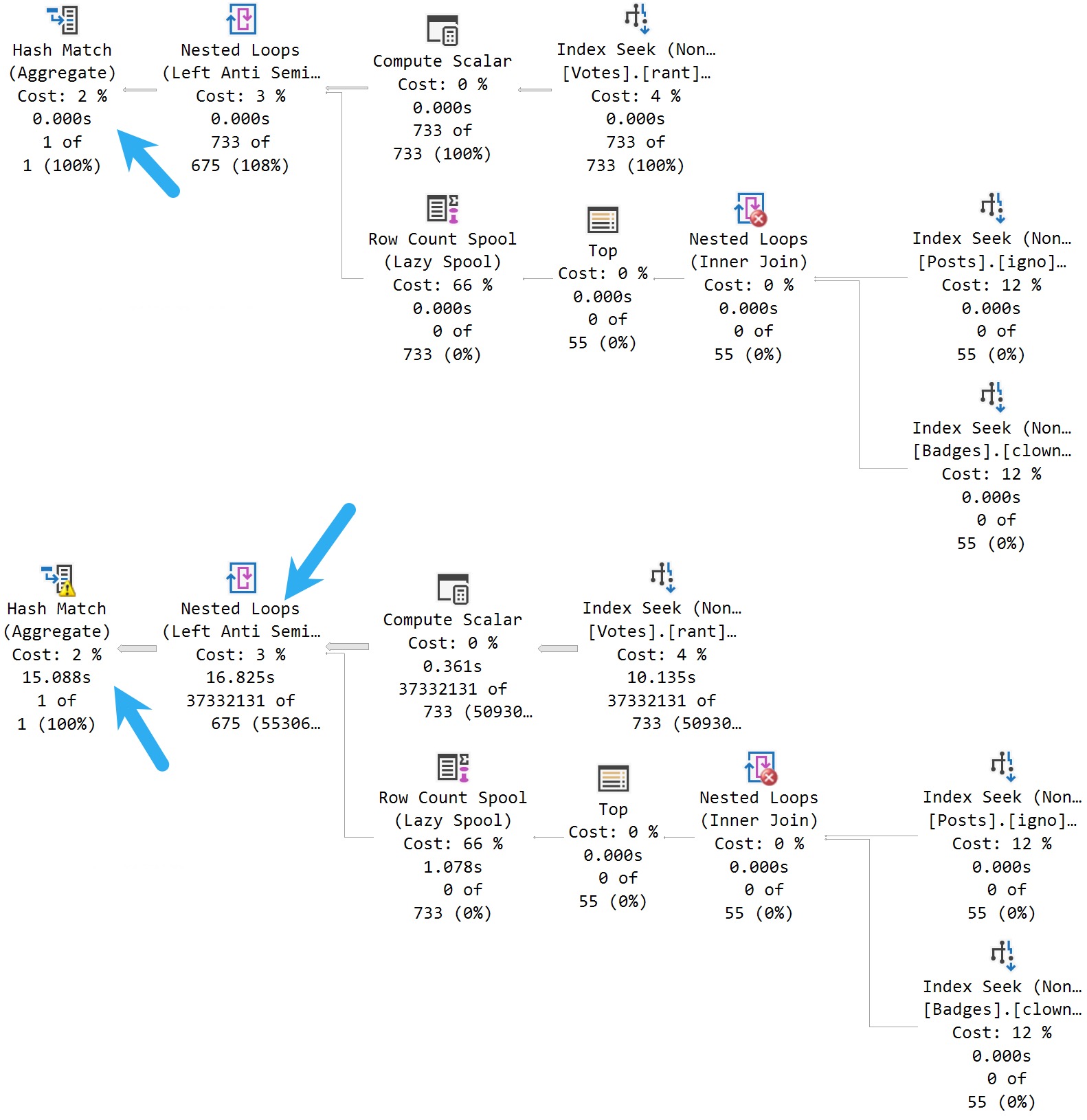
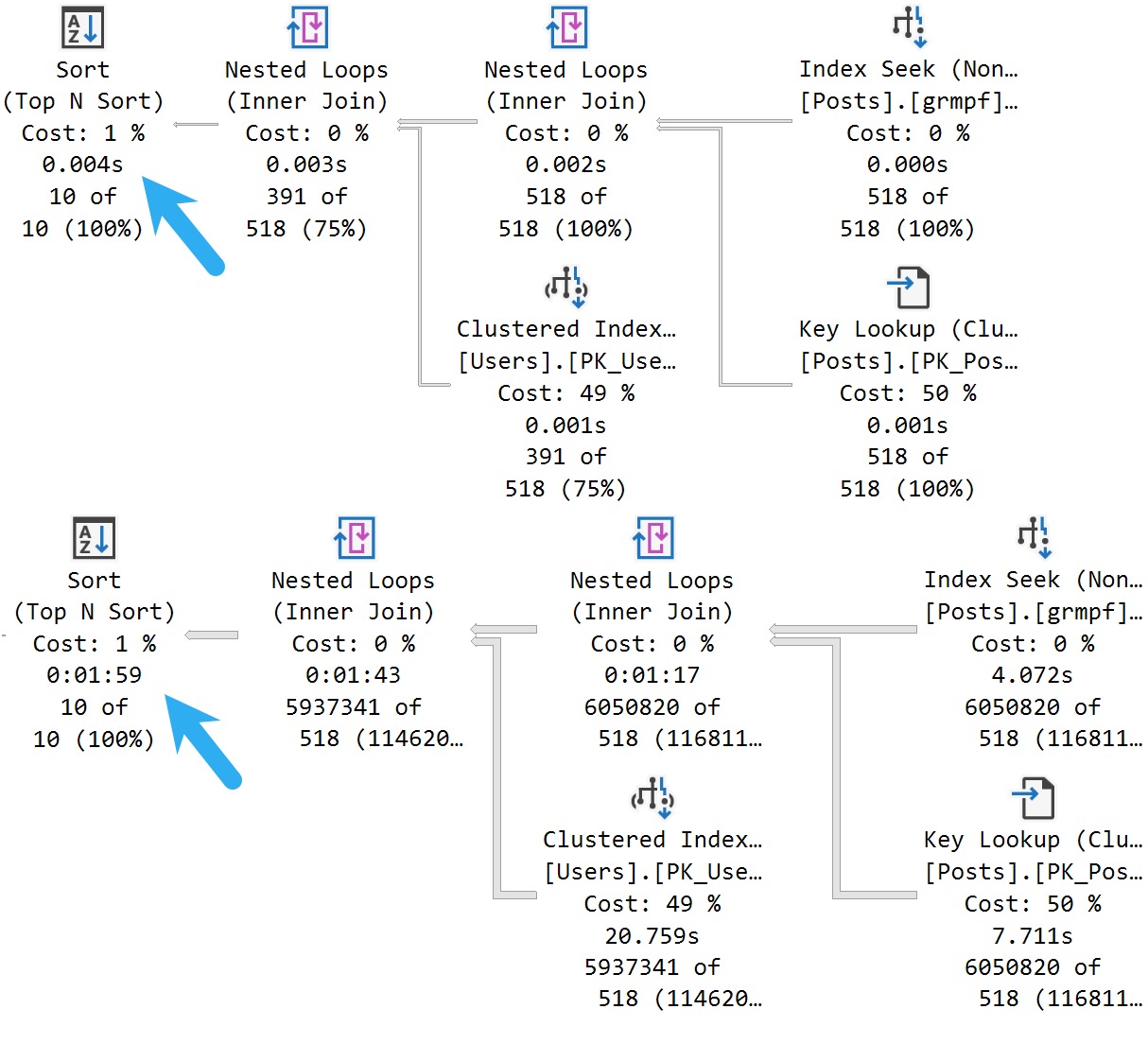
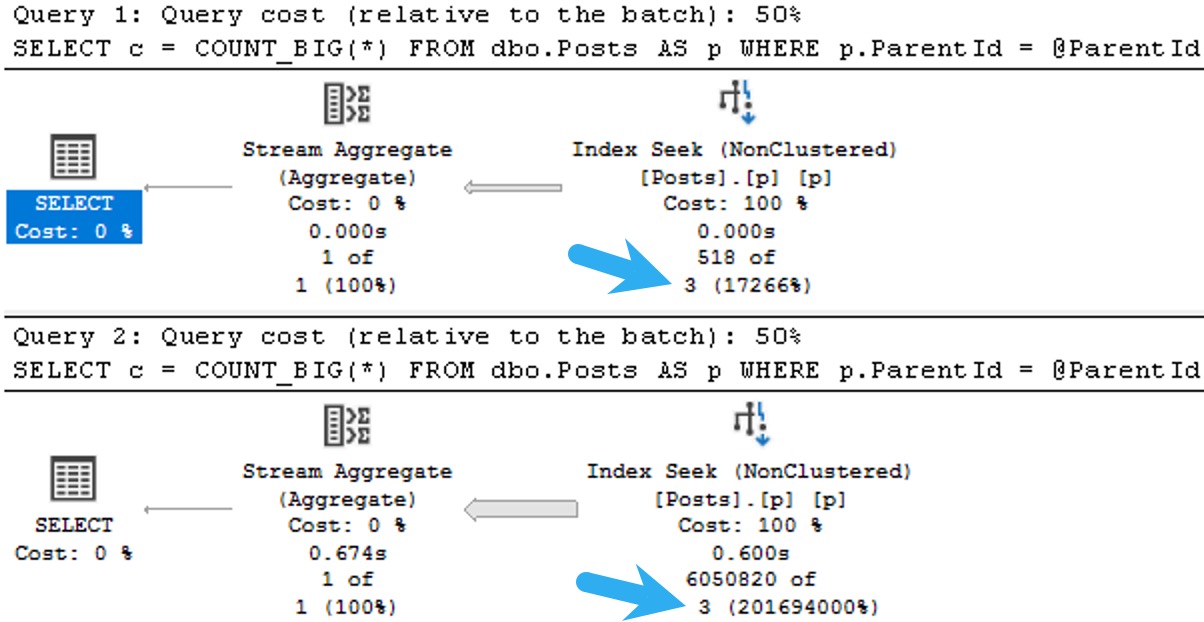
The plans for the two executions have the same poor cardinality estimate. In this case, since we have an ideal index and there’s no real complexity, there’s no performance issue.
But you can probably guess (at least for the second query) how being off by 201,694,000% might cause issues in queries that ask a bit more of the optimizer.
The point here is that both queries get the same incorrect estimate of 3 rows. If you add a recompile hint, or execute the same code using sp_executesql, the first query will get a histogram cardinality estimate, and the second query will reuse it.
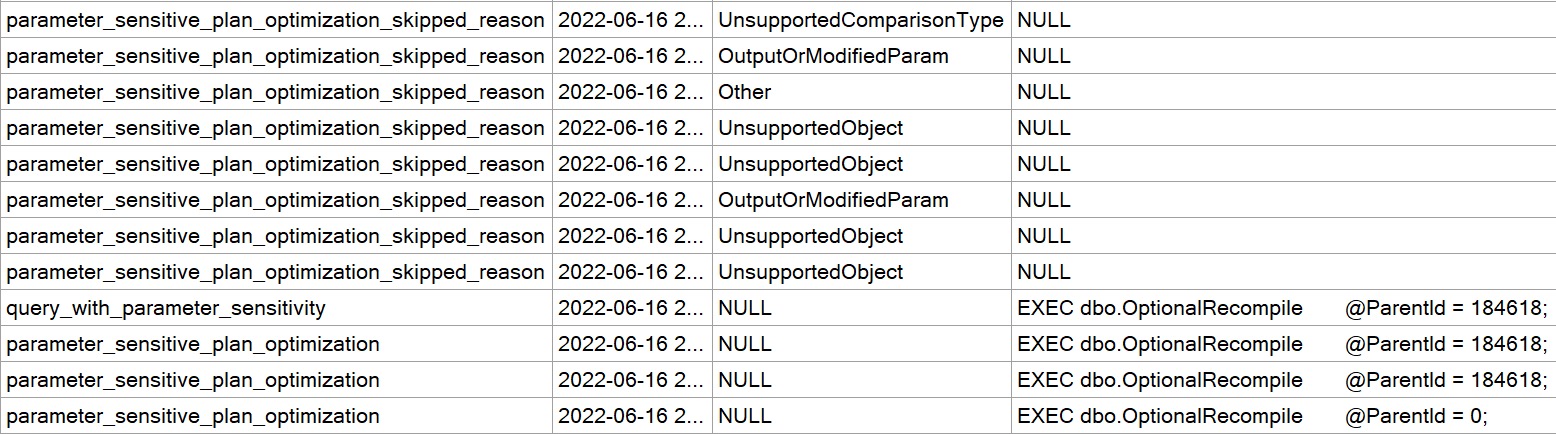
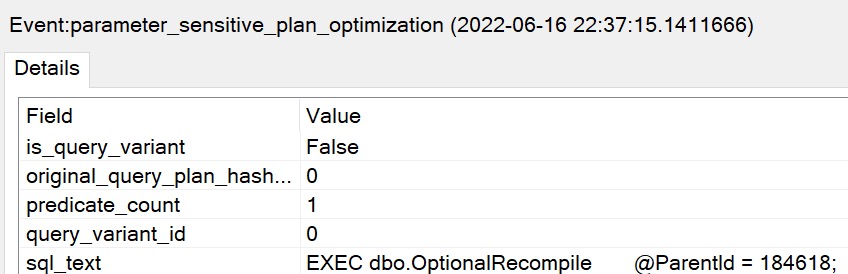
Given the historical behavior of sp_prepare, I was a little surprised that the Parameter Sensitive Plan (PSP) optimization available in SQL Server 2022 kicked in.
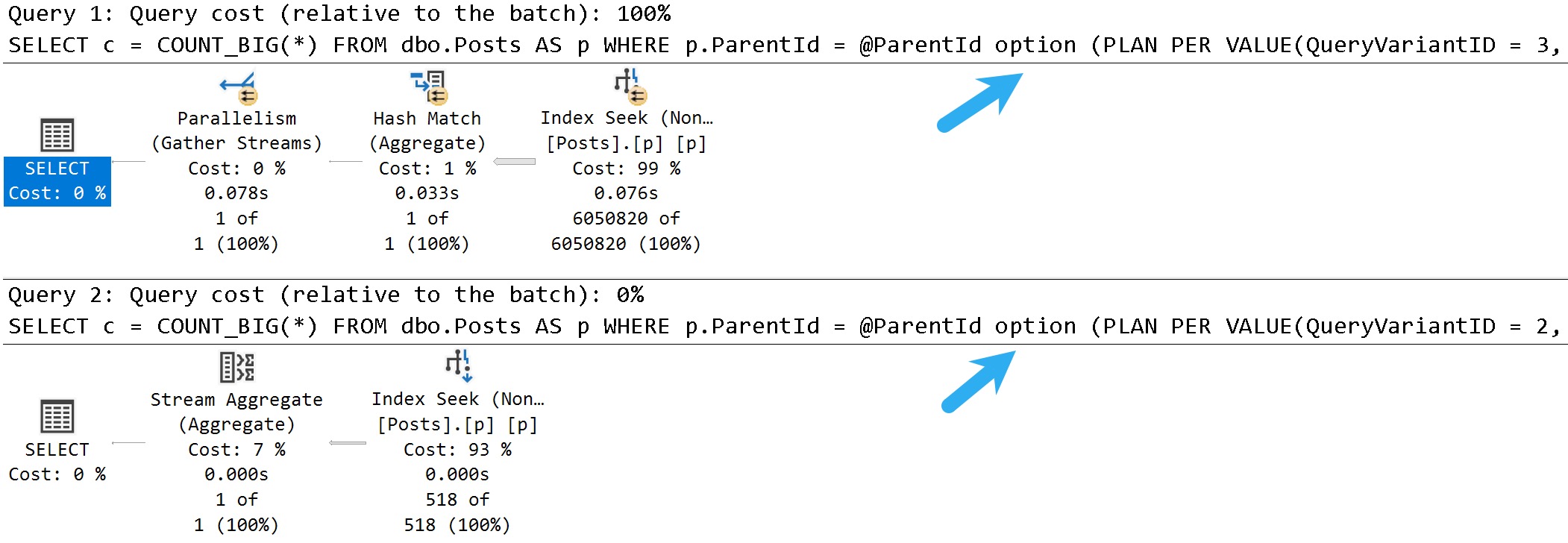
NewDifferent
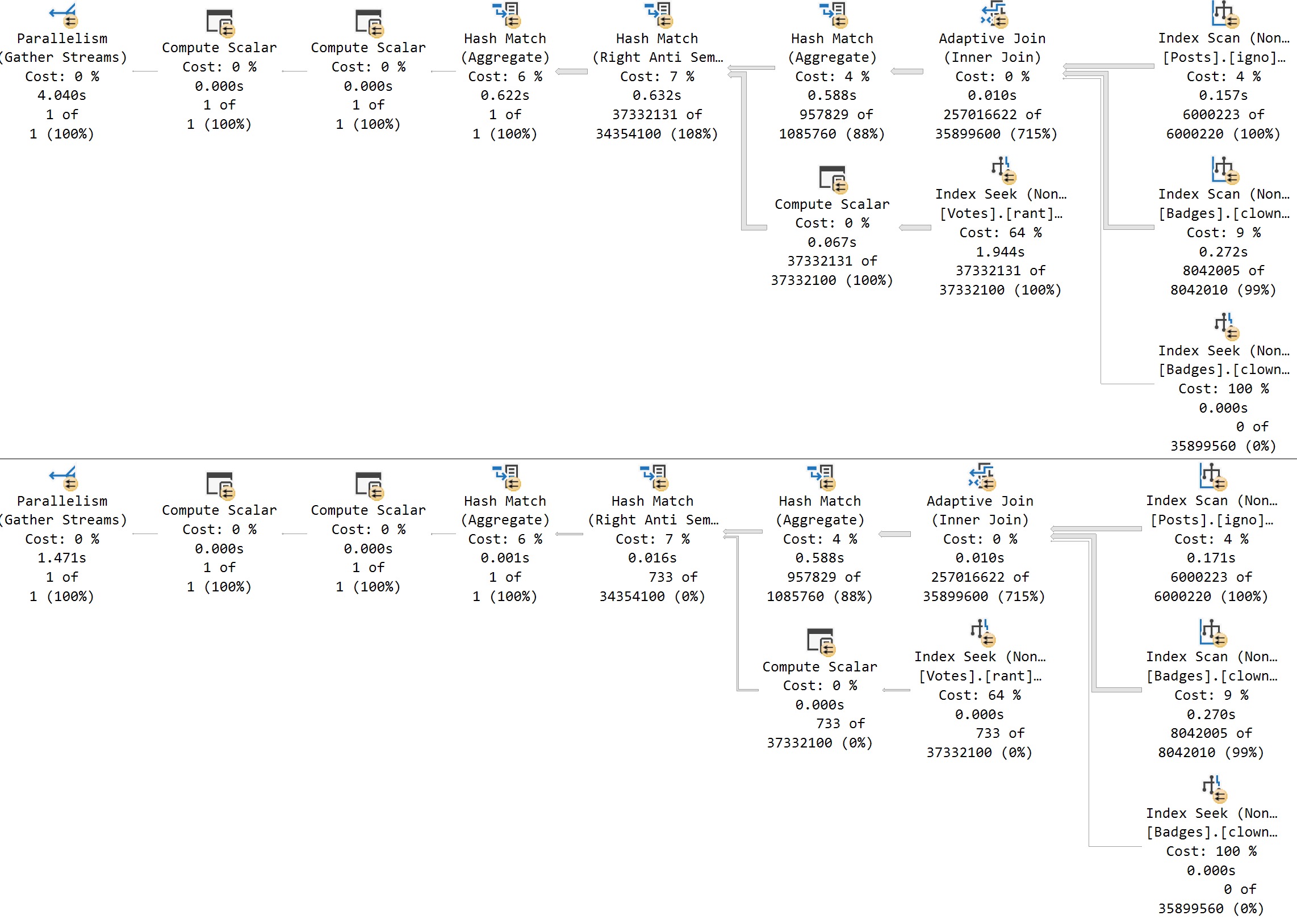
If we change the database compatibility level to 160, the plans change a bit.
ALTER DATABASE StackOverflow2013 SET COMPATIBILITY_LEVEL = 160;
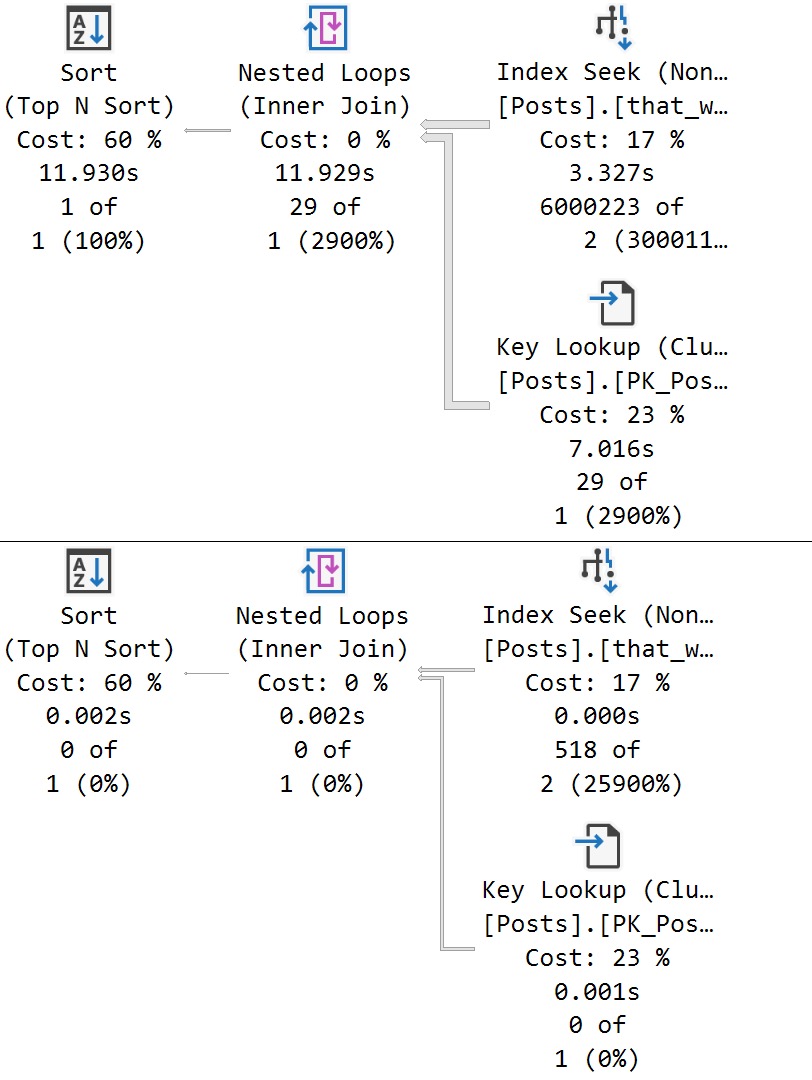
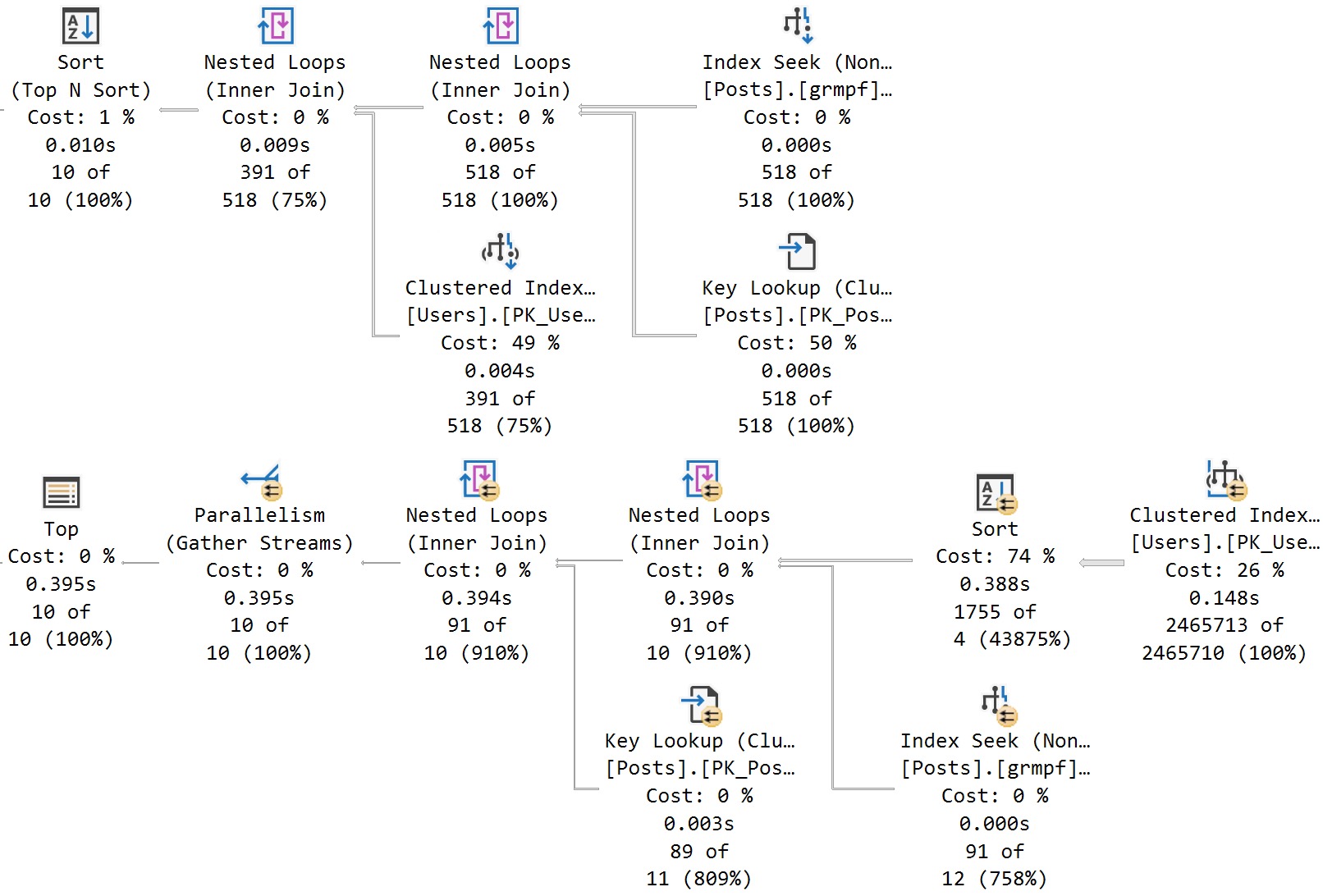
Now we see two different plans without a recompilation, as well as the plan per value option text at the end of the queries, indicating the PSP optimization kicked in.
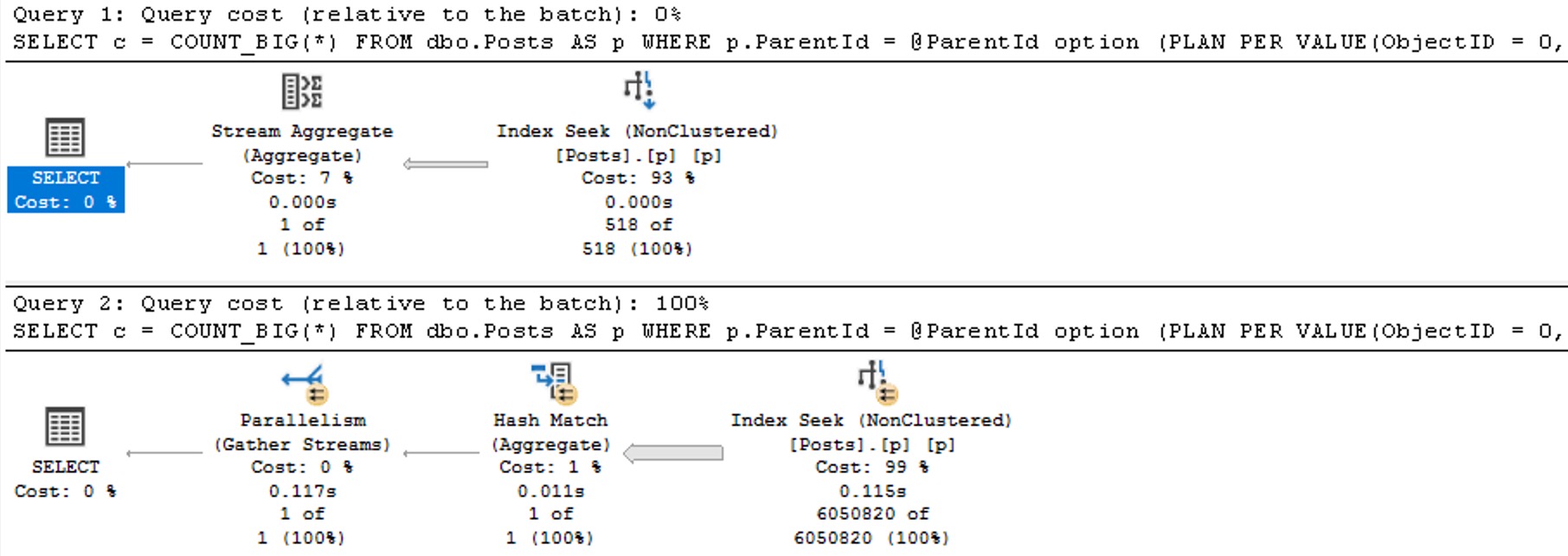
The differences here are fairly obvious, but…
- Each plan gets accurate cardinality
- The second plan goes parallel to make processing ~6 million rows faster
- Different aggregates more suited to the amount of data in play are chosen (the hash match aggregate is eligible for batch mode)
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.