Pssst!
If you landed here from Brent’s weekly links, use this link to get my training for 90% off.
The access is for life, but this coupon code isn’t! Get it while it lasts.
Discount applies at checkout, and you have to purchase everything for it to apply.
A Persistent Frustration
SQL Server comes with some great features for tuning queries:
- Computed Columns
- Filtered Indexes
- Indexed Views
But there’s an interoperability issue when you try to use things together. You can’t create a filtered index with the filter definition on a computed column, nor can you create a filtered index on an indexed view.
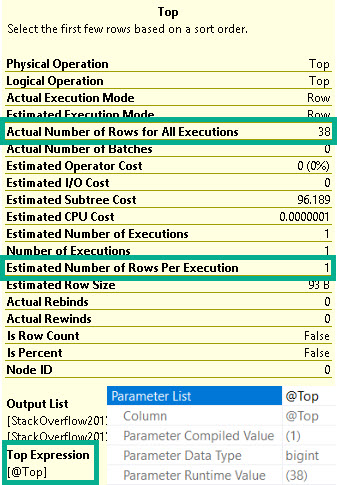
If you find yourself backed into a corner, you may need to consider using an indexed view without any aggregation (which is the normal use-case).
Empty Tables
If we try to do something like this, we’ll get an error.
DROP TABLE IF EXISTS dbo.indexed_view;
GO
CREATE TABLE dbo.indexed_view
(
id int PRIMARY KEY,
notfizzbuzz AS (id * 2)
);
GO
CREATE INDEX n
ON dbo.indexed_view (notfizzbuzz)
WHERE notfizzbuzz = 0;
GO
Yes, I’m putting the error message here for SEO bucks.
Msg 10609, Level 16, State 1, Line 19 Filtered index 'nfb' cannot be created on table 'dbo.indexed_view' because the column 'notfizzbuzz' in the filter expression is a computed column. Rewrite the filter expression so that it does not include this column.
An Indexed View Doesn’t Help
If we run this to create an indexed view on top of our base table, we still can’t create a filtered index, but there’s a different error message.
CREATE OR ALTER VIEW dbo.computed_column
WITH SCHEMABINDING
AS
SELECT
iv.id,
iv.notfizzbuzz
FROM dbo.indexed_view AS iv;
GO
CREATE UNIQUE CLUSTERED INDEX c
ON dbo.computed_column(id);
CREATE INDEX nfb
ON dbo.computed_column(notfizzbuzz)
WHERE notfizzbuzz = 0;
Msg 10610, Level 16, State 1, Line 37 Filtered index 'nfb' cannot be created on object 'dbo.computed_column' because it is not a user table. Filtered indexes are only supported on tables. If you are trying to create a filtered index on a view, consider creating an indexed view with the filter expression incorporated in the view definition.
But what a thoughtful error message it is! Thanks, whomever wrote that.
Still Needs Help
We can create this indexed view just fine.
CREATE OR ALTER VIEW dbo.computed_column
WITH SCHEMABINDING
AS
SELECT
iv.id,
iv.notfizzbuzz
FROM dbo.indexed_view AS iv
WHERE iv.notfizzbuzz = 0;
GO
CREATE UNIQUE CLUSTERED INDEX c
ON dbo.computed_column(id);
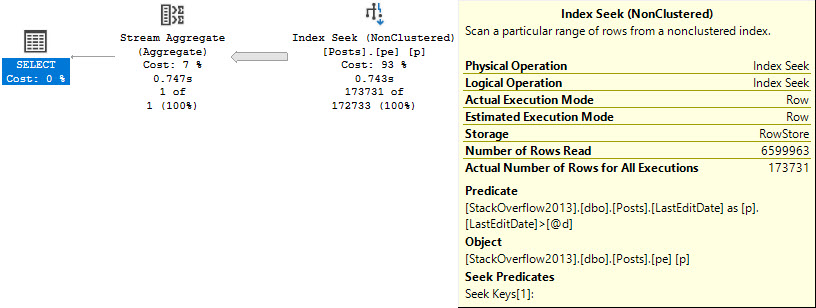
But if we try to select from it, the view is expanded.
SELECT
cc.id,
cc.notfizzbuzz
FROM dbo.computed_column AS cc
WHERE cc.notfizzbuzz = 0;

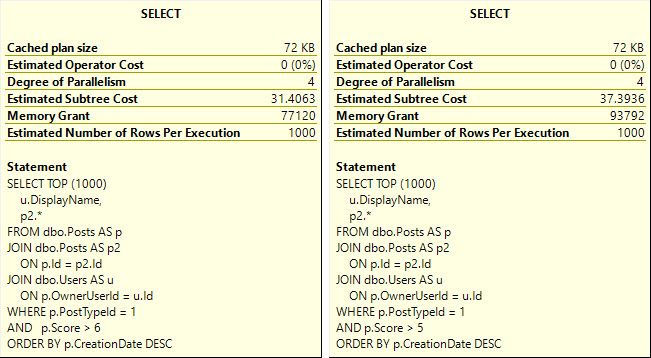
The issue here is the simple parameterization that is attempted with the trivial plan.
If we run the query like this, and look at the end of the output, we’ll see a message at the bottom that our query is safe for auto (simple) parameterization. This may still happen even if the plan doesn’t remain trivial (more detail at the link above!)
DBCC FREEPROCCACHE;
GO
DBCC TRACEON(8607, 3604);
GO
SELECT
cc.id,
cc.notfizzbuzz
FROM dbo.computed_column AS cc
WHERE cc.notfizzbuzz = 0;
DBCC TRACEOFF(8607, 3604);
GO
********************
** Query marked as Cachable
** Query marked as Safe for Auto-Param
********************
Making It Work
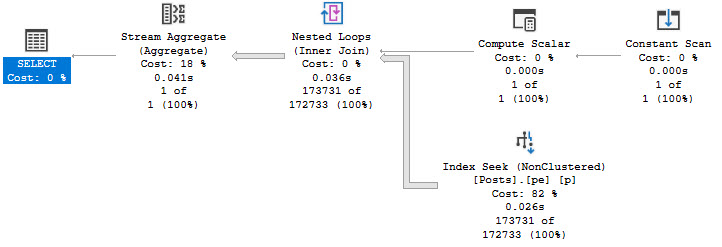
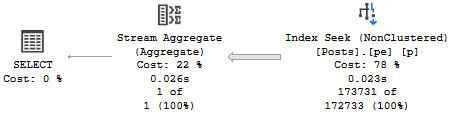
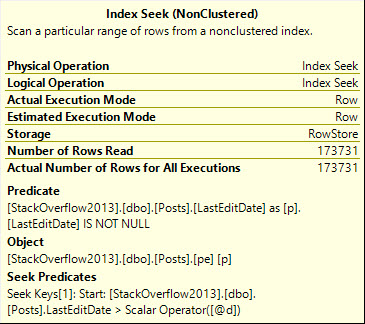
The two ways we can run this query to get the indexed view to be used are like so:
SELECT
cc.id,
cc.notfizzbuzz
FROM dbo.computed_column AS cc WITH(NOEXPAND)
WHERE cc.notfizzbuzz = 0;
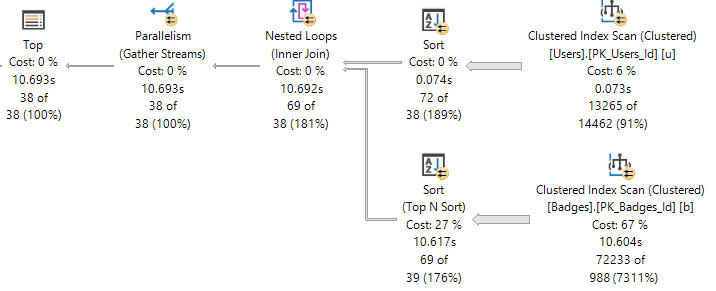
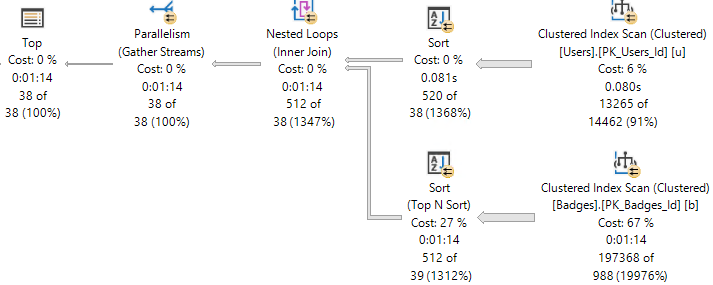
SELECT
cc.id,
cc.notfizzbuzz
FROM dbo.computed_column AS cc
WHERE cc.notfizzbuzz = 0
AND 1 = (SELECT 1);

A Closer Look
If we put those two queries through the ringer, we’ll still see auto (simple) parameterization from the first query:
DBCC FREEPROCCACHE;
GO
DBCC TRACEON(8607, 3604);
GO
SELECT
cc.id,
cc.notfizzbuzz
FROM dbo.computed_column AS cc WITH(NOEXPAND)
WHERE cc.notfizzbuzz = 0;
GO
DBCC TRACEOFF(8607, 3604);
GO
********************
** Query marked as Cachable
** Query marked as Safe for Auto-Param
********************
DBCC FREEPROCCACHE;
GO
DBCC TRACEON(8607, 3604);
GO
SELECT
cc.id,
cc.notfizzbuzz
FROM dbo.computed_column AS cc
WHERE cc.notfizzbuzz = 0
AND 1 = (SELECT 1);
GO
DBCC TRACEOFF(8607, 3604);
GO
********************
** Query marked as Cachable
********************
It’s goofy, but it’s worth noting. Anyway, if I had to pick one of these methods to get the plan I want, it would be the NOEXPAND version.
Using that hint is the only thing that will allow for statistics to get generated on indexed views.
In case you’re wondering, marking the computed column as PERSISTED doesn’t change the outcome for any of these issues.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.