Jammed, Not Jellied
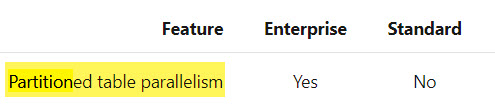
UPDATE 2021-04-14: Microsoft has updated the documentation for all 2016+ versions of SQL Server to indicate that parallelism is available for partitioned tables in non-Enterprise versions.
There’s been a note in the documentation since SQL Server 2016 SP1 brought certain Programmability Features™ to Standard Edition with regard to parallelism differences between Standard and Enterprise Edition.
For the sake of completeness, I did all my testing across both Standard and Developer Editions of SQL Server and couldn’t detect a meaningful difference.
Additionally, documentation about Parallel Query Execution Strategy for Partitioned Objects doesn’t note any differences in strategy between the two Editions.
There may be scenarios outside of the ones I tested that do show a difference, but, uh. I didn’t test those.
Obviously.
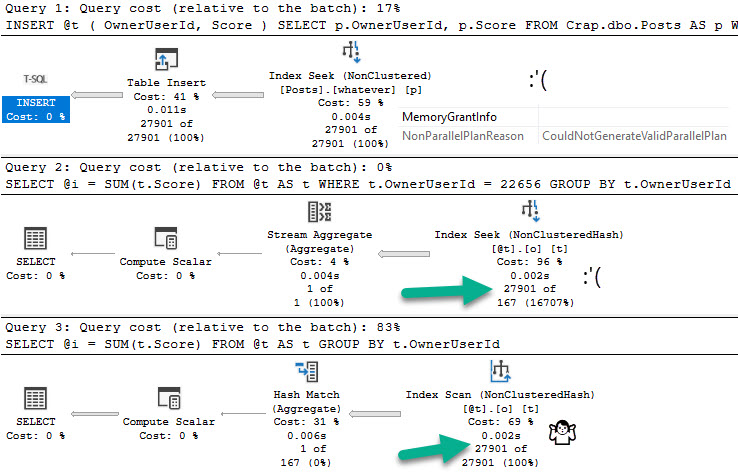
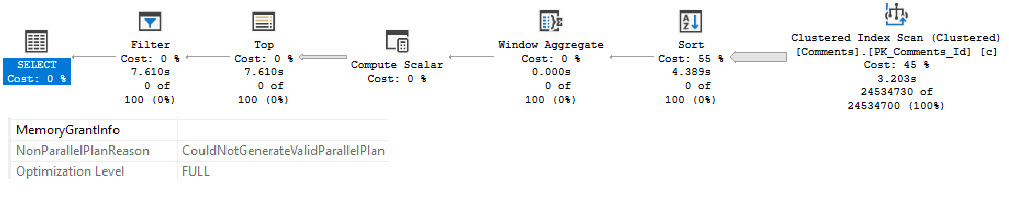
Every table is going to test this query at different DOPs.
SELECT
DATEPART(YEAR, vp.CreationDate) AS VoteYear,
DATEPART(MONTH, vp.CreationDate) AS VoteMonth,
COUNT_BIG(DISTINCT vp.PostId) AS UniquePostVotes,
SUM(vp.BountyAmount) AS TotalBounties
FROM dbo.Votes_p AS vp
GROUP BY
DATEPART(YEAR, vp.CreationDate),
DATEPART(MONTH, vp.CreationDate);
Two Partitions
Here’s the setup:
CREATE PARTITION FUNCTION VoteYear2013_pf(DATETIME)
AS RANGE RIGHT FOR VALUES
(
'20130101'
);
GO
CREATE PARTITION SCHEME VoteYear2013_ps
AS PARTITION VoteYear2013_pf
ALL TO ([PRIMARY]);
DROP TABLE IF EXISTS dbo.Votes2013_p;
CREATE TABLE dbo.Votes2013_p
(
Id int NOT NULL,
PostId int NOT NULL,
UserId int NULL,
BountyAmount int NULL,
VoteTypeId int NOT NULL,
CreationDate datetime NOT NULL,
CONSTRAINT PK_Votes2013_p_Id
PRIMARY KEY CLUSTERED (CreationDate, Id)
) ON VoteYear2013_ps(CreationDate);
INSERT dbo.Votes2013_p WITH(TABLOCK)
(Id, PostId, UserId, BountyAmount, VoteTypeId, CreationDate)
SELECT v.Id,
v.PostId,
v.UserId,
v.BountyAmount,
v.VoteTypeId,
v.CreationDate
FROM dbo.Votes AS v;
The data split looks like this:

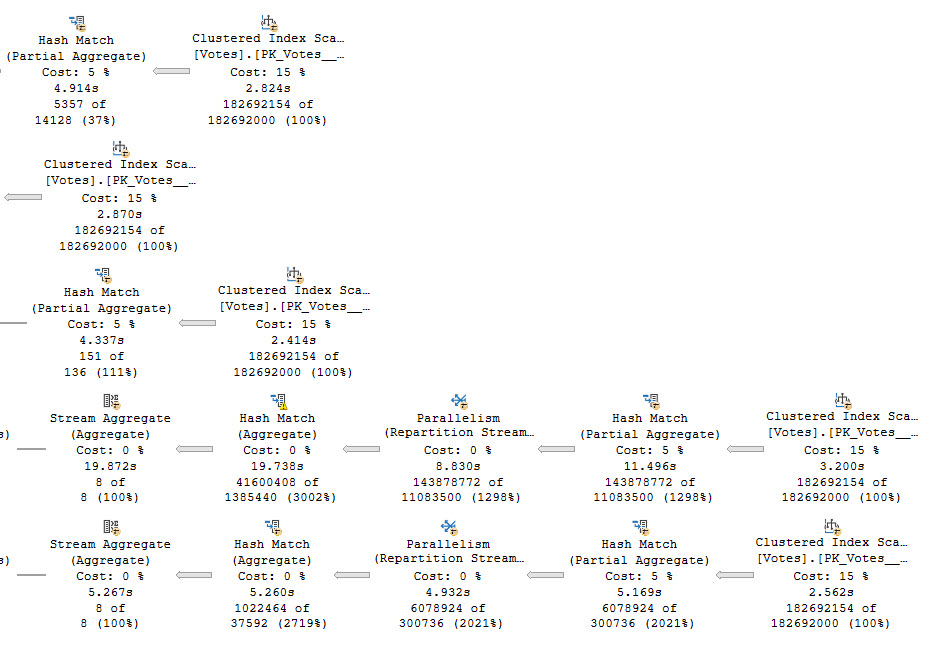
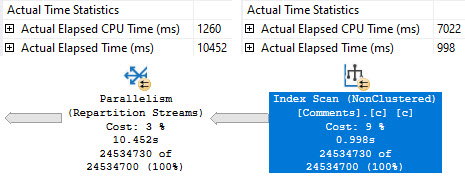
Running our test query at DOP 4, there are slight differences in counts across threads, but slight timing differences can explain that.
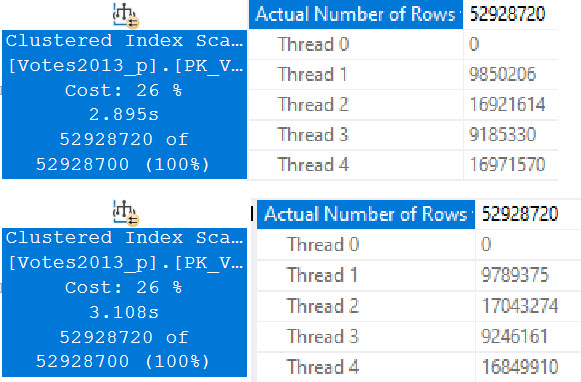
Standard Edition is on top, Developer Edition is at the bottom. There is a ~200ms difference here, but averaged out over multiple runs things end up pretty dead even.
Even looking at the row counts per thread, the distribution is close across both versions. I think it’s decently clear that the four threads work cooperatively across both partitions. A similar pattern continues at higher DOPs, too. I tested 8 and 16, and while there were slight differences in row counts per thread, there was a similar distribution pattern as at DOP 4.
Eight Partitions
Using a different partitioning function:
CREATE PARTITION FUNCTION VoteYear_pf(DATETIME)
AS RANGE RIGHT FOR VALUES
(
'20080101',
'20090101',
'20100101',
'20110101',
'20120101',
'20130101',
'20140101'
);
GO
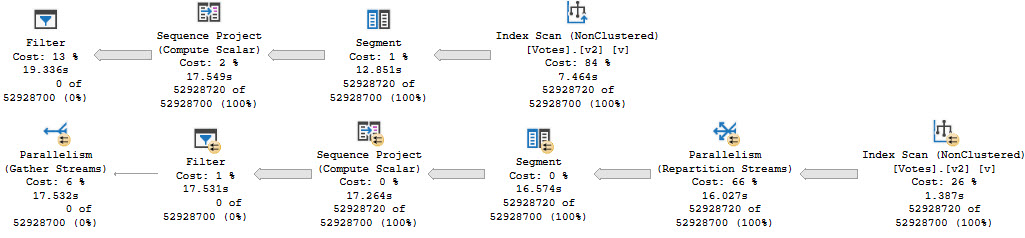
We’re going to jump right to testing the query at DOP 8.
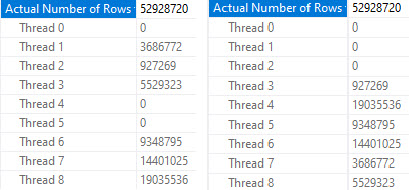
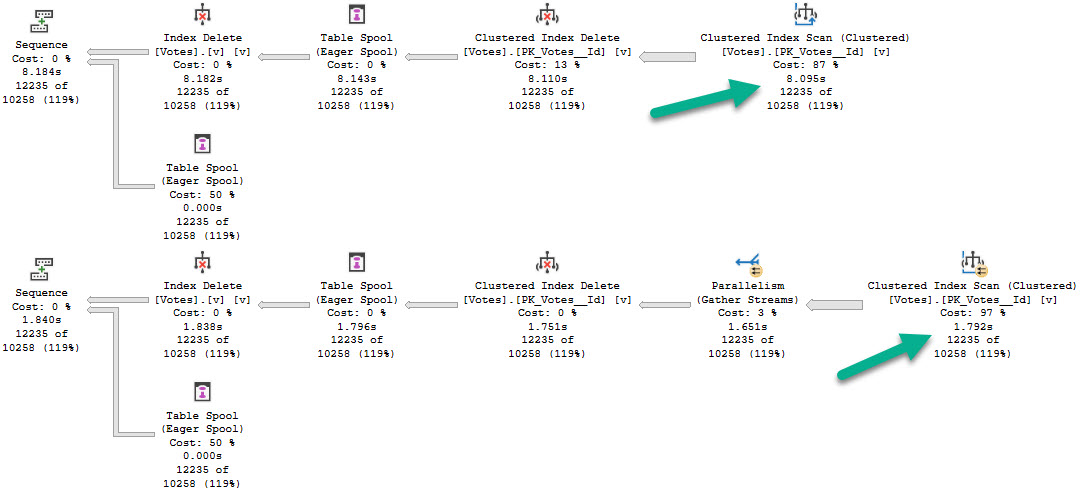
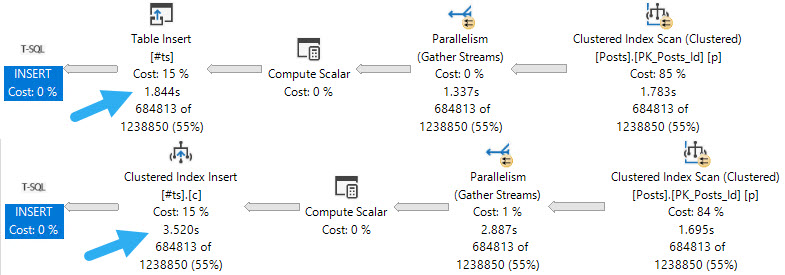
Again, different threads end up getting assigned the work, but row counts match exactly across threads that did get work, and those numbers line up exactly to the number of rows in each partition.
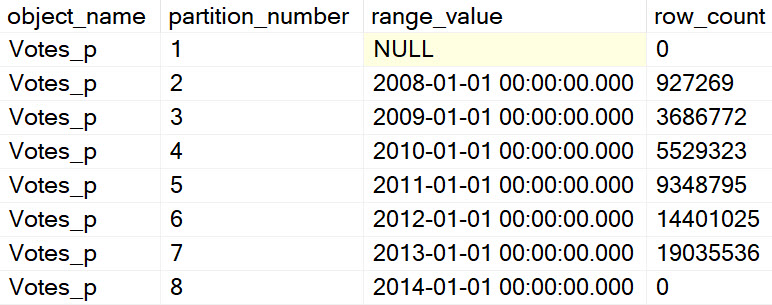
In both queries, two threads scanned a partition with no rows and did no work. Each thread that did scan a partition scanned only one partition.
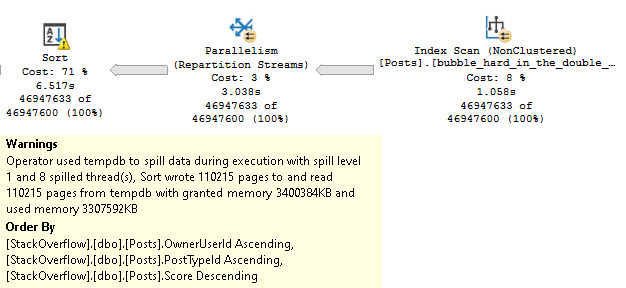
At DOP 16, the skew gets a bit worse, because now four threads do no work.
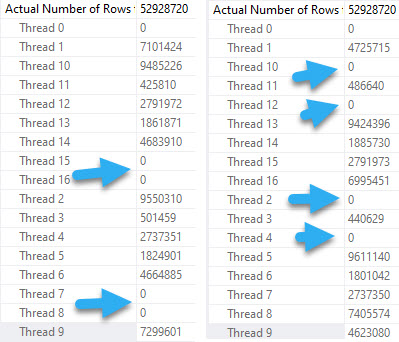
The remaining threads all seem to split the populated partitions evenly, though again there are slight timing differences that result in different row counts per thread, but it’s pretty clear that there is cooperation here.
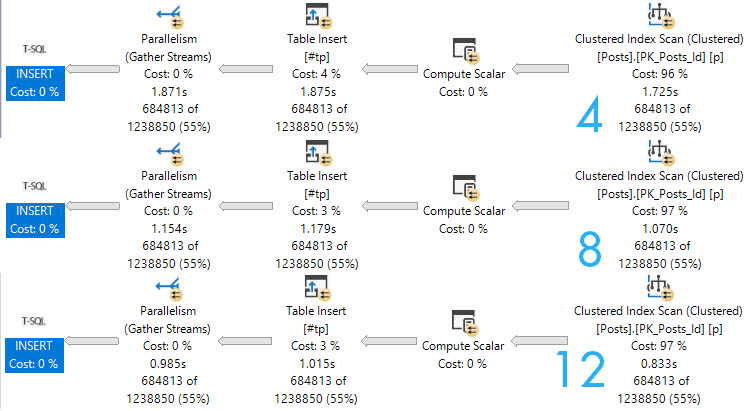
At DOP 4, things get a bit more interesting.
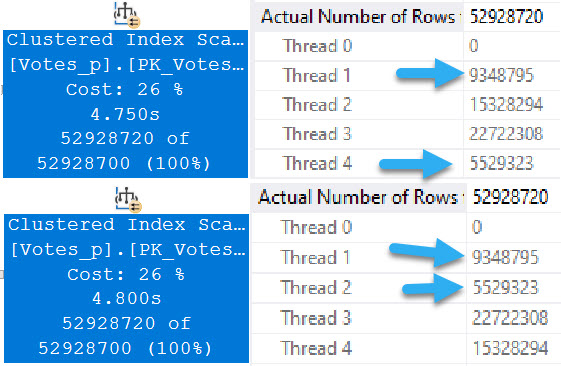
In both queries, two threads scan exactly one partition.
The rows with arrows pointing at them represent numbers that exactly match the number of rows in a single partition.
The remaining threads have exactly the same row counts across versions.
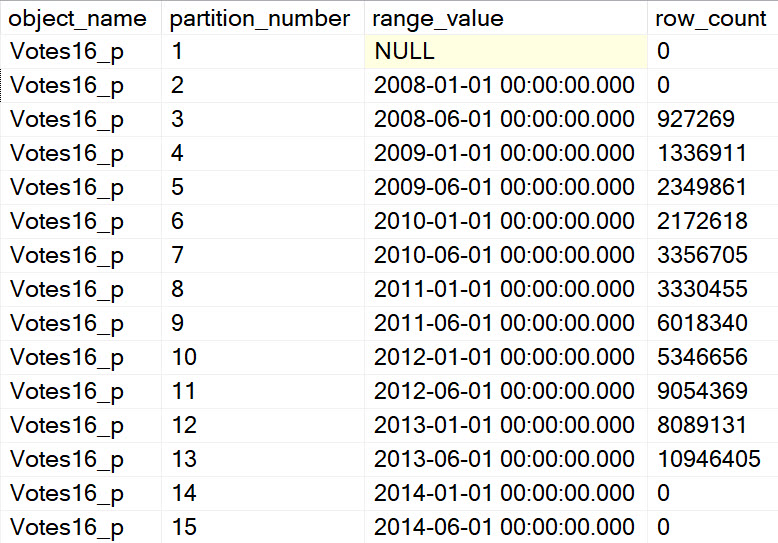
Fifteen Partitions
The results here show mostly the same pattern as before, so I’m keeping it short.
CREATE PARTITION FUNCTION VoteYear16_pf(DATETIME)
AS RANGE RIGHT FOR VALUES
(
'20080101',
'20080601',
'20090101',
'20090601',
'20100101',
'20100601',
'20110101',
'20110601',
'20120101',
'20120601',
'20130101',
'20130601',
'20140101',
'20140601'
);
GO
At DOP 4 and 8, threads work cooperatively across partitions. Where things get interesting (sort of) is at DOP 16.
The four empty partitions here result in 4 threads doing no work in Developer/Enterprise Edition, and 5 threads doing no work in Standard Edition.
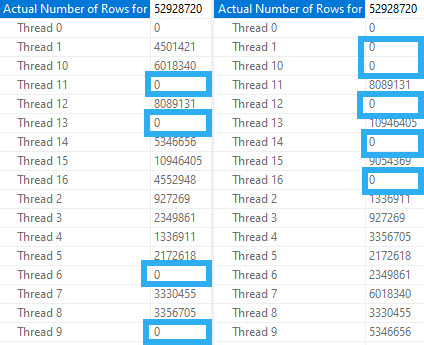
At first, I thought this might be a crack in the case, so I did things a little bit differently. In a dozen or so runs, the 5 empty threads only seemed to occur in the Standard Edition query. Sometimes it did, sometimes it didn’t. But it was at least something.
Fifteen Partitions, Mostly Empty
I used the same setup as above, but this time I didn’t fully load data from Votes in:
INSERT dbo.Votes16e_p WITH(TABLOCK)
(Id, PostId, UserId, BountyAmount, VoteTypeId, CreationDate)
SELECT v.Id,
v.PostId,
v.UserId,
v.BountyAmount,
v.VoteTypeId,
v.CreationDate
FROM dbo.Votes AS v
WHERE v.CreationDate >= '20130101';
And… Scene!
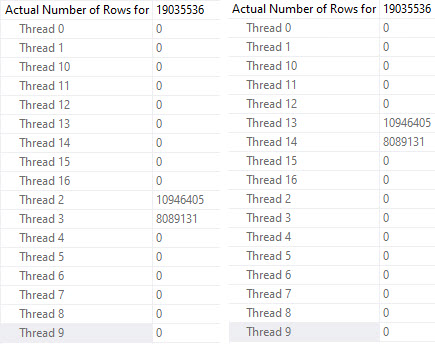
That’s Just Great
Aside from one case where an extra thread got zero rows in Standard Edition, the behavior across the board looks the same.
Most of the behavior is sensible, but cases where multiple threads get no rows and don’t move on to other partitions is a little troubling.
Not that anyone has partitioning set up right anyway.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.